ZigZag LibraryThis is yet another ZigZag library.
🔵 Key Features
1. Lightning-Fast Performance : Optimized code ensures minimal lag and swift chart updates.
2. Real-Time Swing Detection : No more waiting for swings to finalize! This library continuously identifies the latest swing formation.
3. Amplitude-Aware : Discover significant swings earlier, even if they haven't reached the standard bar length.
4. Customizable Visualization : Draw ZigZag on-demand using polylines for a tailored analysis experience.
Stay tuned for more features as this library is being continuously enhanced. For the latest updates, please refer to the release information.
🔵 API
// Import this library. Remember to check the latest version of this library and replace the version number below.
import algotraderdev/zigzag/1 as zz
// Initialize the ZigZag instance.
var zz.ZigZag zig = zz.ZigZag.new().init(
zz.Settings.new(
swingLen = 5,
lineColor = color.blue,
lineStyle = line.style_solid,
lineWidth = 1))
// Analyze the ZigZag using the latest bar's data.
zig.tick()
// Draw the ZigZag.
if barstate.islast
zig.draw()
W-m-pattern

TimeSeriesRecurrencePlotLibrary "TimeSeriesRecurrencePlot"
In descriptive statistics and chaos theory, a recurrence plot (RP) is a plot showing, for each moment i i in time, the times at which the state of a dynamical system returns to the previous state at `i`, i.e., when the phase space trajectory visits roughly the same area in the phase space as at time `j`.
```
A recurrence plot (RP) is a graphical representation used in the analysis of time series data and dynamical systems. It visualizes recurring states or events over time by transforming the original time series into a binary matrix, where each element represents whether two consecutive points are above or below a specified threshold. The resulting Recurrence Plot Matrix reveals patterns, structures, and correlations within the data while providing insights into underlying mechanisms of complex systems.
```
~starling7b
___
Reference:
en.wikipedia.org
github.com
github.com
github.com
github.com
juliadynamics.github.io
distance_matrix(series1, series2, max_freq, norm)
Generate distance matrix between two series.
Parameters:
series1 (float) : Source series 1.
series2 (float) : Source series 2.
max_freq (int) : Maximum frequency to inpect or the size of the generated matrix.
norm (string) : Norm of the distance metric, default=`euclidean`, options=`euclidean`, `manhattan`, `max`.
Returns: Matrix with distance values.
method normalize_distance(M)
Normalizes a matrix within its Min-Max range.
Namespace types: matrix
Parameters:
M (matrix) : Source matrix.
Returns: Normalized matrix.
method threshold(M, threshold)
Updates the matrix with the condition `M(i,j) > threshold ? 1 : 0`.
Namespace types: matrix
Parameters:
M (matrix) : Source matrix.
threshold (float)
Returns: Cross matrix.
rolling_window(a, b, sample_size)
An experimental alternative method to plot a recurrence_plot.
Parameters:
a (array) : Array with data.
b (array) : Array with data.
sample_size (int)
Returns: Recurrence_plot matrix.

lib_retracement_patternsLibrary "lib_retracement_patterns"
types and functions for XABCD pattern detection and plotting
method set_tolerances(this, tolerance_Bmin, tolerance_Bmax, tolerance_Cmin, tolerance_Cmax, tolerance_Dmin, tolerance_Dmax)
sets tolerances for B, C and D retracements. This creates another Pattern instance that is set as tolerances field on the original and will be used for detection instead of the original ratios.
