GKD-C 3rd Generation MA [Loxx]Giga Kaleidoscope 3rd Generation MA is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: 3rd Generation MA as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ 3rd Generation MA
What is 3rd Generation MA?
3rd Generation MA is moving average cross indicator. This takes an initial moving average, applies double smoothing, and then adjusts the moving average by an alpha and lambda factor.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
Cerca negli script per "algo"
GKD-C Kalman Filter [Loxx]Giga Kaleidoscope Kalman Filter is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Kalman Filter as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
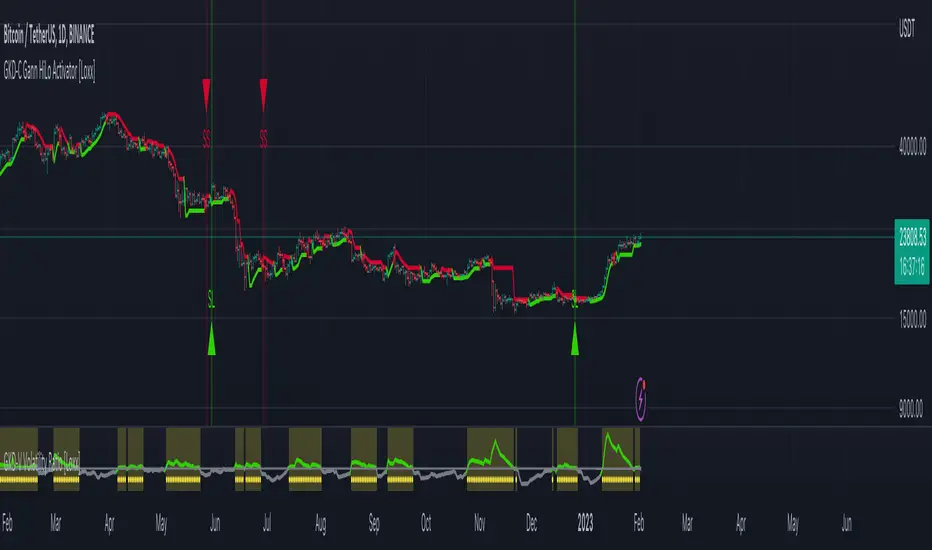
█ Kalman Filter
What is Kalman Filter?
Kalman filter is an algorithm that uses a series of measurements observed over time, containing statistical noise and other inaccuracies. This means that the filter was originally designed to work with noisy data. Also, it is able to work with incomplete data. Another advantage is that it is designed for and applied in dynamic systems; our price chart belongs to such systems. This version is true to the original design of the trade-ready Kalman Filter where velocity is the triggering mechanism.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C WYFX Clear Chart [Loxx]Giga Kaleidoscope WYFX Clear Chart is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: WYFX Clear Chart as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ WYFX Clear Chart
What is WYFX Clear Chart?
WYFX Clear Chart a variation of Heiken-Ashi candles that uses 62 different types of smoothing.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
GKD-C MA Crossover [Loxx]Giga Kaleidoscope MA Crossover is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: MA Crossover as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ MA Crossover
What is MA Crossover?
MA Crossover is a combination of a 2 MA crosses and a stepping filter. This contains 62 different types of moving averages.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
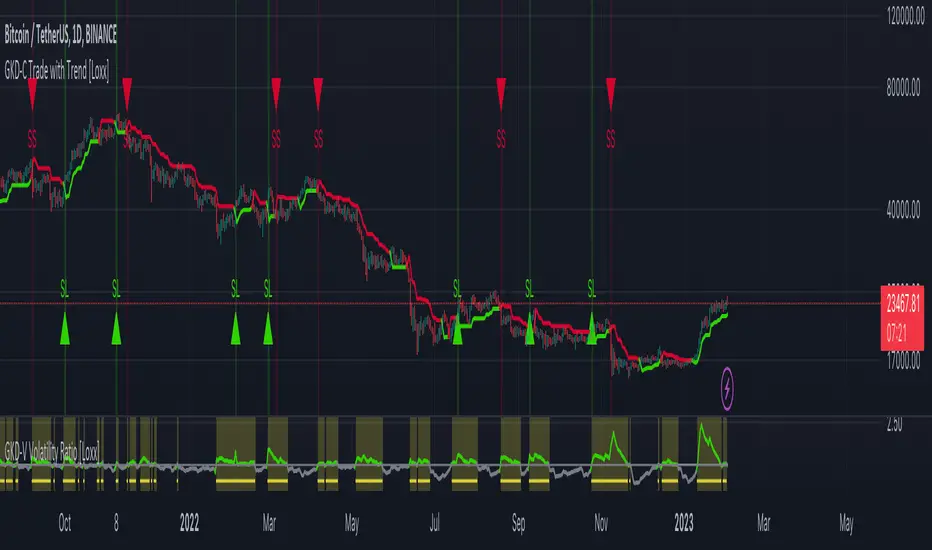
GKD-C Trade with Trend [Loxx]Giga Kaleidoscope Trade with Trend is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Trade with Trend as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Trade with Trend
What is Trade with Trend?
