OPEN-SOURCE SCRIPT
Variety MA Cluster Filter Crosses [Loxx]
What is a Cluster Filter?
One of the approaches to determining a useful signal (trend) in stream data. Small filtering (smoothing) tests applied to market quotes demonstrate the potential for creating non-lagging digital filters (indicators) that are not redrawn on the last bars.
Standard Approach
This approach is based on classical time series smoothing methods. There are lots of articles devoted to this subject both on this and other websites. The results are also classical:
1. The changes in trends are displayed with latency;
2. Better indicator (digital filter) response achieved at the expense of smoothing quality decrease;
3. Attempts to implement non-lagging indicators lead to redrawing on the last samples (bars).
And whereas traders have learned to cope with these things using persistence of economic processes and other tricks, this would be unacceptable in evaluating real-time experimental data, e.g. when testing aerostructures.
The Main Problem
It is a known fact that the majority of trading systems stop performing with the course of time, and that the indicators are only indicative over certain intervals. This can easily be explained: market quotes are not stationary. The definition of a stationary process is available in Wikipedia:
A stationary process is a stochastic process whose joint probability distribution does not change when shifted in time.
Judging by this definition, methods of analysis of stationary time series are not applicable in technical analysis. And this is understandable. A skillful market-maker entering the market will mess up all the calculations we may have made prior to that with regard to parameters of a known series of market quotes.
Even though this seems obvious, a lot of indicators are based on the theory of stationary time series analysis. Examples of such indicators are moving averages and their modifications. However, there are some attempts to create adaptive indicators. They are supposed to take into account non-stationarity of market quotes to some extent, yet they do not seem to work wonders. The attempts to "punish" the market-maker using the currently known methods of analysis of non-stationary series (wavelets, empirical modes and others) are not successful either. It looks like a certain key factor is constantly being ignored or unidentified.
The main reason for this is that the methods used are not designed for working with stream data. All (or almost all) of them were developed for analysis of the already known or, speaking in terms of technical analysis, historical data. These methods are convenient, e.g., in geophysics: you feel the earthquake, get a seismogram and then analyze it for few months. In other words, these methods are appropriate where uncertainties arising at the ends of a time series in the course of filtering affect the end result.
When analyzing experimental stream data or market quotes, we are focused on the most recent data received, rather than history. These are data that cannot be dealt with using classical algorithms.
Cluster Filter
Cluster filter is a set of digital filters approximating the initial sequence. Cluster filters should not be confused with cluster indicators.
Cluster filters are convenient when analyzing non-stationary time series in real time, in other words, stream data. It means that these filters are of principal interest not for smoothing the already known time series values, but for getting the most probable smoothed values of the new data received in real time.
Unlike various decomposition methods or simply filters of desired frequency, cluster filters create a composition or a fan of probable values of initial series which are further analyzed for approximation of the initial sequence. The input sequence acts more as a reference than the target of the analysis. The main analysis concerns values calculated by a set of filters after processing the data received.

In the general case, every filter included in the cluster has its own individual characteristics and is not related to others in any way. These filters are sometimes customized for the analysis of a stationary time series of their own which describes individual properties of the initial non-stationary time series. In the simplest case, if the initial non-stationary series changes its parameters, the filters "switch" over. Thus, a cluster filter tracks real time changes in characteristics.
Cluster Filter Design Procedure
Any cluster filter can be designed in three steps:
1. The first step is usually the most difficult one but this is where probabilistic models of stream data received are formed. The number of these models can be arbitrary large. They are not always related to physical processes that affect the approximable data. The more precisely models describe the approximable sequence, the higher the probability to get a non-lagging cluster filter.
2. At the second step, one or more digital filters are created for each model. The most general condition for joining filters together in a cluster is that they belong to the models describing the approximable sequence.
3. So, we can have one or more filters in a cluster. Consequently, with each new sample we have the sample value and one or more filter values. Thus, with each sample we have a vector or artificial noise made up of several (minimum two) values. All we need to do now is to select the most appropriate value.
An Example of a Simple Cluster Filter
For illustration, we will implement a simple cluster filter corresponding to the above diagram, using market quotes as input sequence. You can simply use closing prices of any time frame.
