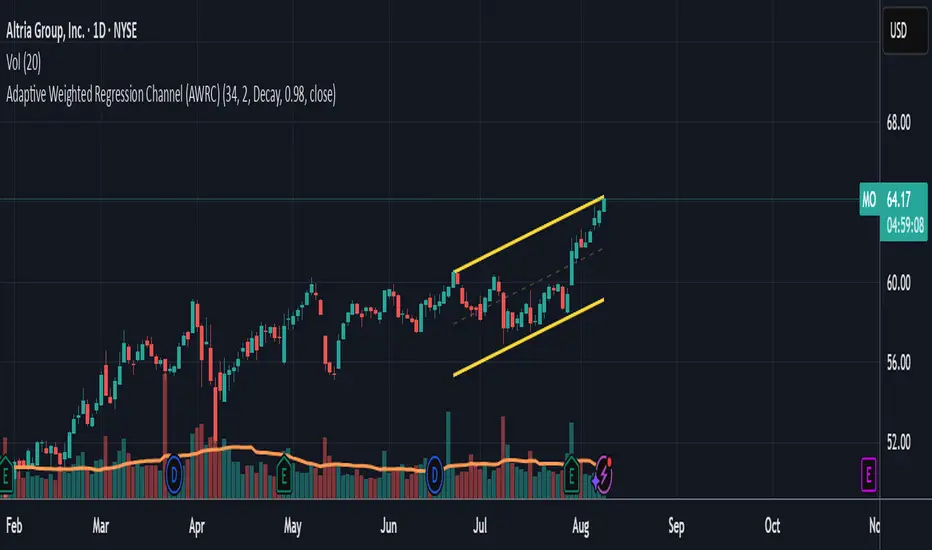
Adaptive Weighted Regression Channel (AWRC)Short Description:
The Adaptive Weighted Regression Channel (AWRC) is an advanced technical analysis tool that plots a dynamic regression channel based on the recent price action. The centerline is a linear regression (trendline) fitted to the selected price source over a rolling window. The channel boundaries are placed above and below the regression line by a user-selected multiple of the weighted standard deviation.
What makes AWRC unique is its ability to optionally weight each bar’s importance in the regression using Volume, ATR (Average True Range), or Recency Decay, offering a channel that can adapt to market volatility, participation, or trend acceleration.
Parameter Explanations:
length: Number of bars for the regression window (how many recent candles are included). Higher values = smoother, less sensitive channel.
StdDev Multiplier (mult): Controls the channel width. 2.0 is classic; higher = wider channels, lower = tighter.
Enable Weighting?: Turn ON to activate weighting of each bar. If OFF, all bars are equally weighted (classic regression channel).
Weight Type: Select what to use for weights (only active if Enable Weighting is ON):
"Volume": Higher volume bars have more influence on the regression.
"ATR": Bars with higher volatility (as measured by ATR) have more influence.
"Decay": More recent bars are given more weight (controlled by Decay parameter).
Decay: If Weight Type is "Decay", this controls the rate of recency decay. (e.g. 0.98 = slow decay; 0.90 = fast decay; values close to 1 mean a longer memory.)
Source for the calculation (src): Selects which price is regressed. Default is hl2 (average of high and low); you can choose close, open, etc.
Recommended Parameters:
For general use: length = 34, mult = 2.0, Enable Weighting = OFF, src = hl2
For volume-aware channel: Enable Weighting = ON, Weight Type = "Volume"
For volatility sensitivity: Enable Weighting = ON, Weight Type = "ATR"
For extra focus on recent price: Enable Weighting = ON, Weight Type = "Decay", Decay = 0.95 or 0.98
For swing trading: length = 21–55, mult = 1.5–2.5
For intraday/scalping: length = 10–20, mult = 1.0–1.5
Usage Tips:
The regression line shows the "best fit" trend for the selected window.
The channel captures the typical range; price breaking outside the channel can signal strength, exhaustion, or breakout.
Volume and ATR weighting help the channel adapt to market participation or volatility spikes.
Decay weighting locks onto the most recent trend direction quickly.
Adjust parameters to fit your timeframe and market volatility.
Use AWRC to spot trending moves, reversals, or overextensions.
Try different weighting and channel settings to match your trading style!
Cerca negli script per "如何用wind搜索股票的发行价和份数"
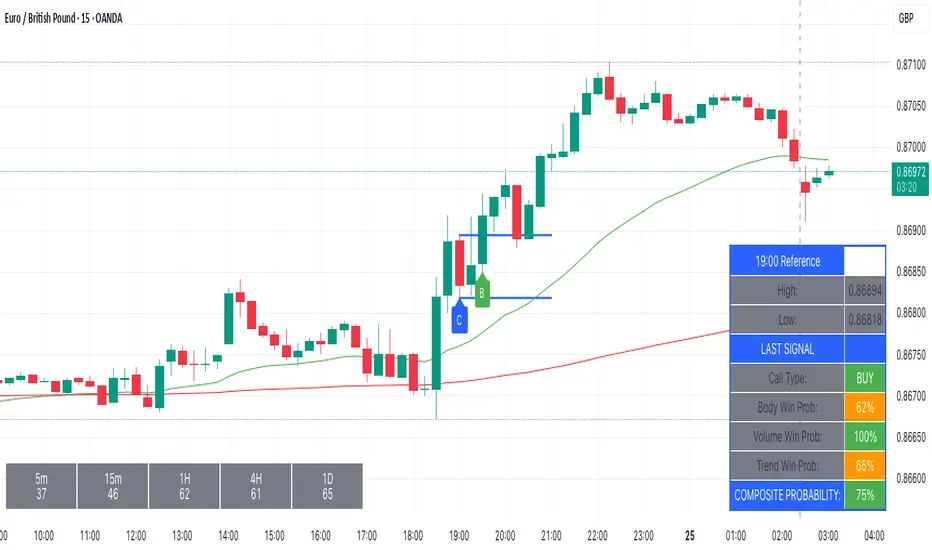
Kairos BarakahTrade with precision during high-probability windows using this advanced Pine Script indicator, designed specifically for Indian Standard Time (IST). The tool identifies key reversal opportunities within a user-defined trading session, combining time-based reference levels, sequence-validated signals, and multi-factor win probability analysis for confident decision-making.
Key Features
1. Time-Based Reference Levels
Automatically sets high/low reference levels at a customizable start time (default: 19:00 IST).
Active trading window with adjustable duration (default: 135 minutes).
Clear visual reference lines for easy tracking.
2. Intelligent Signal Generation
Initial Signals:
Buy (B): Triggered when price closes above the reference high.
Sell (S): Triggered when price closes below the reference low.
Reversal Signals (R):
Valid only after an initial signal, ensuring proper sequence.
Buy Reversal: Price closes above reference high (after a Sell signal).
Sell Reversal: Price closes below reference low (after a Buy signal).
3. Multi-Dimensional Win Probability
Body Strength: Measures candle conviction (body size / total range).
Volume Confirmation: Compares current volume to 20-period average.
Trend Alignment: Uses EMA crosses (9/21) and RSI (14) for momentum.
Composite Score: Weighted blend of all factors, color-coded for quick interpretation:
🟢 >70%: High-confidence signal.
🟠 40-69%: Moderate confidence.
🔴 <40%: Weak signal.
4. Professional Visualization
Clean labels (B/S/R) at signal points.
Real-time reference table showing levels, active signal, and probabilities.
Customizable alerts for all signal types.
Why Use This Indicator?
IST-Optimized: Tailored for Indian market hours.
Rules-Based Reversals: Avoids false signals with strict sequence checks.
Data-Driven Confidence: Win probability metrics reduce guesswork.
Flexible Setup: Adjust time windows and parameters to fit your strategy.
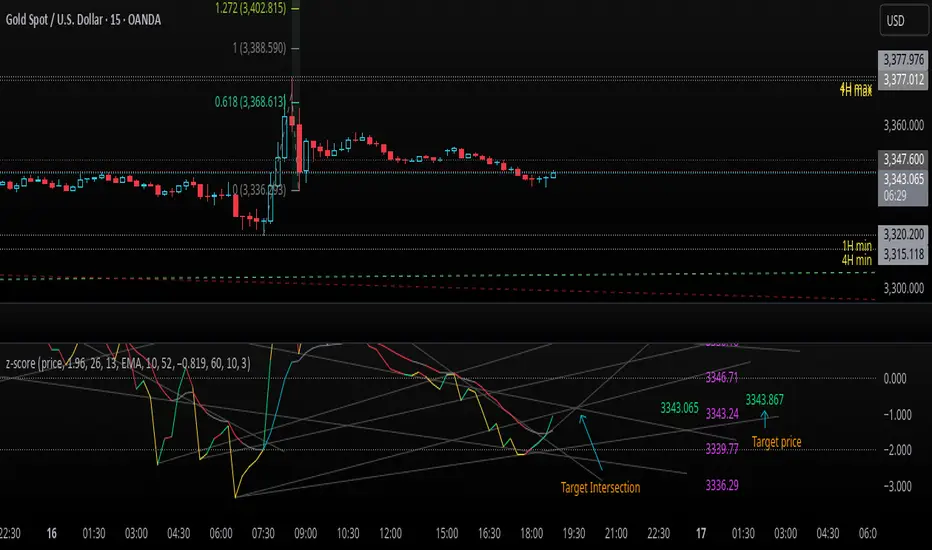
z-score-calkusi-v1.143z-scores incorporate the moment of N look-back bars to allow future price projection.
z-score = (X - mean)/std.deviation ; X = close
z-scores update with each new close print and with each new bar. Each new bar augments the mean and std.deviation for the N bars considered. The old Nth bar falls away from consideration with each new historical bar.
The indicator allows two other options for X: RSI or Moving Average.
NOTE: While trading use the "price" option only.
The other two options are provided for visualisation of RSI and Moving Average as z-score curves.
Use z-scores to identify tops and bottoms in the future as well as intermediate intersections through which a z-score will pass through with each new close and each new bar.
Draw lines from peaks and troughs in the past through intermediate peaks and troughs to identify projected intersections in the future. The most likely intersections are those that are formed from a line that comes from a peak in the past and another line that comes from a trough in the past. Try getting at least two lines from historical peaks and two lines from historical troughs to pass through a future intersection.
Compute the target intersection price in the future by clicking on the z-score indicator header to see a drag-able horizontal line to drag over the intersection. The target price is the last value displayed in the indicator's status bar after the closing price.
When the indicator header is clicked, a white horizontal drag-able line will appear to allow dragging the line over an intersection that has been drawn on the indicator for a future z-score projection and the associated future closing price.
With each new bar that appears, it is necessary to repeat the procedure of clicking the z-score indicator header to be able to drag the drag-able horizontal line to see the new target price for the selected intersection. The projected price will be different from the current close price providing a price arbitrage in time.
New intermediate peaks and troughs that appear require new lines be drawn from the past through the new intermediate peak to find a new intersection in the future and a new projected price. Since z-score curves are sort of cyclical in nature, it is possible to see where one has to locate a future intersection by drawing lines from past peaks and troughs.
Do not get fixated on any one projected price as the market decides which projected price will be realised. All prospective targets should be manually updated with each new bar.
When the z-score plot moves outside a channel comprised of lines that are drawn from the past, be ready to adjust to new market conditions.
z-score plots that move above the zero line indicate price action that is either rising or ranging. Similarly, z-score plots that move below the zero line indicate price action that is either falling or ranging. Be ready to adjust to new market conditions when z-scores move back and forth across the zero line.