Namespace types: Pattern
create_config(pattern_line_args, pattern_point_args, name_label_args, retracement_line_args, retracement_label_args, line_args_Dtarget, line_args_completion, line_args_tp1, line_args_tp2, line_args_sl, label_args_completion, label_args_tp1, label_args_tp2, label_args_sl, label_terminal, label_terminal_up_char, label_terminal_down_char, color_bull, color_bear, color_muted, fill_opacity, draw_point_labels, draw_retracements, draw_target_range, draw_levels, hide_shorter_if_shared_legs_greater_than_max, hide_engulfed_pattern, hide_engulfed_pattern_of_same_type, hide_longer_pattern_with_same_X, mute_previous_pattern_when_next_overlaps, keep_failed_patterns)
method direction(this)
Namespace types: Match
method length(this)
return the length of this pattern, determined by the distance between X and D point
Namespace types: Match
method height(this)
return the height of this pattern, determined by the distance between the biggest distance between A/C and X/D
Namespace types: Match
method is_forming(this)
returns true if not complete, not expired and not invalidated
Namespace types: Match
method tostring(this)
return a string representation of all Matches in this map
Namespace types: Match
method tostring(this)
Namespace types: map
remove_complete_and_expired(this)
method add(this, item)
Namespace types: map
method is_engulfed_by(this, other)
checks if this Match is engulfed by the other
Namespace types: Match
method update(tracking_matches, zigzag, patterns, max_age_idx, detect_dir, pattern_minlen, pattern_maxlen, max_sub_waves, max_shared_legs, max_XB_BD_ratio, debug_log)
checks this map of tracking Matches if any of them was completed or invalidated in
Namespace types: map
method mute(this, mute_color, mute_fill_color)
mute this pattern by making it all one color (lines and labels, for pattern fill there's another)
Namespace types: Match
method mute(this, mute_color, mute_fill_color)
mute all patterns in this map by making it all one color (lines and labels, for pattern fill there's another)
Namespace types: map
method hide(this)
hide this pattern by muting it with a transparent color
Namespace types: Match
method reset_styles(this)
reset the style of a muted or hidden match back to the preset configuration
Namespace types: Match
method delete(this)
remove the plot of this Match from the chart
Namespace types: Match
method delete(this)
remove all the plots of the Matches in this map from the chart
Namespace types: map
method draw(this)
draw this Match on the chart
Namespace types: Match
method draw(this, config, all_patterns, debug_log)
draw all Matches in this map, considering all other patterns for engulfing and overlapping
Namespace types: map
method check_hide_or_mute(this, all, config, debug_log)
checks if this pattern needs to be hidden or muted based on other plotted patterns and given configuration
Namespace types: Match
method add_if(id, item, condition)
convenience function to add a search pattern to a list, only if given condition (input.bool) is true
Namespace types: Pattern
Pattern
type to hold retracement ratios and tolerances for this pattern, as well as targets for trades
Config
allows control of pattern plotting shape and colors, as well as settings for hiding overlapped patterns etc.
Match
holds all information on a Pattern and a successful match in the chart. Includes XABCD pivot points as well as all Line and Label objects to draw it
SimilarityMeasuresLibrary "SimilarityMeasures"
Similarity measures are statistical methods used to quantify the distance between different data sets
or strings. There are various types of similarity measures, including those that compare:
- data points (SSD, Euclidean, Manhattan, Minkowski, Chebyshev, Correlation, Cosine, Camberra, MAE, MSE, Lorentzian, Intersection, Penrose Shape, Meehl),
- strings (Edit(Levenshtein), Lee, Hamming, Jaro),
- probability distributions (Mahalanobis, Fidelity, Bhattacharyya, Hellinger),
- sets (Kumar Hassebrook, Jaccard, Sorensen, Chi Square).
---
These measures are used in various fields such as data analysis, machine learning, and pattern recognition. They
help to compare and analyze similarities and differences between different data sets or strings, which
can be useful for making predictions, classifications, and decisions.
---
References:
en.wikipedia.org
cran.r-project.org
numerics.mathdotnet.com
github.com
github.com
github.com
Encyclopedia of Distances, doi.org
ssd(p, q)
Sum of squared difference for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the squared euclidean distance.
euclidean(p, q)
Euclidean distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of distance that calculates the straight-line (or Euclidean).
manhattan(p, q)
Manhattan distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of absolute differences between both points.
minkowski(p, q, p_value)
Minkowsky Distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
p_value (float) : `float` P value, default=1.0(1: manhatan, 2: euclidean), does not support chebychev.
Returns: Measure of similarity in the normed vector space.
chebyshev(p, q)
Chebyshev distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
correlation(p, q)
Correlation distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Measure of maximum absolute difference.
cosine(p, q)
Cosine distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Cosine distance between vectors `p` and `q`.
---
angiogenesis.dkfz.de
camberra(p, q)
Camberra distance for N dimensions.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Weighted measure of absolute differences between both points.
mae(p, q)
Mean absolute error is a normalized version of the sum of absolute difference (manhattan).