1. Model description. We will proceed on the assumption that:
The aproximate sequence is non-stationary, i.e. its characteristics tend to change with the course of time.
The closing price of a bar is not the actual bar price. In other words, the registered closing price of a bar is one of the noise movements, like other price movements on that bar.
The actual price or the actual value of the approximable sequence is between the closing price of the current bar and the closing price of the previous bar.
The approximable sequence tends to maintain its direction. That is, if it was growing on the previous bar, it will tend to keep on growing on the current bar.
2. Selecting digital filters. For the sake of simplicity, we take two filters:
The first filter will be a variety filter calculated based on the last closing prices using the slow period. I believe this fits well in the third assumption we specified for our model.
Since we have a non-stationary filter, we will try to also use an additional filter that will hopefully facilitate to identify changes in characteristics of the time series. I've chosen a variety filter using the fast period.
3. Selecting the appropriate value for the cluster filter.
So, with each new sample we will have the sample value (closing price), as well as the value of MA and fast filter. The closing price will be ignored according to the second assumption specified for our model. Further, we select the МА or ЕМА value based on the last assumption, i.e. maintaining trend direction:
For an uptrend, i.e. CF(i-1)>CF(i-2), we select one of the following four variants:
if CF(i-1)<slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=MIN(slowfilter(i),fastfilter(i));
if CF(i-1)<slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=slowfilter(i);
if CF(i-1)>slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=fastfilter(i);
if CF(i-1)>slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i)).
For a downtrend, i.e. CF(i-1)<CF(i-2), we select one of the following four variants:
if CF(i-1)>slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i));
if CF(i-1)>slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=slowfilter(i);
if CF(i-1)<slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=fastfilter(i);
if CF(i-1)<slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=MIN(slowfilter(i),fastfilter(i)).
Where:
CF(i) – value of the cluster filter on the current bar;
CF(i-1) and CF(i-2) – values of the cluster filter on the previous bars;
slowfilter(i) – value of the slow filter
fastfilter(i) – value of the fast filter
MIN – the minimum value;
MAX – the maximum value;
What is Variety MA Cluster Filter Crosses?
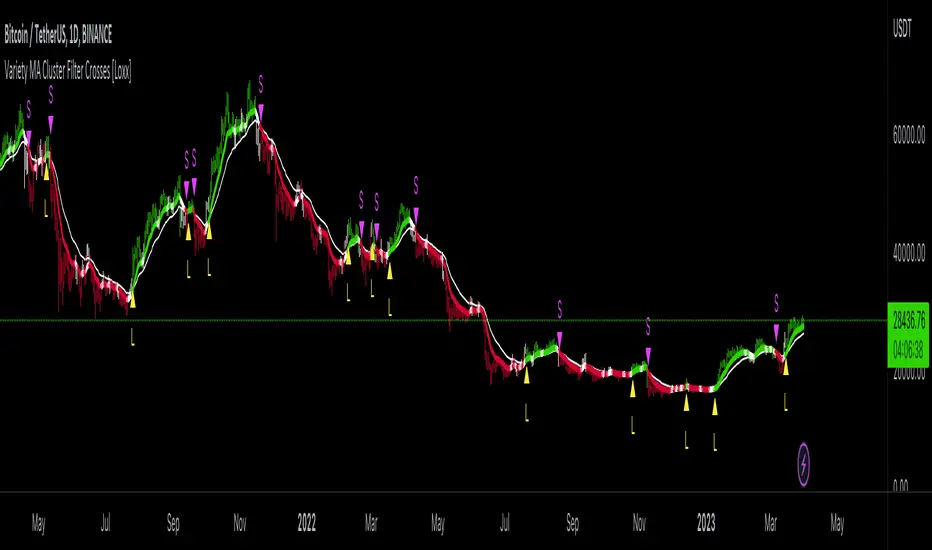
For this indicator we calculate a fast and slow filter of the same filter and then we run a cluster filter between the fast and slow filter outputs to detect areas of chop/noise. The output is the uptrend is denoted by green color, downtrend by red color, and chop/noise/no-trade zone by white color. As a trader, you'll likely want to avoid trading during areas of chop/noise so you'll want to avoid trading when the color turns white.
Extras
An example of filtered chop, see the yellow circles. The cluster filter identifies chop zones so you don't get stuck in a sideways market.