A bar with highest absolute z-score for a cycle screams "reversal approaching" and is followed by a bar with a lower absolute z-score where close price tops and bottoms are realised. This can occur either on the next bar or a few bars later.
The indicator also displays the required N for a Normal(0,1) distribution that can be set for finer granularity for the z-score curve.This works with the Confidence Interval (CI) z-score setting. The default z-score is 1.96 for 95% CI.
Common Confidence Interval z-scores to find N for Normal(0,1) with a Margin of Error (MOE) of 1:
70% 1.036
75% 1.150
80% 1.282
85% 1.440
90% 1.645
95% 1.960
98% 2.326
99% 2.576
99.5% 2.807
99.9% 3.291
99.99% 3.891
99.999% 4.417
9-Jun-2025
Added a feature to display price projection labels at z-score levels 3, 2, 1, 0, -1, -2, 3.
This provides a range for prices available at the current time to help decide whether it is worth entering a trade. If the range of prices from say z=|2| to z=|1| is too narrow, then a trade at the current time may not be worth the risk.
Added plot for z-score moving average.
28-Jun-2025
Added Settings option for # of Std.Deviation level Price Labels to display. The default is 3. Min is 2. Max is 6.
This feature allows likelihood assessment for Fibonacci price projections from higher time frames at lower time frames. A Fibonacci price projection that falls outside |3.x| Std.Deviations is not likely.
Added Settings option for Chart Bar Count and Target Label Offset to allow placement of price labels for the standard z-score levels to the right of the window so that these are still visible in the window.
Target Label Offset allows adjustment of placement of Target Price Label in cases when the Target Price Label is either obscured by the price labels for the standard z-score levels or is too far right to be visible in the window.
9-Jul-2025
z-score 1.142 updates:
Displays in the status line before the close price the range for the selected Std. Deviation levels specified in Settings and |z-zMa|.
When |z-zMa| > |avg(z-zMa)| and zMa rising, |z-zMa| and zMa displays in aqua.
When |z-zMa| > |avg(z-zMa)| and zMa falling, |z-zMa| and zMa displays in red.
When |z-zMa| <= |avg(z-zMa)|, z and zMa display in gray.
z usually crosses over zMa when zMa is gray but not always. So if cross-over occurs when zMa is not gray, it implies a strong move in progress.
Practice makes perfect.
Use this indicator at your own risk
True Hour Open🧠 Why Count an Hour from 30th Minute to 30th Minute?
✅ Traditional Hour vs. Functional Hour
Traditional Time Logic: We’re used to viewing time in clean hourly chunks: 12:00 to 1:00, 1:00 to 2:00, and so on. This structure is fine for general purposes like clocks, meetings, and schedules.
Market Logic: Markets, however, don’t always respect these arbitrary human-made time divisions. Price action often develops momentum, structure, and transitions based on market participants' behavior, not on the clock.
🛠 What the Indicator Does
Marks the start of each hour at the 30th minute past the hour (e.g., 1:30, 2:30, 3:30).
Can highlight or segment candles that fall within a “30-to-30” hourly window.
Optionally draws background shading, lines, or boxes to visually group candles from one 30-minute mark to the next.
This helps you:
Visually align your trading with more accurate price behavior windows.
Anchor time blocks around actual market rhythm, not artificial time slots.
Backtest and strategize based on how candles behave in these alternative hourly segments.
📈 Summary
Trading is about timing. But great trading is about timing that makes sense.
By redefining the hour from 30 to 30, you’re not changing time—you’re aligning with how price moves in time.
Anomalous Holonomy Field Theory🌌 Anomalous Holonomy Field Theory (AHFT) - Revolutionary Quantum Market Analysis
Where Theoretical Physics Meets Trading Reality
A Groundbreaking Synthesis of Differential Geometry, Quantum Field Theory, and Market Dynamics
🔬 THEORETICAL FOUNDATION - THE MATHEMATICS OF MARKET REALITY
The Anomalous Holonomy Field Theory represents an unprecedented fusion of advanced mathematical physics with practical market analysis. This isn't merely another indicator repackaging old concepts - it's a fundamentally new lens through which to view and understand market structure .
1. HOLONOMY GROUPS (Differential Geometry)
In differential geometry, holonomy measures how vectors change when parallel transported around closed loops in curved space. Applied to markets:
Mathematical Formula:
H = P exp(∮_C A_μ dx^μ)
Where:
P = Path ordering operator
A_μ = Market connection (price-volume gauge field)
C = Closed price path
Market Implementation:
The holonomy calculation measures how price "remembers" its journey through market space. When price returns to a previous level, the holonomy captures what has changed in the market's internal geometry. This reveals:
Hidden curvature in the market manifold
Topological obstructions to arbitrage
Geometric phase accumulated during price cycles
2. ANOMALY DETECTION (Quantum Field Theory)
Drawing from the Adler-Bell-Jackiw anomaly in quantum field theory:
Mathematical Formula:
∂_μ j^μ = (e²/16π²)F_μν F̃^μν
Where:
j^μ = Market current (order flow)
F_μν = Field strength tensor (volatility structure)
F̃^μν = Dual field strength
Market Application:
Anomalies represent symmetry breaking in market structure - moments when normal patterns fail and extraordinary opportunities arise. The system detects:
Spontaneous symmetry breaking (trend reversals)
Vacuum fluctuations (volatility clusters)
Non-perturbative effects (market crashes/melt-ups)
3. GAUGE THEORY (Theoretical Physics)
Markets exhibit gauge invariance - the fundamental physics remains unchanged under certain transformations:
Mathematical Formula:
A'_μ = A_μ + ∂_μΛ
This ensures our signals are gauge-invariant observables , immune to arbitrary market "coordinate changes" like gaps or reference point shifts.
4. TOPOLOGICAL DATA ANALYSIS
Using persistent homology and Morse theory:
Mathematical Formula:
β_k = dim(H_k(X))
Where β_k are the Betti numbers describing topological features that persist across scales.
🎯 REVOLUTIONARY SIGNAL CONFIGURATION
Signal Sensitivity (0.5-12.0, default 2.5)
Controls the responsiveness of holonomy field calculations to market conditions. This parameter directly affects the threshold for detecting quantum phase transitions in price action.
Optimization by Timeframe:
Scalping (1-5min): 1.5-3.0 for rapid signal generation
Day Trading (15min-1H): 2.5-5.0 for balanced sensitivity
Swing Trading (4H-1D): 5.0-8.0 for high-quality signals only
Score Amplifier (10-200, default 50)
Scales the raw holonomy field strength to produce meaningful signal values. Higher values amplify weak signals in low-volatility environments.
Signal Confirmation Toggle
When enabled, enforces additional technical filters (EMA and RSI alignment) to reduce false positives. Essential for conservative strategies.
Minimum Bars Between Signals (1-20, default 5)
Prevents overtrading by enforcing quantum decoherence time between signals. Higher values reduce whipsaws in choppy markets.
👑 ELITE EXECUTION SYSTEM
Execution Modes:
Conservative Mode:
Stricter signal criteria
Higher quality thresholds
Ideal for stable market conditions
Adaptive Mode:
Self-adjusting parameters
Balances signal frequency with quality
Recommended for most traders
Aggressive Mode:
Maximum signal sensitivity
Captures rapid market moves
Best for experienced traders in volatile conditions
Dynamic Position Sizing:
When enabled, the system scales position size based on:
Holonomy field strength
Current volatility regime
Recent performance metrics
Advanced Exit Management:
Implements trailing stops based on ATR and signal strength, with mode-specific multipliers for optimal profit capture.
🧠 ADAPTIVE INTELLIGENCE ENGINE
Self-Learning System:
The strategy analyzes recent trade outcomes and adjusts:
Risk multipliers based on win/loss ratios
Signal weights according to performance
Market regime detection for environmental adaptation
Learning Speed (0.05-0.3):
Controls adaptation rate. Higher values = faster learning but potentially unstable. Lower values = stable but slower adaptation.
Performance Window (20-100 trades):
Number of recent trades analyzed for adaptation. Longer windows provide stability, shorter windows increase responsiveness.
🎨 REVOLUTIONARY VISUAL SYSTEM
1. Holonomy Field Visualization
What it shows: Multi-layer quantum field bands representing market resonance zones
How to interpret:
Blue/Purple bands = Primary holonomy field (strongest resonance)
Band width = Field strength and volatility
Price within bands = Normal quantum state
Price breaking bands = Quantum phase transition
Trading application: Trade reversals at band extremes, breakouts on band violations with strong signals.
2. Quantum Portals
What they show: Entry signals with recursive depth patterns indicating momentum strength
How to interpret:
Upward triangles with portals = Long entry signals
Downward triangles with portals = Short entry signals
Portal depth = Signal strength and expected momentum
Color intensity = Probability of success
Trading application: Enter on portal appearance, with size proportional to portal depth.
3. Field Resonance Bands
What they show: Fibonacci-based harmonic price zones where quantum resonance occurs
How to interpret:
Dotted circles = Minor resonance levels
Solid circles = Major resonance levels
Color coding = Resonance strength
Trading application: Use as dynamic support/resistance, expect reactions at resonance zones.
4. Anomaly Detection Grid
What it shows: Fractal-based support/resistance with anomaly strength calculations
How to interpret:
Triple-layer lines = Major fractal levels with high anomaly probability
Labels show: Period (H8-H55), Price, and Anomaly strength (φ)
⚡ symbol = Extreme anomaly detected
● symbol = Strong anomaly
○ symbol = Normal conditions
Trading application: Expect major moves when price approaches high anomaly levels. Use for precise entry/exit timing.
5. Phase Space Flow
What it shows: Background heatmap revealing market topology and energy
How to interpret:
Dark background = Low market energy, range-bound
Purple glow = Building energy, trend developing
Bright intensity = High energy, strong directional move
Trading application: Trade aggressively in bright phases, reduce activity in dark phases.
📊 PROFESSIONAL DASHBOARD METRICS
Holonomy Field Strength (-100 to +100)
What it measures: The Wilson loop integral around price paths
>70: Strong positive curvature (bullish vortex)
<-70: Strong negative curvature (bearish collapse)
Near 0: Flat connection (range-bound)
Anomaly Level (0-100%)
What it measures: Quantum vacuum expectation deviation
>70%: Major anomaly (phase transition imminent)
30-70%: Moderate anomaly (elevated volatility)
<30%: Normal quantum fluctuations
Quantum State (-1, 0, +1)
What it measures: Market wave function collapse
+1: Bullish eigenstate |↑⟩
0: Superposition (uncertain)
-1: Bearish eigenstate |↓⟩
Signal Quality Ratings
LEGENDARY: All quantum fields aligned, maximum probability
EXCEPTIONAL: Strong holonomy with anomaly confirmation
STRONG: Good field strength, moderate anomaly
MODERATE: Decent signals, some uncertainty
WEAK: Minimal edge, high quantum noise
Performance Metrics
Win Rate: Rolling performance with emoji indicators
Daily P&L: Real-time profit tracking
Adaptive Risk: Current risk multiplier status
Market Regime: Bull/Bear classification
🏆 WHY THIS CHANGES EVERYTHING
Traditional technical analysis operates on 100-year-old principles - moving averages, support/resistance, and pattern recognition. These work because many traders use them, creating self-fulfilling prophecies.