Trade with trend is like Supertrend but more advanced. Trend flips occur with multiples of ATR and comparison of high/low values.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
GKD-C Recursive Moving Average [Loxx]Giga Kaleidoscope Recursive Moving Average Averages is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Recursive Moving Average Averages as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Recursive Moving Average Averages
What is Recursive Moving Average Averages?
Dennis Meyers's Recursive Moving Trendline uses a recursive (repeated application of a rule) polynomial fit, a technique that uses a small number of past values estimations of price and today's price to predict tomorrow's price.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Coral [Loxx]Giga Kaleidoscope Coral Averages is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Coral Averages as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Coral Averages
What is Coral Averages?
Coral is a modified version of T3 moving average. The T3 moving average is an indicator of an indicator since it includes several EMAs of another EMA. Unlike any other moving average, it adds the so-called volume factor, a value between 0 and 1. Like the SMA, traders typically use this indicator to spot trends and trend reversals.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Gann HiLo Activator [Loxx]Giga Kaleidoscope Gann HiLo Activator Averages is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Gann HiLo Activator Averages as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Gann HiLo Activator Averages
What is Gann HiLo Activator Averages?
Developed by Robert Krausz, the Gann HiLo Activator is a trend-following technical indicator used to help determine the trends direction and to generate with-trend entry signals. It is best combined with the Gann Swing Indicator and the Gann Trend Indicator (will be reviewed in the following articles) as part of a trading system, commonly known as the “New Gann Swing Chartist Plan”.
The Gann HiLo Activator is a simple moving average of the previous three periods highs or lows. Based on the moving averages logic, it is a trend-following indicator used to reflect the markets direction of movement. Within the trading system we mentioned earlier, the Gann HiLo activator is responsible for generating entry signals, but also helps determine stop-loss levels. Here is how it looks in a trading platform.
This version has 62 Moving Averages to choose from.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
GKD-C Semaphore Signal Level (SSL) Averages [Loxx]Giga Kaleidoscope Semaphore Signal Level (SSL) Averages is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Semaphore Signal Level (SSL) Averages as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Semaphore Signal Level (SSL) Averages
What is Semaphore Signal Level (SSL) Averages?
As you've probably noticed, there's already a ton of technical indicators out there, and here's yet another one, which recently popped up on our radar.
Known as the SSL, the Semaphore Signal Level channel chart alert is an indicator that combines moving averages to provide you with a clear visual signal of price movement dynamics. In short, it's designed to show you when a price trend is forming.
To do this, it shows you two different-colored lines that follow the evolution of prices. The indicator is typically on your existing chart, but there are also non-chart versions. It all depends on your preferences: do you prefer your chart to be clean and simple and your indicators to appear separately in another window or do you want everything displaying in one place, which makes cross-referencing easier? Also, as SSLs are designed as an overlay indicator, if you go for a non-chart version, you need to make sure that it performs as intended.
When the two lines intersect, the indicator signals that the price movement is changing direction or is about to. When you add SSL to your trading platform, you have the option of choosing the color of the lines - be sure to choose colors that don't conflict with other indicator lines that you use! Having a cluttered chart can be bad enough without having to squint to see colors that are too similar or cancel each other out.