One of the approaches to determining a useful signal (trend) in stream data. Small filtering (smoothing) tests applied to market quotes demonstrate the potential for creating non-lagging digital filters (indicators) that are not redrawn on the last bars.
Standard Approach
This approach is based on classical time series smoothing methods. There are lots of articles devoted to this subject both on this and other websites. The results are also classical:
1. The changes in trends are displayed with latency;
2. Better indicator (digital filter) response achieved at the expense of smoothing quality decrease;
3. Attempts to implement non-lagging indicators lead to redrawing on the last samples (bars).
And whereas traders have learned to cope with these things using persistence of economic processes and other tricks, this would be unacceptable in evaluating real-time experimental data, e.g. when testing aerostructures.
The Main Problem
It is a known fact that the majority of trading systems stop performing with the course of time, and that the indicators are only indicative over certain intervals. This can easily be explained: market quotes are not stationary. The definition of a stationary process is available in Wikipedia:
A stationary process is a stochastic process whose joint probability distribution does not change when shifted in time.
Judging by this definition, methods of analysis of stationary time series are not applicable in technical analysis. And this is understandable. A skillful market-maker entering the market will mess up all the calculations we may have made prior to that with regard to parameters of a known series of market quotes.
Even though this seems obvious, a lot of indicators are based on the theory of stationary time series analysis. Examples of such indicators are moving averages and their modifications. However, there are some attempts to create adaptive indicators. They are supposed to take into account non-stationarity of market quotes to some extent, yet they do not seem to work wonders. The attempts to "punish" the market-maker using the currently known methods of analysis of non-stationary series (wavelets, empirical modes and others) are not successful either. It looks like a certain key factor is constantly being ignored or unidentified.
The main reason for this is that the methods used are not designed for working with stream data. All (or almost all) of them were developed for analysis of the already known or, speaking in terms of technical analysis, historical data. These methods are convenient, e.g., in geophysics: you feel the earthquake, get a seismogram and then analyze it for few months. In other words, these methods are appropriate where uncertainties arising at the ends of a time series in the course of filtering affect the end result.
When analyzing experimental stream data or market quotes, we are focused on the most recent data received, rather than history. These are data that cannot be dealt with using classical algorithms.
Cluster Filter
Cluster filter is a set of digital filters approximating the initial sequence. Cluster filters should not be confused with cluster indicators.
Cluster filters are convenient when analyzing non-stationary time series in real time, in other words, stream data. It means that these filters are of principal interest not for smoothing the already known time series values, but for getting the most probable smoothed values of the new data received in real time.
Unlike various decomposition methods or simply filters of desired frequency, cluster filters create a composition or a fan of probable values of initial series which are further analyzed for approximation of the initial sequence. The input sequence acts more as a reference than the target of the analysis. The main analysis concerns values calculated by a set of filters after processing the data received.
In the general case, every filter included in the cluster has its own individual characteristics and is not related to others in any way. These filters are sometimes customized for the analysis of a stationary time series of their own which describes individual properties of the initial non-stationary time series. In the simplest case, if the initial non-stationary series changes its parameters, the filters "switch" over. Thus, a cluster filter tracks real time changes in characteristics.
Cluster Filter Design Procedure
Any cluster filter can be designed in three steps:
1. The first step is usually the most difficult one but this is where probabilistic models of stream data received are formed. The number of these models can be arbitrary large. They are not always related to physical processes that affect the approximable data. The more precisely models describe the approximable sequence, the higher the probability to get a non-lagging cluster filter.
2. At the second step, one or more digital filters are created for each model. The most general condition for joining filters together in a cluster is that they belong to the models describing the approximable sequence.
3. So, we can have one or more filters in a cluster. Consequently, with each new sample we have the sample value and one or more filter values. Thus, with each sample we have a vector or artificial noise made up of several (minimum two) values. All we need to do now is to select the most appropriate value.
An Example of a Simple Cluster Filter
For illustration, we will implement a simple cluster filter corresponding to the above diagram, using market quotes as input sequence. You can simply use closing prices of any time frame.
1. Model description. We will proceed on the assumption that:
The aproximate sequence is non-stationary, i.e. its characteristics tend to change with the course of time.