AHFT transcends this limitation by analyzing markets through the lens of fundamental physics:
Markets have geometry - The holonomy calculations reveal this hidden structure
Price has memory - The geometric phase captures path-dependent effects
Anomalies are predictable - Quantum field theory identifies symmetry breaking
Everything is connected - Gauge theory unifies disparate market phenomena
This isn't just a new indicator - it's a new way of thinking about markets . Just as Einstein's relativity revolutionized physics beyond Newton's mechanics, AHFT revolutionizes technical analysis beyond traditional methods.
🔧 OPTIMAL SETTINGS FOR MNQ 10-MINUTE
For the Micro E-mini Nasdaq-100 on 10-minute timeframe:
Signal Sensitivity: 2.5-3.5
Score Amplifier: 50-70
Execution Mode: Adaptive
Min Bars Between: 3-5
Theme: Quantum Nebula or Dark Matter
💭 THE JOURNEY - FROM IMPOSSIBLE THEORY TO TRADING REALITY
Creating AHFT was a mathematical odyssey that pushed the boundaries of what's possible in Pine Script. The journey began with a seemingly impossible question: Could the profound mathematical structures of theoretical physics be translated into practical trading tools?
The Theoretical Challenge:
Months were spent diving deep into differential geometry textbooks, studying the works of Chern, Simons, and Witten. The mathematics of holonomy groups and gauge theory had never been applied to financial markets. Translating abstract mathematical concepts like parallel transport and fiber bundles into discrete price calculations required novel approaches and countless failed attempts.
The Computational Nightmare:
Pine Script wasn't designed for quantum field theory calculations. Implementing the Wilson loop integral, managing complex array structures for anomaly detection, and maintaining computational efficiency while calculating geometric phases pushed the language to its limits. There were moments when the entire project seemed impossible - the script would timeout, produce nonsensical results, or simply refuse to compile.
The Breakthrough Moments:
After countless sleepless nights and thousands of lines of code, breakthrough came through elegant simplifications. The realization that market anomalies follow patterns similar to quantum vacuum fluctuations led to the revolutionary anomaly detection system. The discovery that price paths exhibit holonomic memory unlocked the geometric phase calculations.
The Visual Revolution:
Creating visualizations that could represent 4-dimensional quantum fields on a 2D chart required innovative approaches. The multi-layer holonomy field, recursive quantum portals, and phase space flow representations went through dozens of iterations before achieving the perfect balance of beauty and functionality.
The Balancing Act:
Perhaps the greatest challenge was maintaining mathematical rigor while ensuring practical trading utility. Every formula had to be both theoretically sound and computationally efficient. Every visual had to be both aesthetically pleasing and information-rich.
The result is more than a strategy - it's a synthesis of pure mathematics and market reality that reveals the hidden order within apparent chaos.
📚 INTEGRATED DOCUMENTATION
Once applied to your chart, AHFT includes comprehensive tooltips on every input parameter. The source code contains detailed explanations of the mathematical theory, practical applications, and optimization guidelines. This published description provides the overview - the indicator itself is a complete educational resource.
⚠️ RISK DISCLAIMER
While AHFT employs advanced mathematical models derived from theoretical physics, markets remain inherently unpredictable. No mathematical model, regardless of sophistication, can guarantee future results. This strategy uses realistic commission ($0.62 per contract) and slippage (1 tick) in all calculations. Past performance does not guarantee future results. Always use appropriate risk management and never risk more than you can afford to lose.
🌟 CONCLUSION
The Anomalous Holonomy Field Theory represents a quantum leap in technical analysis - literally. By applying the profound insights of differential geometry, quantum field theory, and gauge theory to market analysis, AHFT reveals structure and opportunities invisible to traditional methods.
From the holonomy calculations that capture market memory to the anomaly detection that identifies phase transitions, from the adaptive intelligence that learns and evolves to the stunning visualizations that make the invisible visible, every component works in mathematical harmony.
This is more than a trading strategy. It's a new lens through which to view market reality.
Trade with the precision of physics. Trade with the power of mathematics. Trade with AHFT.
I hope this serves as a good replacement for Quantum Edge Pro - Adaptive AI until I'm able to fix it.
— Dskyz, Trade with insight. Trade with anticipation.

Multi-Timeline 1.0Multi-TimeLines 1.0 - Comprehensive Description
WHAT IT DOES:
This indicator creates dynamic horizontal support/resistance lines based on opening prices captured at user-defined New York times. Unlike static horizontal lines, these levels automatically appear and disappear based on sophisticated session logic, providing traders with time-sensitive reference levels that adapt to market sessions.
HOW IT WORKS - TECHNICAL IMPLEMENTATION:
1.
Timezone Conversion Engine:
The script uses Pine Script's "America/New_York" timezone functions to ensure all time calculations are based on NY time, regardless of the user's chart timezone. This eliminates confusion and provides consistent behavior across global markets.
2.
Dual-Category Time Classification System:
The indicator employs a unique two-category classification system:
Category A (16:00-23:59 NY): Evening times that extend overnight until next day 15:59 NY
Category B (00:00-15:59 NY): Day times that extend until same day 15:59 NY
This classification handles the complex logic of overnight sessions and prevents lines from incorrectly resetting at midnight for evening times.
3. Price Capture Mechanism:
Uses precise time-hit detection with backup systems for edge cases (especially midnight 00:00). When a specified time occurs, the script captures the bar's opening price and stores it in persistent variables using Pine Script's var declarations.
4. Session-Aware Display Logic:
Lines only appear during their designated "display windows" - periods when the captured price level is relevant. The script uses conditional plotting with plot.style_linebr to create clean breaks when lines are inactive.
5. Smart Reset System:
Different reset behaviors based on time classification:
Category A times persist across midnight (for overnight analysis)
Category B times reset on day changes (except 00:00 which captures AT day change)
Automatic cleanup when display windows close
ORIGINALITY & UNIQUE FEATURES:
1. Overnight Session Handling:
Unlike basic horizontal line tools, this script properly handles overnight spans for evening times, making it invaluable for analyzing gaps and overnight price action.
2. Automatic Session Management:
No manual line drawing required - the script automatically manages when lines appear/disappear based on NY market sessions (15:59 close, 18:00 after-hours start).
3. Time-Window Display Logic:
Lines only show during relevant periods, reducing chart clutter and focusing attention on currently active levels.
TRADING CONCEPTS & APPLICATIONS:
1. Session-Based Analysis:
Capture opening prices at key session times:
00:00 NY: Sydney/Asian session start
03:00 NY: London pre-market
08:00 NY: London session open
09:30 NY: NYSE opening bell
18:00 NY: After-hours start
2. Gap Analysis:
Evening times (20:00-23:59) that extend overnight are particularly useful for:
Identifying potential gap-fill levels
Tracking overnight high/low breaks
Setting reference points for next-day trading
3. Support/Resistance Framework:
Opening prices at significant times often act as:
Intraday support/resistance levels
Reference points for breakout/breakdown analysis
Pivot levels for mean reversion strategies
HOW TO USE:
1. Time Input:
Enter times in "HH:MM" format using 24-hour NY time:
"09:30" for NYSE open
"15:30" for late-day reference
"20:00" for evening level (extends overnight)
2. Line Behavior:
Blue/Green/Cyan/Red lines: Your custom times
Yellow line: After-hours day open (18:00 NY start)
Lines appear with breaks during inactive periods
3. Strategic Setup:
Use 2-3 key session times for your trading style
Combine morning times (immediate reference) with evening times (overnight analysis)
Toggle after-hours line based on your market focus
CALCULATION METHOD:
The script uses direct opening price capture (no smoothing or averaging) at precise time hits, ensuring the most accurate representation of actual market levels at specified times. This raw price approach maintains the integrity of actual market opening prices rather than manipulated or calculated values.
This method is particularly effective because opening prices at significant times often represent institutional order flow and can act as magnetic levels throughout subsequent sessions.

AWR Pearsons R & LR Oscillator MTF1. Overview
This indicator is designed to analyze the correlation between a price series (or any custom indicator) and the bar index using Pearson’s correlation coefficient. It performs multiple linear regressions over shifted periods and then aggregates these results to create an oscillator. In addition, it integrates a multi-timeframe (MTF) analysis by retrieving the same calculations on 3 different time intervals, providing a more comprehensive view of the trend evolution.
2. User Parameters
The indicator offers several configurable parameters that allow the user to adjust both the calculations and the display:
Source (Linear Regression): The data source on which the regressions are applied (by default, the closing price).
Number of Linear Regressions (numOfLinReg): Allows choosing the number of correlation calculations (up to 10) to be carried out on different shifted periods.
Start Period (startPeriod) and Period Increment (periodIncrement): These parameters define the reference window for each regression. The calculation starts with a base period and then increases with each regression by a fixed increment, creating several time windows to assess the relationship between price evolution and time progression.
Deviation (def_deviation): Although defined, this parameter is intended to control the sensitivity of the calculations. It can be used in further developments of the indicator.
For Multi Time Frames analysis, three additional timeframes are provided through inputs in addition of the current period:
Sum up :
Timeframe 1 = current
Timeframe 2 = 30-minute (default settings)
Timeframe 3 = 1-hour (default settings)
Timeframe 4 = 4-hour (default settings)
These different timeframes allow you to obtain consistent or divergent signals over multiple resolutions, thereby enhancing the confidence of trading decisions.
3. Calculation Logic
At the core of the indicator is the f_calcConditions() function, which performs several essential tasks:
Calculating Pearson's Coefficients For each linear regression, the script uses ta.correlation() to measure the correlation between the chosen source (for example, the closing price) and the chronological index (bar_index). Up to 10 coefficients are computed over shifted windows, providing an evolving view of the linear relationship over different intervals.
Averaging the Results Once the coefficients are calculated, they are stored in an array and averaged to produce a global correlation value called avgPR_local.
Applying Moving Averages
The resulting average is then smoothed using several moving averages (SMA):
A short-term SMA (period of 14),
An intermediate SMA (period of 100),
A long-term SMA (period of 400).
These moving averages help to highlight the underlying trend of the oscillator by indicating the direction in which the correlation is moving.
Defining Trading Conditions Based on avgPR_local and its associated SMAs, multiple conditions are set to generate buy or sell signals:
Simple SMA Conditions :
Small signal :
Light blue below bar signal :
When the averaged coefficients lie between -1 and -0.63, are above the short-term SMA (14 periods), and are increasing, it may indicate a bullish dynamic (buy signal).
Orange above bar signal :
Conversely, when the value is higher (between 0.63 and 1) and below its SMA (14 periods), and are decreasing the trend is considered bearish (sell signal).
Medium signal :
Dark green signal
When the averaged coefficients lie between -1 and -0.45, are above the short-term SMA (14 periods), and are increasing, and also the average 100 is increasing. It may indicate a bullish dynamic (buy signal).
Light red signal :
Conversely, when the value is higher (between 0.45 and 1) and below its SMA (14 periods), the trend and are decreasing, and also the average 100 is decreasing. It may indicate a bearish dynamic(sell signal).
Light green signal :
When the averaged coefficients lie between -1 and -0.15, are above the short-term SMA (14 periods), and are increasing, and also the average 100 & 400 is increasing . It may indicate a bullish dynamic (buy signal).
Dark red signal :
Conversely, when the value is higher (between 0.45 and 1) and below its SMA (14 periods), the trend and are decreasing, and also the average 100 & 400 is decreasing. It may indicate a bearish dynamic(sell signal).