In addition, SSLs include alerts. It depends a bit on how you want to trade, but I recommend that you turn off these alerts, especially when you have a good idea of how the indicator works and what you want to do with it. There's another reason why turning off alerts is probably better. This is because the indicator can give you false signals when the price swings before a candle closes. You would then risk receiving alerts before you can actually use them, which could confuse or mislead you. Many technical traders who use indicators will advise you to wait for a candle to close before acting on a signal from your indicator (including SSLs).
This verion has 62 Moving Averages to choose from.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C ASC Trend [Loxx]Giga Kaleidoscope ASC Trend is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: ASC Trend as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ ASC Trend
What is ASC Trend?
ASC Trend uses Williams Precent Range and a High/Low comparison to derive price trend. This indicator is hard to see on the chart, so you'll likely want to turn off Baseline and other overlay indicators to see it' however, you can clearly the signals painted on the chart either way.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Top Trend [Loxx]Giga Kaleidoscope Top Trend is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Top Trend as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Top Trend
What is Top Trend?
Top Trend is a trend following indicator that signals breakouts and plots dynamic support and resistance levels.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Variety MA Supertrend [Loxx]Giga Kaleidoscope Variety MA Supertrend is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Variety MA Supertrend as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Variety MA Supertrend
What is Variety MA Supertrend?
Supertrend indicator was created by Olivier Seban to work on different time frames. It works for futures, forex, and equities. It is used in 15 minutes, hourly, weekly, and daily charts. Based on the parameters of multiplier and period, the indicator uses 3 for multiplier and 7 for ATR as default values. Average True Range is represented by the number of days while the multiplier is the value by which the range is multiplied. This version smooths the Supertrend with the option of 62 different smoothing methods.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
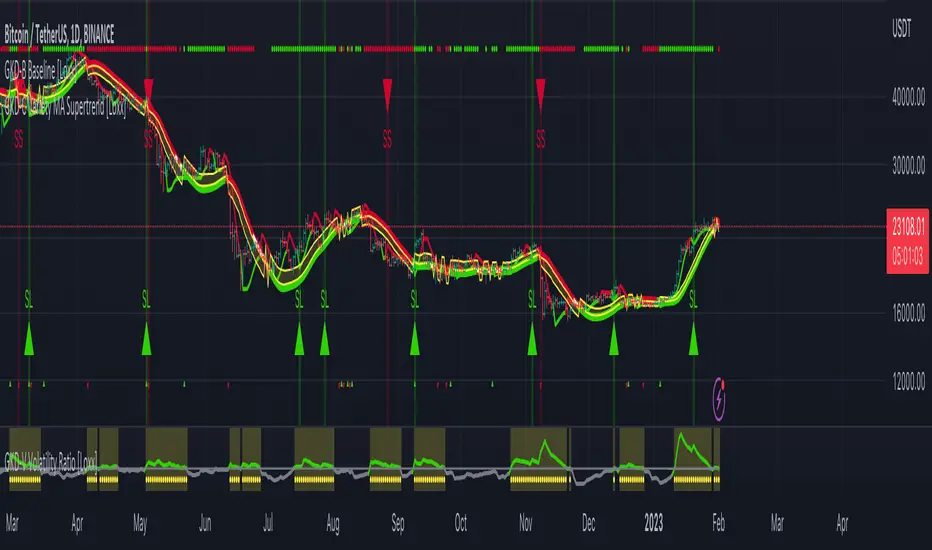
GKD-C Bollinger Bands Stop [Loxx]Giga Kaleidoscope Bollinger Bands Stop is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Bollinger Bands Stop as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Bollinger Bands Stop
What is Bollinger Bands Stop?
Bollinger Bands Stop is similar to Supertrend but uses Standard Deviation instead of ATR. includes a money risk and signal adjustment to fine-tune the signal. This can be used for TPs and SL as well as up/down trading.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C VKW Bands [Loxx]Giga Kaleidoscope VKW Bands is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: VKW Bands as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ VKW Bands
What is VKW Bands?