The closing price of a bar is not the actual bar price. In other words, the registered closing price of a bar is one of the noise movements, like other price movements on that bar.
The actual price or the actual value of the approximable sequence is between the closing price of the current bar and the closing price of the previous bar.
The approximable sequence tends to maintain its direction. That is, if it was growing on the previous bar, it will tend to keep on growing on the current bar.
2. Selecting digital filters. For the sake of simplicity, we take two filters:
The first filter will be a variety filter calculated based on the last closing prices using the slow period. I believe this fits well in the third assumption we specified for our model.
Since we have a non-stationary filter, we will try to also use an additional filter that will hopefully facilitate to identify changes in characteristics of the time series. I've chosen a variety filter using the fast period.
3. Selecting the appropriate value for the cluster filter.
So, with each new sample we will have the sample value (closing price), as well as the value of MA and fast filter. The closing price will be ignored according to the second assumption specified for our model. Further, we select the МА or ЕМА value based on the last assumption, i.e. maintaining trend direction:
For an uptrend, i.e. CF(i-1)>CF(i-2), we select one of the following four variants:
if CF(i-1)<slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=MIN(slowfilter(i),fastfilter(i));
if CF(i-1)<slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=slowfilter(i);
if CF(i-1)>slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=fastfilter(i);
if CF(i-1)>slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i)).
For a downtrend, i.e. CF(i-1)<CF(i-2), we select one of the following four variants:
if CF(i-1)>slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=MAX(slowfilter(i),fastfilter(i));
if CF(i-1)>slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=slowfilter(i);
if CF(i-1)<slowfilter(i) and CF(i-1)>fastfilter(i), then CF(i)=fastfilter(i);
if CF(i-1)<slowfilter(i) and CF(i-1)<fastfilter(i), then CF(i)=MIN(slowfilter(i),fastfilter(i)).
Where:
CF(i) – value of the cluster filter on the current bar;
CF(i-1) and CF(i-2) – values of the cluster filter on the previous bars;
slowfilter(i) – value of the slow filter
fastfilter(i) – value of the fast filter
MIN – the minimum value;
MAX – the maximum value;
What is Variety MA Cluster Filter Crosses?
For this indicator we calculate a fast and slow filter of the same filter and then we run a cluster filter between the fast and slow filter outputs to detect areas of chop/noise. The output is the uptrend is denoted by green color, downtrend by red color, and chop/noise/no-trade zone by white color. As a trader, you'll likely want to avoid trading during areas of chop/noise so you'll want to avoid trading when the color turns white.
Extras
- Bar coloring
- Alerts
- Loxx's Expanded Source Types, see here: tradingview.com/v/yTwtoFhz/
- Loxx's Moving Averages, see here: tradingview.com/v/Qc1LnCik/
An example of filtered chop, see the yellow circles. The cluster filter identifies chop zones so you don't get stuck in a sideways market.
Script open-source
In pieno spirito TradingView, il creatore di questo script lo ha reso open-source, in modo che i trader possano esaminarlo e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricorda che la ripubblicazione del codice è soggetta al nostro Regolamento.
Public Telegram Group, t.me/algxtrading_public
VIP Membership Info: patreon.com/algxtrading/membership
VIP Membership Info: patreon.com/algxtrading/membership
Declinazione di responsabilità
Le informazioni ed i contenuti pubblicati non costituiscono in alcun modo una sollecitazione ad investire o ad operare nei mercati finanziari. Non sono inoltre fornite o supportate da TradingView. Maggiori dettagli nelle Condizioni d'uso.
Script open-source
In pieno spirito TradingView, il creatore di questo script lo ha reso open-source, in modo che i trader possano esaminarlo e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricorda che la ripubblicazione del codice è soggetta al nostro Regolamento.
Public Telegram Group, t.me/algxtrading_public
VIP Membership Info: patreon.com/algxtrading/membership
VIP Membership Info: patreon.com/algxtrading/membership
Declinazione di responsabilità
Le informazioni ed i contenuti pubblicati non costituiscono in alcun modo una sollecitazione ad investire o ad operare nei mercati finanziari. Non sono inoltre fornite o supportate da TradingView. Maggiori dettagli nelle Condizioni d'uso.