These additional conditions further refine the signals by verifying the consistency of the movement over longer periods. They check that the trends from the respective averages (intermediate and long-term) are in line with the direction indicated by the initial moving average.
These conditions are designed to capture moments when the oscillator's dynamics change, which can be interpreted as opportunities to enter or exit a trade.
4. Multi-Timeframes and Display
One of the main strengths of this indicator is its multi-timeframe approach.
This offers several advantages:
Comparative Analysis: Compare short-term dynamics with broader trends.
Enhanced Signal Reliability: A signal confirmed across multiple timeframes has a higher probability of success.
To visually highlight these signals on the chart, the indicator uses the plotchar() function with distinct symbols for each timeframe:
Current Timeframe: Signals are represented by the character "1"
30-Minute Timeframe: Displayed with the character "2".
1-Hour Timeframe: Displayed with the character "3".
4-Hour Timeframe: Displayed with the character "4".
The colors used are various shades of green for buy signals and shades of red/orange for sell signals, making it easy to distinguish between the different alerts.
5. Integrated Alerts
To avoid missing any trading opportunities, the indicator includes an alert condition via the alertcondition() function. This alert is triggered if any buy or sell signal is generated on any of the analyzed timeframes. The message "MTF valide" indicates that multiple timeframes are confirming the signal, enabling more informed decision-making.
6. How to Use This Indicator
Installation and Configuration: Copy the script into the TradingView Pine Script editor and add it to your chart. The default parameters can be tuned according to market behavior or personal preferences regarding sensitivity and responsiveness.
Interpreting the Signals:
Watch for the symbols on the chart corresponding to each timeframe.
A buy signal appears as a specific symbol below the bar (indicating a bullish condition based on a rising or less negative correlation), while a sell signal appears above the bar.
Multi-Timeframe Analysis: By comparing signals across timeframes, you can filter out false signals. For example, if the short-term timeframe shows a buy signal but the 4-hour timeframe indicates a bearish trend, you may need to reassess your position.
Adjusting the Settings: Depending on the asset type or market volatility, you might need to tweak the periods (startPeriod, periodIncrement) or the number of linear regressions to generate signals that better align with the price dynamics.
Using Alerts: Activate the built-in alert feature so that TradingView notifies you as soon as a multi-timeframe signal is detected. This ensures you stay informed even if you are not continuously monitoring the chart.
In Conclusion
The AWR Pearsons R & LR Oscillator MTF is a powerful tool for traders seeking a detailed understanding of market trends by combining statistical rigor (via Pearson's correlation coefficient) with a multi-timeframe approach. It is capable of generating clear entry and exit signals, visualized with specific symbols and colors depending on the timeframe. By adjusting the parameters to match your trading strategy and leveraging the alert system, you now have a robust instrument for making well-informed market decisions.
Feel free to dive deeper into each component and experiment with different configurations to see how the oscillator integrates with your overall technical analysis strategy. Enjoy exploring its potential and refining your trading approach!

ICT TIME ELEMENTS [KaninFX]## Overview
The ICT Time Elements indicator is a comprehensive trading tool designed to visualize the most critical market sessions and timeframes according to Inner Circle Trader (ICT) methodology. This indicator helps traders identify high-probability trading opportunities by highlighting key market sessions, killzones, and liquidity periods throughout the trading day.
## Key Features
### 🕐 Complete ICT Time Framework
- **Asian Range**: 8:00 PM - 12:00 AM (NY Time) - Evening consolidation period
- **London Killzone**: 2:00 AM - 5:00 AM (NY Time) - European market opening liquidity
- **NY Killzone**: 7:00 AM - 10:00 AM (NY Time) - US market opening with high volatility
- **Silver Bullet Sessions**:
- London Silver Bullet: 3:00 AM - 4:00 AM
- AM Silver Bullet: 10:00 AM - 11:00 AM
- PM Silver Bullet: 2:00 PM - 3:00 PM
- **Lunch Hours**: 5:00 AM - 7:00 AM & 12:00 PM - 1:00 PM (Lower volatility periods)
- **News Embargo**: 8:30 AM - 9:30 AM (High impact news release window)
- **20-Minute Macros**: :50 to :10 minutes of each hour (Short-term reversal periods)
- **True Day Close**: 4:00 PM - 4:30 PM (Official market close)
### 🎨 Visual Customization
- **Multiple Themes**: Dark, Light, and Custom color schemes
- **Adjustable Opacity**: Control zone transparency (0-100%)
- **Font Customization**: Tiny, Small, Normal, Large text sizes
- **Custom Colors**: Personalize each zone with your preferred colors
- **Professional Display**: Clean histogram visualization with zone labels
### 🌍 Multi-Timezone Support
Built-in support for major trading centers:
- America/New_York (Default)
- America/Chicago
- America/Los_Angeles
- Europe/London
- Asia/Tokyo
- Asia/Shanghai
- Australia/Sydney
### 📊 Smart Information Display
- **Real-time Zone Detection**: Automatically identifies current active session
- **Zone Labels**: Clear labeling at the center of each time period
- **Current Zone Indicator**: Arrow pointer showing the active session
- **Comprehensive Info Table**: Quick reference for all time zones and their schedules
- **Flexible Table Positioning**: Place info table in any corner of your chart
### ⚡ Performance Optimized
- **Memory Management**: Automatic cleanup of old labels to maintain performance
- **Efficient Processing**: Optimized time calculations for smooth operation
- **Resource Control**: Limited label generation to prevent system overload
## How It Works
The indicator continuously monitors the current time against predefined ICT session schedules. When price action enters a recognized time zone, the indicator:
1. **Highlights the Period**: Colors the histogram bar according to the active session
2. **Labels the Zone**: Places descriptive text identifying the current market condition
3. **Updates Info Table**: Shows current session status and complete schedule
4. **Tracks Macro Periods**: Identifies 20-minute reversal windows within major sessions
### Special Features
- **Macro Detection**: Automatically identifies when current time falls within a 20-minute macro period
- **Session Overlap Handling**: Properly manages overlapping time zones with priority logic
- **Dynamic Color Adjustment**: Theme-aware color selection for optimal visibility
## Best Use Cases
### For ICT Traders
- Identify optimal entry times during killzone sessions
- Recognize silver bullet opportunities for quick scalps
- Avoid trading during lunch hour consolidations
- Prepare for news embargo volatility
### For Session Traders
- Track major market session transitions
- Plan trading strategy around high-liquidity periods
- Understand global market flow and timing
### For Swing Traders
- Identify macro trend continuation points
- Time position entries during optimal sessions
- Understand market structure changes across sessions
## Installation & Setup
1. Add the indicator to your TradingView chart
2. Select your preferred timezone from the dropdown
3. Choose theme (Dark/Light) or customize colors
4. Adjust font size and table position to your preference
5. Enable/disable features as needed for your trading style
## Pro Tips
- **Combine with Price Action**: Use time zones alongside support/resistance levels
- **Focus on Killzones**: Highest probability setups occur during London and NY killzones
- **Watch Silver Bullets**: These 1-hour windows often provide excellent reversal opportunities
- **Respect Lunch Hours**: Lower volatility periods - consider smaller position sizes
- **News Embargo Awareness**: Prepare for potential whipsaws during 8:30-9:30 AM
## Conclusion
The ICT Time Elements indicator transforms complex ICT timing concepts into an easy-to-read visual tool. Whether you're a beginner learning ICT methodology or an experienced trader looking to optimize your timing, this indicator provides the essential market session awareness needed for successful trading.
*Compatible with all TradingView plans and timeframes. Works best on 1-minute to 1-hour charts for optimal session visualization.*
Polarity-VoVix Fusion Index (PVFI) Polarity-VoVix Fusion Index (PVFI) - Order Flow and Volatility Regime Detector
The PVFI is a next-generation indicator that fuses the Order Flow Polarity Index (OFPI) with a proprietary VoVix Volume Delta (VVD) engine. This tool is designed for traders who want to see not just how much volume is trading, but who is in control and how volatility is shifting beneath the surface.
What Makes PVFI Standout from the rest?
- Dual Engine: PVFI combines two advanced signals:
* OFPI: Measures real-time buy/sell pressure using candle body position and volume, then smooths it with a T3 moving average for clarity and responsiveness.
* VVD: Captures the "volatility of volume delta" - a normalized, memory-boosted measure of aggressive buying/selling, with a custom non-linear clamp for organic, non-pegged signals.
- Visual Clarity: Neon-glow OFPI line and shadowed, color-gradient VVD area make regime shifts and momentum instantly visible.
- Adaptive Dashboard: Toggle between a full-featured dashboard (desktop) and a compact info line (mobile) for seamless use on any device.
- Universal: Works on any asset - crypto, stocks, futures, forex - and any timeframe.
- No Chart Clutter: Clean, modern visuals and toggles for a pro look.
Inputs:
OFPI Lookback Length (ofpi_len): Sets the window for order flow pressure calculation. Shorter = more sensitive, longer = smoother. For scalping, try 5-10. For swing trading, 15-30. Crypto often benefits from shorter windows due to volatility.
OFPI T3 Smoothing Length (t3_len): Controls the smoothness of the OFPI line. Lower = more responsive, higher = smoother. Use 3-7 for fast markets, 8-15 for slow or higher timeframes.
OFPI T3 Volume Factor (t3_vf): Adjusts the T3’s sensitivity. Higher = more responsive, lower = more stable. 0.6-0.8 is typical. Raise for more “snappy” signals, lower for less noise.
VVD Delta Lookback (delta_len): Sets the window for VVD’s volume delta calculation. 10-20 for most assets. Shorter for high-volatility, longer for slow markets.
VVD Volatility Normalization Length (vol_norm_len): Normalizes VVD by recent volume. 15-30 is typical. Use higher for assets with wild volume swings.
VVD Momentum Memory (momentum_mem): Adds a “memory” boost to VVD, amplifying persistent buying/selling. 2-5 is common. Lower for choppy markets, higher for trending.
Show Dashboard (showDash): Toggles the full dashboard table (best for desktop). Turn off for a minimalist or mobile setup.
Show Compact Info Line (showInfoLabel): Toggles a single-line info label (best for mobile). Turn on for mobile or minimalist setups.
How PVFI Works:
- OFPI Calculation: Splits each candle’s volume into buy/sell pressure based on where the close is within the range. Aggregates over your chosen lookback, then smooths with a T3 moving average for a neon, lag-minimized signal.
- VVD Calculation: Measures the “aggression” of volume (body-weighted), normalizes by recent volume, and applies a memory boost for persistent trends. Uses a custom tanh clamp for a natural, non-pegged range.
- Visuals: OFPI is plotted as a neon line (with glow). VVD is a color-gradient area with a soft shadow, instantly showing regime shifts.
- Dashboard/Info Line: Desktop: Full dashboard with all key stats, color-coded and branded. Mobile: Compact info line with arrows for quick reads.
How you'll use PVFI:
- Bullish OFPI (Teal Neon, Up Arrow): Buyers are dominating. Look for breakouts, trend continuations, or confirmation with your own system.
- Bearish OFPI (Green Neon, Down Arrow): Sellers are in control. Watch for breakdowns or short setups.
- VVD Positive (Teal Area): Aggressive buying is increasing. Confirm with price action.
- VVD Negative (Purple Area): Aggressive selling is increasing. Use for risk management or short bias.
- Neutral/Flat: Market is balanced or indecisive. Consider waiting for a clear regime shift.
- Dashboard/Info Line: Use the dashboard for full context, or the info line for a quick glance on mobile.