VKW Bands is a similar a momentum indicator with a stepping adjustment and smoothing. There are 6+ types of RSI inside, 62 different smoothing types, and 30+ source types. You can choose from levels or middle cross for the signal output.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
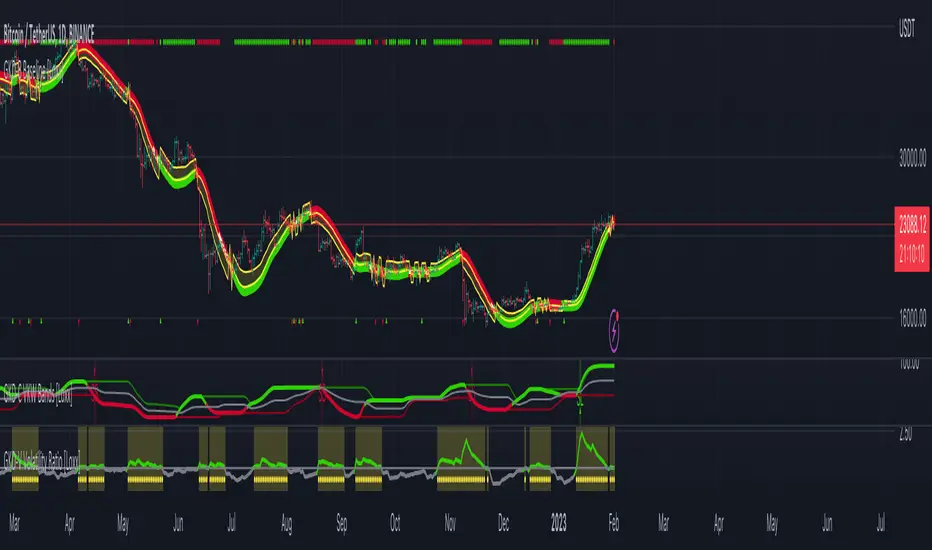
GKD-C Braid Filter [Loxx]Giga Kaleidoscope Braid Filter is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Braid Filter as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Braid Filter
What is Braid Filter?
Braid Filter was created by Robert Hill . It first appeared in an issue of Stocks and Commodities Magazine in 2006.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C uf2018 [Loxx]Giga Kaleidoscope uf2018 is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: uf2018 as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ uf2018
What is uf2018?
uf2018 (advanced) Backtest is a trend following indicator that compares current high and low with XX bars back highest and lowest to detect changes in market structure
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C ATR-Adaptive, Smoothed Laguerre RSI [Loxx]Giga Kaleidoscope ATR-Adaptive, Smoothed Laguerre RSI is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: ATR-Adaptive, Smoothed Laguerre RSI as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ ATR-Adaptive, Smoothed Laguerre RSI
What is ATR-Adaptive, Smoothed Laguerre RSI?
ATR-Adaptive, Smoothed Laguerre RSI is an adaptive Laguerre RSI indicator with smoothing to reduce noise. The Laguerre RSI indicator created by John F. Ehlers is described in his book "Cybernetic Analysis for Stocks and Futures". For this version, Instead of using fixed periods for Laguerre RSI calculation, this indicator uses an ATR ( average True Range ) adapting method to adjust the calculation period. This makes the RSI more responsive in some periods (periods of high volatility ), and smoother in order periods (periods of low volatility). There are two signal types: middle and levels.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Bears Bull Impulse [Loxx]Giga Kaleidoscope Bears Bull Impulse is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Bears Bull Impulse as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Bears Bull Impulse
What is Bears Bull Impulse?
Many oscillators attempt to measure how much buying or selling power lies behind price moves in a financial market. Many do this by means of a single indicator that gauges momentum, both bullish and bearish . Some well-known trading indicators that work this way include the Relative Strength Index , the Force Index , and the Money Flow Index. There is another indicator though, known as the Elder-Ray Index, that attempts to gauge bullish and bearish forces in the market by using two separate measures, one for each type of directional pressure. The technique was developed by Dr Alexander Elder, and the two indicators involved are called 'Bulls Power' and 'Bears Power'. Alas, this is where the Bull and Bear Power indicators come into play.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Larry Williams Proxy Index [Loxx]Giga Kaleidoscope Larry Williams Proxy Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Larry Williams Proxy Index as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Larry Williams Proxy Index
What is Larry Williams Proxy Index ?