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean absolute error of vectors `p` and `q`.
mse(p, q)
Mean squared error is a normalized version of the sum of squared difference.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Mean squared error of vectors `p` and `q`.
lorentzian(p, q)
Lorentzian distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Lorentzian distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
intersection(p, q)
Intersection distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Intersection distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
penrose(p, q)
Penrose Shape distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Penrose shape distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
meehl(p, q)
Meehl distance between provided vectors.
Parameters:
p (float ) : `array` Vector with first numeric distribution.
q (float ) : `array` Vector with second numeric distribution.
Returns: Meehl distance of vectors `p` and `q`.
---
angiogenesis.dkfz.de
edit(x, y)
Edit (aka Levenshtein) distance for indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Number of deletions, insertions, or substitutions required to transform source string into target string.
---
generated description:
The Edit distance is a measure of similarity used to compare two strings. It is defined as the minimum number of
operations (insertions, deletions, or substitutions) required to transform one string into another. The operations
are performed on the characters of the strings, and the cost of each operation depends on the specific algorithm
used.
The Edit distance is widely used in various applications such as spell checking, text similarity, and machine
translation. It can also be used for other purposes like finding the closest match between two strings or
identifying the common prefixes or suffixes between them.
---
github.com
www.red-gate.com
planetcalc.com
lee(x, y, dsize)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
dsize (int) : `int` Dictionary size.
Returns: Distance between two strings by accounting for dictionary size.
---
www.johndcook.com
hamming(x, y)
Distance between two indexed strings of equal length.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Length of different components on both sequences.
---
en.wikipedia.org
jaro(x, y)
Distance between two indexed strings.
Parameters:
x (int ) : `array` Indexed array.
y (int ) : `array` Indexed array.
Returns: Measure of two strings' similarity: the higher the value, the more similar the strings are.
The score is normalized such that `0` equates to no similarities and `1` is an exact match.
---
rosettacode.org
mahalanobis(p, q, VI)
Mahalanobis distance between two vectors with population inverse covariance matrix.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
VI (matrix) : `matrix` Inverse of the covariance matrix.
Returns: The mahalanobis distance between vectors `p` and `q`.
---
people.revoledu.com
stat.ethz.ch
docs.scipy.org
fidelity(p, q)
Fidelity distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya Coefficient between vectors `p` and `q`.
---
en.wikipedia.org
bhattacharyya(p, q)
Bhattacharyya distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Bhattacharyya distance between vectors `p` and `q`.
---
en.wikipedia.org
hellinger(p, q)
Hellinger distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The hellinger distance between vectors `p` and `q`.
---
en.wikipedia.org
jamesmccaffrey.wordpress.com
kumar_hassebrook(p, q)
Kumar Hassebrook distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Kumar Hassebrook distance between vectors `p` and `q`.
---
github.com
jaccard(p, q)
Jaccard distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Jaccard distance between vectors `p` and `q`.
---
github.com
sorensen(p, q)
Sorensen distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
Returns: The Sorensen distance between vectors `p` and `q`.
---
people.revoledu.com
chi_square(p, q, eps)
Chi Square distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Chi Square distance between vectors `p` and `q`.
---
uw.pressbooks.pub
stats.stackexchange.com
www.itl.nist.gov
kulczynsky(p, q, eps)
Kulczynsky distance between provided vectors.
Parameters:
p (float ) : `array` 1D Vector.
q (float ) : `array` 1D Vector.
eps (float)
Returns: The Kulczynsky distance between vectors `p` and `q`.
---
github.com
FunctionPatternFrequencyLibrary "FunctionPatternFrequency"
Counts the word or integer number pattern frequency on a array.
reference:
rosettacode.org
count(pattern)
counts the number a pattern is repeated.
Parameters:
pattern : : array : array with patterns to be counted.
Returns:
array : list of unique patterns.
array : list of counters per pattern.
usage:
count(array.from('a','b','c','a','b','a'))
count(pattern)
counts the number a pattern is repeated.
Parameters:
pattern : : array : array with patterns to be counted.