Tips:
- For scalping, use lower lookbacks and smoothing.
- For swing trading, increase lookbacks and smoothing for stability.
- Works on all assets and timeframes - tune to your style.
Why PVFI is Unique:
- Fusion of Order Flow and Volatility: No other indicator combines body-based order flow with a volatility-of-volume delta, both visualized with modern, pro-grade graphics.
- Adaptive, Not Static: PVFI adapts to market regime, not just price movement.
- Mobile-Ready: Dashboard and info line toggles for any device.
- No Chart Clutter: Clean, color-coded, and easy to read.
For Educational Use Only
PVFI is a research and educational tool, not financial advice. Always use proper risk management and combine with your own strategy.
Trade with clarity. Trade with edge.
— Dskyz , for DAFE Trading Systems

Casa_UtilsLibrary "Casa_Utils"
A collection of convenience and helper functions for indicator and library authors on TradingView
formatNumber(num)
My version of format number that doesn't have so many decimal places...
Parameters:
num (float) : The number to be formatted
Returns: The formatted number
getDateString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd format.
Parameters:
timestamp (int) : The timestamp to stringify
Returns: The date string
getDateTimeString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd hh:mm format.
Parameters:
timestamp (int) : The timestamp to stringify
Returns: The date string
getInsideBarCount()
Gets the number of inside bars for the current chart. Can also be passed to request.security to get the same for different timeframes.
Returns: The # of inside bars on the chart right now.
getLabelStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the label styles into a dropdown for configuration settings. So, I specify them in the following format: "Center", "Left", "Lower Left", "Lower Right", "Right", "Up", "Upper Left", "Upper Right", "Plain Text", "No Labels". This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string)
acceptGivenIfNoMatch (bool) : If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: The string expected by tradingview functions
getTime(hourNumber, minuteNumber)
Given an hour number and minute number, adds them together and returns the sum. To be used by getLevelBetweenTimes when fetching specific price levels during a time window on the day.
Parameters:
hourNumber (int) : The hour number
minuteNumber (int) : The minute number
Returns: The sum of all the minutes
getHighAndLowBetweenTimes(start, end)
Given a start and end time, returns the high or low price during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: The high or low value
getPremarketHighsAndLows()
Returns an expression that can be used by request.security to fetch the premarket high & low levels in a tuple.
Returns: (tuple)
getAfterHoursHighsAndLows()
Returns an expression that can be used by request.security to fetch the after hours high & low levels in a tuple.
Returns: (tuple)
getOvernightHighsAndLows()
Returns an expression that can be used by request.security to fetch the overnight high & low levels in a tuple.
Returns: (tuple)
getNonRthHighsAndLows()
Returns an expression that can be used by request.security to fetch the high & low levels for premarket, after hours and overnight in a tuple.
Returns: (tuple)
getLineStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the line styles into a dropdown for configuration settings. So, I specify them in the following format: "Solid", "Dashed", "Dotted", "None/Hidden". This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string) : Plain english (or TV Standard) version of the style string
acceptGivenIfNoMatch (bool) : If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: The string expected by tradingview functions
getPercentFromPrice(price)
Get the % the current price is away from the given price.
Parameters:
price (float)
Returns: The % the current price is away from the given price.
getPositionFromString(position)
Tradingview doesn't give you a nice way to put the positions into a dropdown for configuration settings. So, I specify them in the following format: "Top Left", "Top Center", "Top Right", "Middle Left", "Middle Center", "Middle Right", "Bottom Left", "Bottom Center", "Bottom Right". This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
position (string) : Plain english position string
Returns: The string expected by tradingview functions
getRsiAvgsExpression(rsiLength)
Call request.security with this as the expression to get the average up/down values that can be used with getRsiPrice (below) to calculate the price level where the supplied RSI level would be reached.
Parameters:
rsiLength (simple int) : The length of the RSI requested.
Returns: A tuple containing the avgUp and avgDown values required by the getRsiPrice function.
getRsiPrice(rsiLevel, rsiLength, avgUp, avgDown)
use the values returned by getRsiAvgsExpression() to calculate the price level when the provided RSI level would be reached.
Parameters:
rsiLevel (float) : The RSI level to find price at.
rsiLength (int) : The length of the RSI to calculate.
avgUp (float) : The average move up of RSI.
avgDown (float) : The average move down of RSI.
Returns: The price level where the provided RSI level would be met.
getSizeFromString(sizeString)
Tradingview doesn't give you a nice way to put the sizes into a dropdown for configuration settings. So, I specify them in the following format: "Auto", "Huge", "Large", "Normal", "Small", "Tiny". This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
sizeString (string) : Plain english size string
Returns: The string expected by tradingview functions
getTimeframeOfChart()
Get the timeframe of the current chart for display
Returns: The string of the current chart timeframe
getTimeNowPlusOffset(candleOffset)
Helper function for drawings that use xloc.bar_time to help you know the time offset if you want to place the end of the drawing out into the future. This determines the time-size of one candle and then returns a time n candleOffsets into the future.
Parameters:
candleOffset (int) : The number of items to find singular/plural for.
Returns: The future time
getVolumeBetweenTimes(start, end)
Given a start and end time, returns the sum of all volume across bars during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: The volume
isToday()
Returns true if the current bar occurs on today's date.
Returns: True if current bar is today
padLabelString(labelText, labelStyle)
Pads a label string so that it appears properly in or not in a label. When label.style_none is used, this will make sure it is left-aligned instead of center-aligned. When any other type is used, it adds a single space to the right so there is padding against the right end of the label.
Parameters:
labelText (string) : The string to be padded
labelStyle (string) : The style of the label being padded for.
Returns: The padded string
plural(num, singular, plural)
Helps format a string for plural/singular. By default, if you only provide num, it will just return "s" for plural and nothing for singular (eg. plural(numberOfCats)). But you can optionally specify the full singular/plural words for more complicated nomenclature (eg. plural(numberOfBenches, 'bench', 'benches'))
Parameters:
num (int) : The number of items to find singular/plural for.
singular (string) : The string to return if num is singular. Defaults to an empty string.
plural (string) : The string to return if num is plural. Defaults to 's' so you can just add 's' to the end of a word.
Returns: The singular or plural provided strings depending on the num provided.
timeframeInSeconds(timeframe)
Get the # of seconds in a given timeframe. Tradingview's timeframe.in_seconds() expects a simple string, and we often need to use series string, so this is an alternative to get you the value you need.
Parameters:
timeframe (string)
Returns: The number of secondsof that timeframe
timeframeOfChart()
Convert a timeframe string to a consistent standard.
Returns: The standard format for the string, or the unchanged value if it is unknown.
timeframeToString(timeframe)
Convert a timeframe string to a consistent standard.
Parameters:
timeframe (string)
Returns: (string) The standard format for the string, or the unchanged value if it is unknown.
stringToTimeframe(strTimeframe)
Convert an english-friendly timeframe string to a value that can be used by request.security. Specifically, this corrects hour strings (eg. 4h) to their numeric "minute" equivalent (eg. 240)
Parameters:
strTimeframe (string)
Returns: (string) The standard format for the string, or the unchanged value if it is unknown.
getPriceLabel(price, labelOffset, labelStyle, labelSize, labelColor, textColor)
Defines a label for the end of a price level line.
Parameters:
price (float) : The price level to render the label at.
labelOffset (int) : The number of candles to place the label to the right of price.
labelStyle (string) : A plain english string as defined in getLabelStyleFromString.
labelSize (string) : The size of the label.
labelColor (color) : The color of the label.
textColor (color) : The color of the label text (defaults to #ffffff)
Returns: The label that was created.
setPriceLabel(label, labelName, price, labelOffset, labelTemplate, labelStyle, labelColor, textColor)
Updates the label position & text based on price changes.
Parameters:
label (label) : The label to update.
labelName (string) : The name of the price level to be placed on the label.
price (float) : The price level to render the label at.
labelOffset (int) : The number of candles to place the label to the right of price.
labelTemplate (string) : The str.format template to use for the label. Defaults to: '{0}: {1} {2}{3,number,#.##}%' which means '{price}: {labelName} {+/-}{percentFromPrice}%'
labelStyle (string)
labelColor (color)
textColor (color)
getPriceLabelLine(price, labelOffset, labelColor, lineWidth)
Defines a line that will stretch from the plot line to the label.
Parameters:
price (float) : The price level to render the label at.
labelOffset (int) : The number of candles to place the label to the right of price.
labelColor (color)
lineWidth (int) : The width of the line. Defaults to 1.
setPriceLabelLine(line, price, labelOffset, lastTime, lineColor)
Updates the price label line based on price changes.
Parameters:
line (line) : The line to update.
price (float) : The price level to render the label at.
labelOffset (int) : The number of candles to place the label to the right of price.
lastTime (int) : The last time that the line should stretch from. Defaults to time.
lineColor (color)

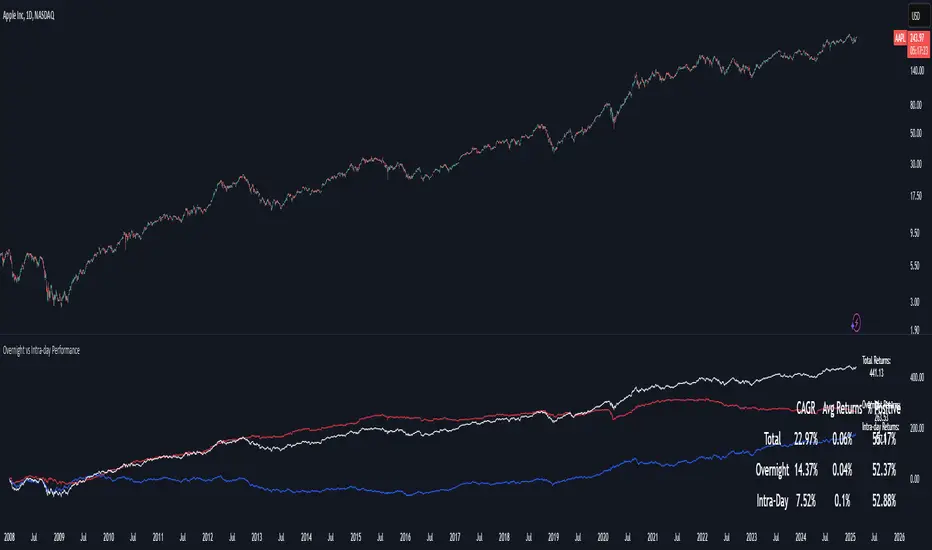
Overnight vs Intra-day Performance█ STRATEGY OVERVIEW
The "Overnight vs Intra-day Performance" indicator quantifies price behaviour differences between trading hours and overnight periods. It calculates cumulative returns, compound growth rates, and visualizes performance components across user-defined time windows. Designed for analytical use, it helps identify whether returns are primarily generated during market hours or overnight sessions.