Larry Williams Proxy Index also known as the Larry Williams COT (Commitment of Traders) Proxy Index. This is a popular indicator among the Forex community created by the famous trader Larry Williams . This is an inverse oscillator so the longs happen below the middle line, and shorts happen above. This is an inverse indicator. Over zeroline is short, under is long.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Alaskan Pip Assassin [Loxx]Giga Kaleidoscope Alaskan Pip Assassin is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Alaskan Pip Assassin as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Alaskan Pip Assassin
What is Alaskan Pip Assassin?
Alaskan Pips Assassin aka Super Signals is a trend indicator that exploits differences between high and low price values to determine trend breakouts and breakdowns. This version along with it's backtest are non-repainting.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.

GKD-C Detrended Synthetic Price Oscillator [Loxx]Giga Kaleidoscope Detrended Synthetic Price Oscillator is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Detrended Synthetic Price Oscillator as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Detrended Synthetic Price Oscillator
What is Detrended Synthetic Price Oscillator?
A detrended price oscillator, used in technical analysis, strips out price trends in an effort to estimate the length of price cycles from peak to peak or trough to trough. Unlike other oscillators, such as the stochastic or moving average convergence divergence (MACD), the DPO is not a momentum indicator. This inclucdes two types of signals: middle cross or levels cross.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
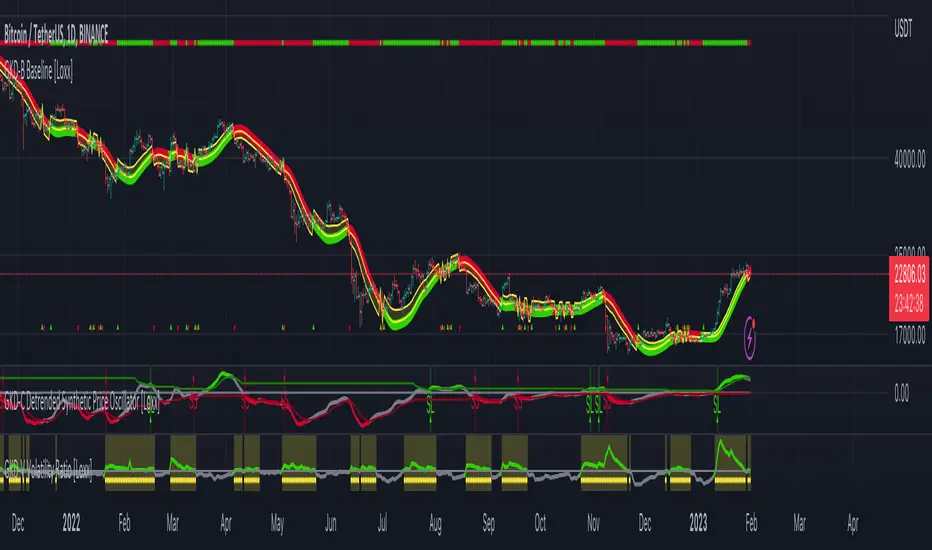
GKD-C Ease of Movement [Loxx]Giga Kaleidoscope Ease of Movement is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Ease of Movement as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Ease of Movement
What is Ease of Movement?
The Ease of Movement indicator is a volume based oscillator. It is designed to measure the relationship between price and volume and display that relationship as an oscillator that fluctuates between positive and negative values. The EOM fluctuates above and below a Zero Line. This is done in order to quantify the "ease" of price movements. A basic understanding is that when the EOM is in positive territory, prices are advancing with relative ease. When the EOM is negative, prices are declining with relative ease.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
GKD-C Momentum Breakout Bands [Loxx]Giga Kaleidoscope Momentum Breakout Bands is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Momentum Breakout Bands as shown on the chart above
Confirmation 2: Williams Percent Range
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Momentum Breakout Bands
What is Momentum Breakout Bands?
Momentum Breakout Bands is a momentum oscillator with Bollinger Bands to filter noise by standard deviation. This is used for breakout trading and can be used on lower timeframes.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.