Returns:
array : list of unique patterns.
array : list of counters per pattern.
usage:
count(array.from(1,2,3,1,2,1))
FunctionDynamicTimeWarpingLibrary "FunctionDynamicTimeWarping"
"In time series analysis, dynamic time warping (DTW) is an algorithm for
measuring similarity between two temporal sequences, which may vary in
speed. For instance, similarities in walking could be detected using DTW,
even if one person was walking faster than the other, or if there were
accelerations and decelerations during the course of an observation.
DTW has been applied to temporal sequences of video, audio, and graphics
data — indeed, any data that can be turned into a linear sequence can be
analyzed with DTW. A well-known application has been automatic speech
recognition, to cope with different speaking speeds. Other applications
include speaker recognition and online signature recognition.
It can also be used in partial shape matching applications."
"Dynamic time warping is used in finance and econometrics to assess the
quality of the prediction versus real-world data."
~~ wikipedia
reference:
en.wikipedia.org
towardsdatascience.com
github.com
cost_matrix(a, b, w)
Dynamic Time Warping procedure.
Parameters:
a : array, data series.
b : array, data series.
w : int , minimum window size.
Returns: matrix optimum match matrix.
traceback(M)
perform a backtrace on the cost matrix and retrieve optimal paths and cost between arrays.
Parameters:
M : matrix, cost matrix.
Returns: tuple:
array aligned 1st array of indices.
array aligned 2nd array of indices.
float final cost.
reference:
github.com
report(a, b, w)
report ordered arrays, cost and cost matrix.
Parameters:
a : array, data series.
b : array, data series.
w : int , minimum window size.
Returns: string report.
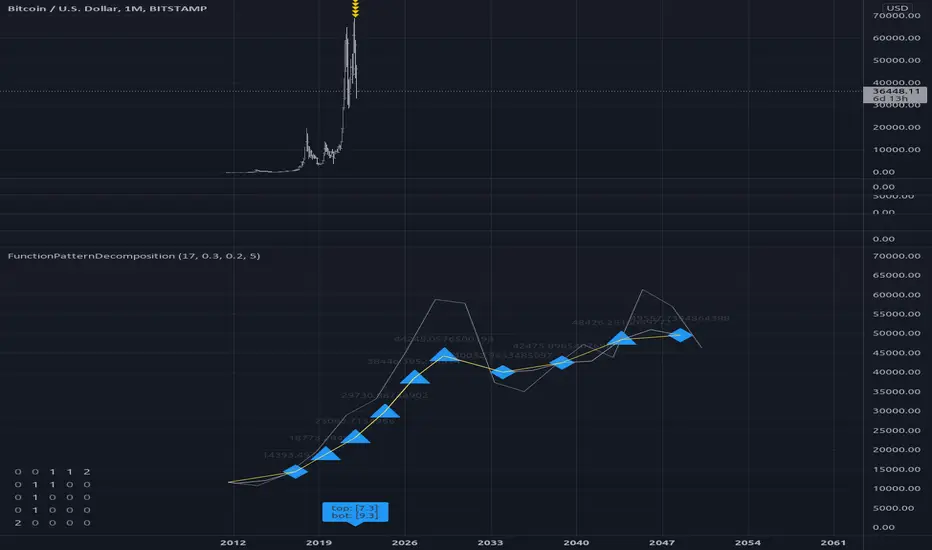
FunctionPatternDecompositionLibrary "FunctionPatternDecomposition"
Methods for decomposing price into common grid/matrix patterns.
series_to_array(source, length) Helper for converting series to array.
Parameters:
source : float, data series.
length : int, size.
Returns: float array.
smooth_data_2d(data, rate) Smooth data sample into 2d points.
Parameters:
data : float array, source data.
rate : float, default=0.25, the rate of smoothness to apply.
Returns: tuple with 2 float arrays.
thin_points(data_x, data_y, rate) Thin the number of points.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
rate : float, default=2.0, minimum threshold rate of sample stdev to accept points.
Returns: tuple with 2 float arrays.
extract_point_direction(data_x, data_y) Extract the direction each point faces.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
Returns: float array.
find_corners(data_x, data_y, rate) ...
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
rate : float, minimum threshold rate of data y stdev.
Returns: tuple with 2 float arrays.
grid_coordinates(data_x, data_y, m_size) transforms points data to a constrained sized matrix format.
Parameters:
data_x : float array, points x value.
data_y : float array, points y value.
m_size : int, default=10, size of the matrix.
Returns: flat 2d pseudo matrix.