█ USAGE
Use this indicator on Stocks and ETFs to visualise and compare intra-day vs overnight performance
█ KEY FEATURES
Return Segmentation : Separates total returns into overnight (close-to-open) and intraday (open-to-close) components
Growth Tracking : Shows simple cumulative returns and compound annual growth rates (CAGR)
█ VISUALIZATION SYSTEM
1. Time-Series
Overnight Returns (Red)
Intraday Returns (Blue)
Total Returns (White)
2. Summary Table
Displays CAGR
3. Price Chart Labels
Floating annotations showing absolute returns and CAGR
Color-coded to match plot series
█ PURPOSE
Quantify market behaviour disparities between active trading sessions and overnight positioning
Provide institutional-grade attribution analysis for returns generation
Enable tactical adjustment of trading schedules based on historical performance patterns
Serve as foundational research for session-specific trading strategies
█ IDEAL USERS
1. Portfolio Managers
Analyse overnight risk exposure across holdings
Optimize execution timing based on return distributions
2. Quantitative Researchers
Study market microstructure through time-segmented returns
Develop alpha models leveraging session-specific anomalies
3. Market Microstructure Analysts
Identify liquidity patterns in overnight vs daytime sessions
Research ETF premium/discount mechanics
4. Day Traders
Align trading hours with highest probability return windows
Avoid overnight gaps through informed position sizing
Regime Classifier Oscillator (AiBitcoinTrend)The Regime Classifier Oscillator (AiBitcoinTrend) is an advanced tool for understanding market structure and detecting dynamic price regimes. By combining filtered price trends, clustering algorithms, and an adaptive oscillator, it provides traders with detailed insights into market phases, including accumulation, distribution, advancement, and decline.
This innovative tool simplifies market regime classification, enabling traders to align their strategies with evolving market conditions effectively.
👽 What is a Regime Classifier, and Why is it Useful?
A Regime Classifier is a concept in financial analysis that identifies distinct market conditions or "regimes" based on price behavior and volatility. These regimes often correspond to specific phases of the market, such as trends, consolidations, or periods of high or low volatility. By classifying these regimes, traders and analysts can better understand the underlying market dynamics, allowing them to adapt their strategies to suit prevailing conditions.
👽 Common Uses in Finance
Risk Management: Identifying high-volatility regimes helps traders adjust position sizes or hedge risks.
Strategy Optimization: Traders tailor their approaches—trend-following strategies in trending regimes, mean-reversion strategies in consolidations.
Forecasting: Understanding the current regime aids in predicting potential transitions, such as a shift from accumulation to an upward breakout.
Portfolio Allocation: Investors allocate assets differently based on market regimes, such as increasing cash positions in high-volatility environments.
👽 Why It’s Important
Markets behave differently under varying conditions. A regime classifier provides a structured way to analyze these changes, offering a systematic approach to decision-making. This improves both accuracy and confidence in navigating diverse market scenarios.
👽 How We Implemented the Regime Classifier in This Indicator
The Regime Classifier Oscillator takes the foundational concept of market regime classification and enhances it with advanced computational techniques, making it highly adaptive.
👾 Median Filtering: We smooth price data using a custom median filter to identify significant trends while eliminating noise. This establishes a baseline for price movement analysis.
👾 Clustering Model: Using clustering techniques, the indicator classifies volatility and price trends into distinct regimes:
Advance: Strong upward trends with low volatility.
Decline: Downward trends marked by high volatility.
Accumulation: Consolidation phases with subdued volatility.
Distribution: Topping or bottoming patterns with elevated volatility.
This classification leverages historical price data to refine cluster boundaries dynamically, ensuring adaptive and accurate detection of market states.
Volatility Classification: Price volatility is analyzed through rolling windows, separating data into high and low volatility clusters using distance-based assignments.
Price Trends: The interaction of price levels with the filtered trendline and volatility clusters determines whether the market is advancing, declining, accumulating, or distributing.
👽 Dynamic Cycle Oscillator (DCO):
Captures cyclic behavior and overlays it with smoothed oscillations, providing real-time feedback on price momentum and potential reversals.
Regime Visualization:
Regimes are displayed with intuitive labels and background colors, offering clear, actionable insights directly on the chart.
👽 Why This Implementation Stands Out
Dynamic and Adaptive: The clustering and refit mechanisms adapt to changing market conditions, ensuring relevance across different asset classes and timeframes.
Comprehensive Insights: By combining price trends, volatility, and cyclic behaviors, the indicator provides a holistic view of the market.
This implementation bridges the gap between theoretical regime classification and practical trading needs, making it a powerful tool for both novice and experienced traders.
👽 Applications
👾 Regime-Based Trading Strategies
Traders can use the regime classifications to adapt their strategies effectively:
Advance & Accumulation: Favorable for entering or holding long positions.
Decline & Distribution: Opportunities for short positions or risk management.
👾 Oscillator Insights for Trend Analysis
Overbought/oversold conditions: Early warning of potential reversals.
Dynamic trends: Highlights the strength of price momentum.
👽 Indicator Settings
👾 Filter and Classification Settings
Filter Window Size: Controls trend detection sensitivity.
ATR Lookback: Adjusts the threshold for regime classification.
Clustering Window & Refit Interval: Fine-tunes regime accuracy.
👾 Oscillator Settings
Dynamic Cycle Oscillator Lookback: Defines the sensitivity of cycle detection.
Smoothing Factor: Balances responsiveness and stability.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

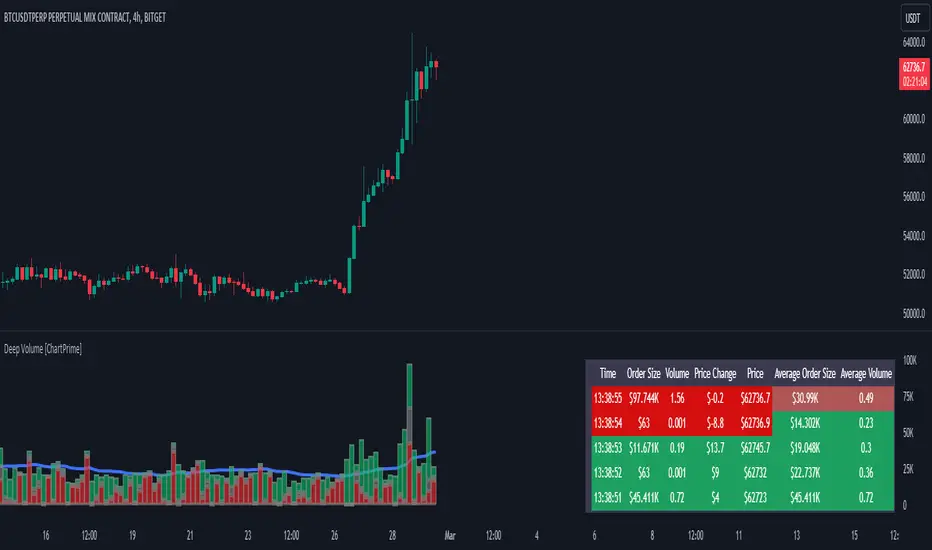
Deep Volume [ChartPrime]Deep Volume is an indicator designed to give you high fidelity volume information. It does this by utilizing real time data provided by Tradingview to generate a wide range of metrics. We have included a convenient column chart to visualize the polarity of the volume, and a table to see the real time data. This works by utilizing pine script's varip feature to get information within candles. This is convenient as it allows users to get lower time frame information without the use of ltf functions. The result is seconds level data with out the need to be on a lower time frame chart. As a result, as you increase the time frame of the chart the updates will become slower. This is because Tradingview doesn't update the chart information as frequently on higher time frames as there isn't as much of a need.
This indicator works on real time data so to compensate for this we generate a simulated history based on candle structure. This helps in estimating the state of the moving average before the real time data starts. As a result the estimated history isn't as accurate and should be treated as such. That being said it is nice to have an estimation when the indicator is first loaded onto the chart.
Finally we have included a cumulative volume comparison that shows you how much volume there is compared to the average cumulative volume for the day. This metric utilizes a gradient to help you interpret the information at a glance. Low daily volume is represented with grays by default, while normal volume and greater is represented with a green color by default.
The table is partitioned into two sections; tick data, and average data. On the left you will see color coded information based on the direction of the move. On the left, the information is color coded based on the average movement direction. You can control how much information is displayed in the table within the indicators settings. This is defaulted to 20 but it can be as long or short as you like. Every new candle open the far left of the table you will see a 🗘 symbol and at the start of a new session you will see a 🗓 symbol.
The included metrics are as follows:
Time: This displays the time of the real time data update.
Time Delta: This displays the elapsed time between updates.
Order Size: This is the volume times the price change between updates.
Volume: This is the volume change for the update.
Price Change: This is the change in price since the last update.
Price: This is the price of the asset at the time of the update.
Speed of Tape: This is the average time delta. Use this to see how quickly the market is moving.
Average Order Size: This is the average order size.
Average Volume: This is the average volume
Volume Ratio: This the the ratio of bullish to bearish volume as expressed by a percent. 100% is all bullish within the window and -100% is all bearish within the window.
Average Price Change: This is the average price change within the window.
Sensitivity: This is a volatility metric designed to show you the price change per 1 volume unit.
Relative Sensitivity: This is a volatility metric designed to show you the average price change per average volume.
Enjoy
UtilsLibrary "Utils"
A collection of convenience and helper functions for indicator and library authors on TradingView
formatNumber(num)
My version of format number that doesn't have so many decimal places...
Parameters:
num (float) : (float) the number to be formatted
Returns: (string) The formatted number
getDateString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd format.
Parameters:
timestamp (int) : (int) The timestamp to stringify
Returns: (int) The date string
getDateTimeString(timestamp)
Convenience function returns timestamp in yyyy/MM/dd hh:mm format.
Parameters:
timestamp (int) : (int) The timestamp to stringify
Returns: (int) The date string
getInsideBarCount()
Gets the number of inside bars for the current chart. Can also be passed to request.security to get the same for different timeframes.
Returns: (int) The # of inside bars on the chart right now.
getLabelStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the label styles into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string)
acceptGivenIfNoMatch (bool) : (bool) If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: (string) The string expected by tradingview functions
getTime(hourNumber, minuteNumber)
Given an hour number and minute number, adds them together and returns the sum. To be used by getLevelBetweenTimes when fetching specific price levels during a time window on the day.
Parameters:
hourNumber (int) : (int) The hour number
minuteNumber (int) : (int) The minute number
Returns: (int) The sum of all the minutes
getHighAndLowBetweenTimes(start, end)
Given a start and end time, returns the high or low price during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: (float) The high or low value
getPremarketHighsAndLows()
Returns an expression that can be used by request.security to fetch the premarket high & low levels in a tuple.
Returns: (tuple)
getAfterHoursHighsAndLows()
Returns an expression that can be used by request.security to fetch the after hours high & low levels in a tuple.
Returns: (tuple)
getOvernightHighsAndLows()
Returns an expression that can be used by request.security to fetch the overnight high & low levels in a tuple.
Returns: (tuple)
getNonRthHighsAndLows()
Returns an expression that can be used by request.security to fetch the high & low levels for premarket, after hours and overnight in a tuple.
Returns: (tuple)
getLineStyleFromString(styleString, acceptGivenIfNoMatch)
Tradingview doesn't give you a nice way to put the line styles into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
styleString (string) : (string) Plain english (or TV Standard) version of the style string
acceptGivenIfNoMatch (bool) : (bool) If no match for styleString is found and this is true, the function will return styleString, otherwise it will return tradingview's preferred default
Returns: (string) The string expected by tradingview functions
getPercentFromPrice(price)
Get the % the current price is away from the given price.
Parameters:
price (float)
Returns: (float) The % the current price is away from the given price.
getPositionFromString(position)
Tradingview doesn't give you a nice way to put the positions into a dropdown for configuration settings. So, I specify them in the following format: . This function takes care of converting those custom strings back to the ones expected by tradingview scripts.
Parameters:
position (string) : (string) Plain english position string
Returns: (string) The string expected by tradingview functions
getTimeframeOfChart()
Get the timeframe of the current chart for display
Returns: (string) The string of the current chart timeframe
getTimeNowPlusOffset(candleOffset)
Helper function for drawings that use xloc.bar_time to help you know the time offset if you want to place the end of the drawing out into the future. This determines the time-size of one candle and then returns a time n candleOffsets into the future.
Parameters:
candleOffset (int) : (int) The number of items to find singular/plural for.
Returns: (int) The future time
getVolumeBetweenTimes(start, end)
Given a start and end time, returns the sum of all volume across bars during that time window.
Parameters:
start (int) : The timestamp to start with (# of seconds)
end (int) : The timestamp to end with (# of seconds)
Returns: (float) The volume
isToday()
Returns true if the current bar occurs on today's date.
Returns: (bool) True if current bar is today
padLabelString(labelText, labelStyle)
Pads a label string so that it appears properly in or not in a label. When label.style_none is used, this will make sure it is left-aligned instead of center-aligned. When any other type is used, it adds a single space to the right so there is padding against the right end of the label.
Parameters:
labelText (string) : (string) The string to be padded
labelStyle (string) : (string) The style of the label being padded for.
Returns: (string) The padded string
plural(num, singular, plural)
Helps format a string for plural/singular. By default, if you only provide num, it will just return "s" for plural and nothing for singular (eg. plural(numberOfCats)). But you can optionally specify the full singular/plural words for more complicated nomenclature (eg. plural(numberOfBenches, 'bench', 'benches'))
Parameters:
num (int) : (int) The number of items to find singular/plural for.
singular (string) : (string) The string to return if num is singular. Defaults to an empty string.
plural (string) : (string) The string to return if num is plural. Defaults to 's' so you can just add 's' to the end of a word.
Returns: (string) The singular or plural provided strings depending on the num provided.
timeframeInSeconds(timeframe)
Get the # of seconds in a given timeframe. Tradingview's timeframe.in_seconds() expects a simple string, and we often need to use series string, so this is an alternative to get you the value you need.
Parameters:
timeframe (string)
Returns: (int) The number of secondsof that timeframe
timeframeToString(tf)
Convert a timeframe string to a consistent standard.
Parameters:
tf (string) : (string) The timeframe string to convert
Returns: (string) The standard format for the string, or the unchanged value if it is unknown.

buyer_seller_scalping_indicatorThis code is a custom script designed for analyzing trading volume within a specific time window on the TradingView platform. It offers a comprehensive analysis of buying and selling activity during a defined period and provides visual aids and data summaries for traders to make informed decisions. Here's a detailed breakdown of its functionality and how to use it:
1. Custom Time Period: The script starts by allowing you to specify a custom time period for analysis. In this example, it's set from 04:00 to 09:29. You can modify these time values to suit your specific trading needs.
2. Volume Calculation: The script calculates buying and selling volume based on price levels. It takes into account the open, high, low, and close prices to determine whether buying or selling pressure is dominant during the specified time frame.
3. Total Volume Calculation: It calculates the total volume within the custom time period. This can help you gauge the overall activity and liquidity during the chosen time window.
4. Visualizations: The script then plots visual elements on the chart:
- A volume histogram, which provides a graphical representation of the total volume during the time period.
- Buying and selling volume indicators, which are shown as circles on the chart, highlighting the relative strength of buyers and sellers.
- An average volume line, represented in gray, which helps you identify the average trading volume over a 50-period moving average.
5. Volume Type Determination: The script determines whether buyers or sellers dominate the market during the specified time period. It labels this as "Buyers Volume > Sellers Volume," "Sellers Volume > Buyers Volume," or "Buyers Volume = Sellers Volume." This information can be crucial for assessing market sentiment.
6. Percentage Breakdown: The script calculates the percentage of buying and selling volume in relation to the total volume, helping you understand the distribution of market participants. These percentages are displayed in a table.
7. Table Display: Finally, the script creates a table that displays the following information:
- The current volume type (buyers, sellers, or balanced), with corresponding text colors.
- The percentage of buyers and sellers in the market.
How to Use:
1. Copy the script and add it as a custom script on TradingView.
2. Apply the script to your desired financial chart.
3. Adjust the custom time period if needed.
4. Interpret the visual elements and table to gain insights into market sentiment and volume distribution during the specified time frame.
5. Use this information to inform your trading decisions and strategies, especially when trading within the chosen time window.
This script is a valuable tool for traders seeking to understand market dynamics and volume behavior during specific trading hours, ultimately aiding in more informed trading decisions.
Disclaimer:
The indicator provided herein is experimental and has not undergone comprehensive testing. Its usage is solely at your own risk.
The publisher assumes no responsibility for any trading decisions made based on the utilization of this indicator.

ICT Silver Bullet [LuxAlgo]The ICT Silver Bullet indicator is inspired from the lectures of "The Inner Circle Trader" (ICT) and highlights the Silver Bullet (SB) window which is a specific 1-hour interval where a Fair Value Gap (FVG) pattern can be formed.
When a FVG is formed during the Silver Bullet window, Support & Resistance lines will be drawn at the end of the SB session.
There are 3 different Silver Bullet windows (New York local time):
The London Open Silver Bullet (3 AM — 4 AM ~ 03:00 — 04:00)
The AM Session Silver Bullet (10 AM — 11 AM ~ 10:00 — 11:00)
The PM Session Silver Bullet (2 PM — 3 PM ~ 14:00 — 15:00)
🔶 USAGE
The ICT Silver Bullet indicator aims to provide users a comprehensive display as similar as possible to how anyone would manually draw the concept on their charts.
It's important to use anything below the 15-minute timeframe to ensure proper setups can display. In this section, we are purely using the 3-minute timeframe.
In the image below, we can see a bullish setup whereas a FVG was successfully retested during the Silver Bullet session. This was then followed by a move upwards to liquidity as our target.
Alternatively, you can also see below a bearish setup utilizing the ICT Silver Bullet indicator outlined.
At this moment, the indicator has removed all other FVGs within the Silver Bullet session & has confirmed this FVG as the retested one.
There is also a support level marked below to be used as a liquidity target as per the ICT Silver Bullet concept suggests.
In the below chart we can see 4 separate consecutive examples of bullish & bearish setups on the 3-minute chart.
🔶 CONCEPTS
This technique can visualize potential support/resistance lines, which can be used as targets.
The script contains 2 main components:
• forming of a Fair Value Gap (FVG)
• drawing support/resistance (S/R) lines
🔹 Forming of FVG
1 basic principle: when a FVG at the end of the SB session is not retraced, it will be made invisible.
Dependable on the settings, different FVG's will be shown.
• 'All FVG': all FVG's are shown, regardless the trend
• 'Only FVG's in the same direction of trend': Only FVG's are shown that are similar to the trend at that moment (trend can be visualized by enabling ' Show ' -> ' Trend ')
-> only bearish FVG when the trend is bearish vs. bullish FVG when trend is bullish
• 'strict': Besides being similar to the trend, only FVG's are shown when the closing price at the end of the SB session is:
– below the top of the FVG box (bearish FVG)
– above bottom of the FVG box (bullish FVG)
• 'super-strict': Besides being similar to the trend, only FVG's are shown when the FVG box is NOT broken
in the opposite direction AND the closing price at the end of the SB session is:
– below bottom of the FVG box (bearish FVG)
– above the top of the FVG box (bullish FVG)
' Super-Strict ' mode resembles ICT lectures the most.
🔹 Drawing support/resistance lines
When the SB session has ended, the script draws potential support/resistance lines, again, dependable on the settings.
• Previous session (any): S/R lines are fetched between current and previous session.
For example, when current session is ' AM SB Session (10 AM — 11 AM) ', then previous session is
' London Open SB (3 AM — 4 AM) ', S/R lines between these 2 sessions alone will be included.
• Previous session (similar): S/R lines are fetched between current and previous - similar - session.
For example, when current session is ' London Open SB (3 AM — 4 AM)' , only S/R lines between
current session and previous ' London Open SB (3 AM — 4 AM) ' session are included.
When a new session starts, S/R lines will be removed, except when enabling ' Keep lines (only in strict mode) '
This is not possible in ' All FVG ' or ' Only FVG's in the same direction of trend ' mode, since the chart would be cluttered.
Note that in ' All FVG ' or ' Only FVG's in the same direction of trend ' mode, both, Support/Resistance lines will be shown,
while in Strict/Super-Strict mode:
• only Support lines will be shown if a bearish FVG appears
• only Resistance lines if a bullish FVG is shown
The lines will still be drawn the the end of the SB session, when a valid FVG appears,
but the S/R lines will remain visible and keep being updated until price reaches that line.
This publication contains a "Minimum Trade Framework (mTFW)", which represents the best-case expected price delivery, this is not your actual trade entry - exit range.
• 40 ticks for index futures or indices
• 15 pips for Forex pairs.
When on ' Strict/Super-Strict ' mode, only S/R lines will be shown which are:
• higher than the lowest FVG bottom + mTFW, in a bullish scenario
• lower than the highest FVG bottom - mTFW, in a bearish scenario
When on ' All FVG/Only FVG's in the same direction of trend ' mode, or on non-Forex/Futures/Indices symbols, S/R needs to be higher/lower than SB session high/low.
🔶 SETTINGS
(Check CONCEPTS for deeper insights and explanation)
🔹 Swing settings (left): Sets the length, which will set the lookback period/sensitivity of the Zigzag patterns (which directs the trend)
🔹 Silver Bullet Session; Show SB session: show lines and labels of SB session
Labels can be disabled separately in the ' Style ' section, color is set at the ' Inputs ' section.
🔹 FVG
– Mode
• All FVG
• Only FVG's in the same direction of trend
• Strict
• Super-Strict
– Colors
– Extend: extend till last bar of SB session
🔹 Targets – support/resistance lines
– Previous session (any): S/R lines fetched between current and previous SB session
– Previous session (similar): S/R lines fetched between current and previous similar SB session
– Colors
– Keep lines (only in strict mode)
🔹 Show
– MSS ~ Session: Show Market Structure Shift , only when this happens during a SB session
– Trend: Show trend (Zigzag, colored ~ trend)

90cycle @joshuuu90 minute cycle is a concept about certain time windows of the day.
This indicator has two different options. One uses the 90 minute cycle times mentioned by traderdaye, the other uses the cls operational times split up into 90 minutes session.
e.g. we can often see a fake move happening in the 90 minute window between 2.30am and 4am ny time.
The indicator draws vertical lines at the start/end of each session and the user is able to only display certain sessions (asia, london, new york am and pm)
For the traderdayes option, the indicator also counts the windows from 1 to 4 and calls them q1,q2,q3,q4 (q-quarter)
⚠️ Open Source ⚠️
Coders and TV users are authorized to copy this code base, but a paid distribution is prohibited. A mention to the original author is expected, and appreciated.
⚠️ Terms and Conditions ⚠️
This financial tool is for educational purposes only and not financial advice. Users assume responsibility for decisions made based on the tool's information. Past performance doesn't guarantee future results. By using this tool, users agree to these terms.

Nadaraya-Watson CombineThis is a combination of the Lux Algo Nadaraya-Watson Estimator and Envelope. Please note the repainting issue.
In addition, I've added a plot of the actual values of the current barstate of
the Nadaraya-Watson windows as they are computed (lines 92-95). It only plots values for the current data at
each time update. It is interesting to compare the trajectory of the end points of the Estimator and
Envelope to the smoothing function at each time update. Due to the kernel smoothing at each update the
history is lost at each update (repaint).
I've added a feature to allow adjustment to the kernel smoothing algorithm as suggested by thomsonraja (line 59).
The settings and usage are repeated from Lux Algo below.
Settings
Window Size: Determines the number of recent price observations to be used to fit the Nadaraya-Watson Estimator.
Bandwidth: Controls the degree of smoothness of the envelopes , with higher values returning smoother results.
Mult: Controls the envelope width.
Src: Input source of the indicator.
Kernel power: See line 59, adjusts the exponential power (powh) as suggested by thomsonraja
Kernel denominator: See line 59, adjusts the denominator (den) as suggested by thomsonraja
Usage
This tool outlines extremes made by the prices within the selected window size.
This is achieved by estimating the underlying trend in the price using kernel smoothing,
calculating the mean absolute deviations from it, and adding/subtracting it
from the estimated underlying trend.
I repeat Lux Algo's caution: 'we do not recommend this tool to be used alone
or solely for real time applications.'
z_scoreStand-alone Z-score indicator for volatile currency pairs, showing STRONG BUY, BUY, SELL, STRONG SELL zones.
The use can define their own "window" or moving average length, which will affect the frequency and magnitude of trades.
Higher windows reduce trade size but increase frequency and vice versa.
The suggested window values are intended for the daily time-frame. They are selected to maximise returns.
ETHBTC . 64 days.
SOLBTC . 40 days.
Trading decisions must be confirmed by multiple indicators and other factors.

getSeries█ OVERVIEW
This library is a Pine programmer’s tool containing functions that build an array of values meeting specific conditions. Its functions use concepts from our ConditionalAverages library , but instead of returning a single value, they return an array containing all the values meeting the conditions, which can then be processed as needed. This provides more flexibility to the programmer than a single value.
The "getSeries" name of the library stems from the fact that is uses arrays to build the equivalent of custom series which can then be operated on using array-specific functions in the `array.*` namespace, looped through using a for...in structure to implement custom logic, or sent to functions designed to process arrays such as those in these libraries: ArrayStatistics , ArrayOperations , arrayutils or Averages .
The eight examples illustrated in the library's code showcase the diversity of scenarios where the functions can be used.
Look first. Then leap.
█ FUNCTIONS
The library contains the following functions:
whenSince(src, whenCond, sinceCond, length)
Creates an array containing the `length` last `src` values where `whenCond` is true, since the last occurence of `sinceCond`.
Parameters:
src : (series int/float) The source of the values to be included.
whenCond : (series bool) The condition determining which values are included. Optional. The default is `true`.
sinceCond : (series bool) The condition determining when the accumulated series resets. Optional. The default is false, which will not reset.
length : (simple int) The number of last values to return. Optional. The default is all values.
Returns: (float ) The array ID of the accumulated `src` values.
rollOnTimeWhen(src, timeWindow, cond, minBars)
Creates an array of `src` values where `cond` is true, over a moving window of length `timeWindow` milliseconds.
Parameters:
src : (series int/float) The source of the values to be included.
timeWindow : (simple int) The time duration in milliseconds defining the size of the moving window.
cond : (series bool) The condition determining which values are included. Optional. The default is `true`.
minBars : (simple int) The minimum number of values to maintain in the moving window. Optional. The default is 1.
Returns: (float ) The array ID of the accumulated `src` values.
Note that the functions must be called on each bar to work correctly. They must thus be pre-evaluated before using their results in conditional branches.
Simple scalping strategy for SOLThis is a simple scalping strategy for trading SOL made on top of the Rebalance Oscillator and the Rebalance Bear/Bull market indicators.
It is intended mostly as proof that these two indicators have their benefits even in simpler strategies.
This strategy in particular works well for the Bear months (check Nov. in the data window) but considerably underperforms Buy&Hold for the Bull months.
It tries to do a market operation per candle whenever the candle happens in a buy/sell trading window of the
Rebalance Bear/Bull indicator ().
It always buys/sells the same amount by default (you can set it in the cog menu in the option "Base Crypto Amount To Trade"),
for SOL this is set to 1.0SOL.
This is my first attempt at scalping, it differs slightly from the standards because it does not require fast
response candles or immediate market operations (it can work well with limit trading) and on top of this it also
does not require a stop loss since it uses an indicator that provides the trading windows (surprises can still happen though).
The profit that this strategy tries to take for each buy/sell pair is not configurable and is set at 12% each way when it happens.

RedK Volume-Weighted Directional Efficiency Index (DXF)RedK Volume-Weighted Directional Efficiency Index (DXF) is a momentum indicator - that builds on Kaufman's Efficiency Ratio (ER) concept.
DXF utilizes a restricted +100/-100 oscillator to represent the "quality" of a trend, and does a good job in detecting the possibility of an upcoming trend change (in both direction and quality), improving our ability to make decisions on trade entries and exits.
Here's a quick background on Kaufman's Efficiency Ratio (ER)
------------------------------------------------------------------------------- Copied from internet sources -----------------------------
Developed by Perry Kaufman and introduced in his book “New Trading Systems and Methods”, the Efficiency Ratio reflects relative market speed to volatility. There are cases, when it is used as a filter, which helps a trader to avoid ”choppy” markets or trading ranges and to identify smoother trends.
ER is the result of dividing the net change in price movement during n-periods by the sum of all bar-to-bar price changes during the same n-periods. In case the market is trending smoother, then the ratio will be higher. In case the ratio shows readings in proximity to zero, this implies that market movement is inefficient and ”choppy”.
If the Efficiency Ratio shows a reading of +100, this means that the trading instrument is in a bull trend and trending with perfect efficiency.
If the Efficiency Ratio shows a reading of -100, this means that the trading instrument is in a bear trend and trending with perfect efficiency.
It is impossible for any instrument to have a perfect Efficiency ratio, because any movement against the major trend during the examined period of time would cause the ratio to drop.
If the Efficiency Ratio shows a reading above +30 (common setting for the "Significant Level"), this is indicative of a quality bull trend. If the ratio shows a reading below -30, this is indicative of a quality bear trend.
------------------------------------------------------------------------------- End of Copy -------------------------------------------------------------------------------------------------------
Kaufman also used the ER as basis for his famous Kaufman Adaptive Moving Average (KAMA).
Read more on ER & Kama here
How is DXF different from other ER-based indicators?
------------------------------------------------------------------
- Let's get the easy part out of the way: DXF has a "volume-weighting" option ✔
This option is OFF by default (to avoid errors with instruments with no volume data)
- once this option is applied, it provides the benefit of combining the volume effect into the calculation - those who appreciate the effect of volume on price action will hopefully find this option valuable
- The calculation of ER and how it can be "best utilized":
Let's examine the ER concept a bit closer: as a (math) concept, the (original) Efficiency Ratio (ER) takes the positive change of the price of an instrument during a certain period, and divide it by the sum of (absolute) price moves that were observed during that same period.
So, in the trader's language, we will be saying "out of a total of $20 moves (up and down) that MSFT did in the past 10 days, MSFT only made a net change of $5 up during that period" - so the "10-day ER" for MSFT in that case is 5/20 = 25% -- then we continue to observe that ongoing "10-day ER" and if it increases, we can expect that MSFT is going to establish a strong move (trend) up --- right?
the magic word here is to "observe the ongoing ER" - many of the ER based indicators just use the ER as calculated by Kaufman's original method. IMHO, these are just "point-in-time readings" - if we hope to get real insights from the ER, we need to take an average of that reading - for our "time window" we're interested in - and only then we can identify trends and patterns in the ER value as it changes during that windowss- DXF does that - and that allows a trader to say "the (weighted) 5-day average of the 10-day ER for MSFT is increasing, and that why i expect an up-trend" -- makes sense ? both the "Lookback" used to calculate the ER, and the Length of observed "window" for the Average ER are adjustable in DXF settings
Other Uses and Settings :
---------------------------------
- As a momentum indicator, DXF can predict an upcoming change of trend - cause that will reflect on the average ER value. There are few examples in the chart where the price move and ER trend *do not agree* - The trader can see these signs and take decisions accordingly
- DXF can help reveal best entries and exits: assume we are long-term bullish on MSFT, and we want to "buy the dip" - DXF can help reveal the time where price is recovering from extreme weakness - and that would be the ideal buy opportunities for us - exampled marked on the chart
- the Stepping & Smoothing options enable better visualization of the DXF plot. the "raw" DXF is still shown as a silver line.
- The "Significant Levels" option is available and is set to -20/+20 by default .. also adjustable in indicator settings.
- Please use DXF in combination with other trend and volume indicators, and with thorough chart / price action analysis and not in isolation to ensure you get proper signal confirmation for trades. In the chart above, you can see DXF combined with a moving average that can act as a filter and to confirm the price moves.
---------------------------------------------------
As usual, feedback & comments are welcome - if you find this work useful in your trading arsenal, please share a comment - i would be more than happy to learn about that. Good luck!

KLemurs DeviationMarket: Stocks and ETF's
This overlay shows the deviation of the exponential moving average of the mid candle price of the currently loaded chart, away from the exponential moving average of the S&P and DOW combined and averaged mid candle price. The top and bottom lines also give a visual perspective of what a certain percentage (default 1%) looks like on the current charts window. This may help with making quick decisions for things like setting trailing stop trades with a percentage. This can be used for stocks, ETF's, and index's and It may be useful in finding potential stocks or ETF's if you are interested in these kinds of deviations. Defaults are set for a dark screen but can be edited to your taste. It's optimized to be an overlay on the current chart window as opposed to being a separate window.
Percentage Lines (editable)
This is three lines. The upper line (default green) plots the set percentage (default 1%) above the current chart’s ema. The middle line (default white) plots the current chart’s ema. The lower line (default red) plots the set percentage (default 1%) below the current chart’s ema.
Deviation Band (editable)
This is the colored band on the overlay between the upper and lower percentage lines. The band’s fill color indicates the deviation of the current charts ema from the ema of the combined S&P and DOW’s ema as follows:
- Red (default) = Current Chart’s ema is descending and the S&P/DOW ema is descending OR the Current Chart’s ema is below (underperforming) the S&P/DOW ema.
- Orange (default) = The Current Chart and S&P/DOW ema’s are both either ascending or descending together.
- Green (default) = The Current Chart’s ema is ascending but the S&P/DOW ema is descending.
To Set Line Colors
BY default, the upper line color uses the same colors as the ascending band color and the lower line uses the same color as the descending band color. To set the line colors, see "plotColor", "plotColorUp", or" plotColorDown" in variable settings within the script or use the “Central Plot Line”, “Upper Plot Line, or “Lower Plot Line” in the input dialogue to change this.
To Set Band Colors
To set the band colors, see "plotColor", "plotColorUp", or "plotColorDown" in variable settings within the script or use the “Color0”, “Color1", or “Color2” in the input dialogue to change this.
To Set EMA Lookback Period
The ema lookback period defaults to 5. This is the number of candles back that the script will use to determine the ema. See “CCemaN” in variable settings within the script or use the “EMA Period” in the input dialogue to change this.
To Set Percentage
To set the percentage that plots the upper and lower lines, see "CCP" in variable settings within the script or use “Upper/Lower Bands Percentage” in the input dialogue to change this. The default is .01 (or 1%).