GKD-C Trading Channel Index [Loxx]Giga Kaleidoscope Trading Channel Index is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends.
4. Confirmation 2 - a technical indicator used to identify trends.
5. Continuation - a technical indicator used to identify trends.
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
7. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average as shown on the chart above
Volatility/Volume: Average Directional Index (ADX) as shown on the chart above
Confirmation 1: Trading Channel Index as shown on the chart above
Confirmation 2: Jurik Turning Point Oscillator
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Trading Channel Index
What is Trading Channel Index
The Trading Channel Index measures the location of average daily price relative to a smoothed average of average daily price. It is derived from the average difference between these two values.
Requirements
Inputs
Confirmation 1 and Solo Confirmation: GKD-V Volatility / Volume indicator
Confirmation 2: GKD-C Confirmation indicator
Continuation: GKD-C Confirmation indicator
Outputs
Confirmation 2 and Solo Confirmation: GKD-E Exit indicator
Confirmation 1: GKD-C Confirmation indicator
Continuation: GKD-E Exit indicator
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
Cerca negli script per "algo"

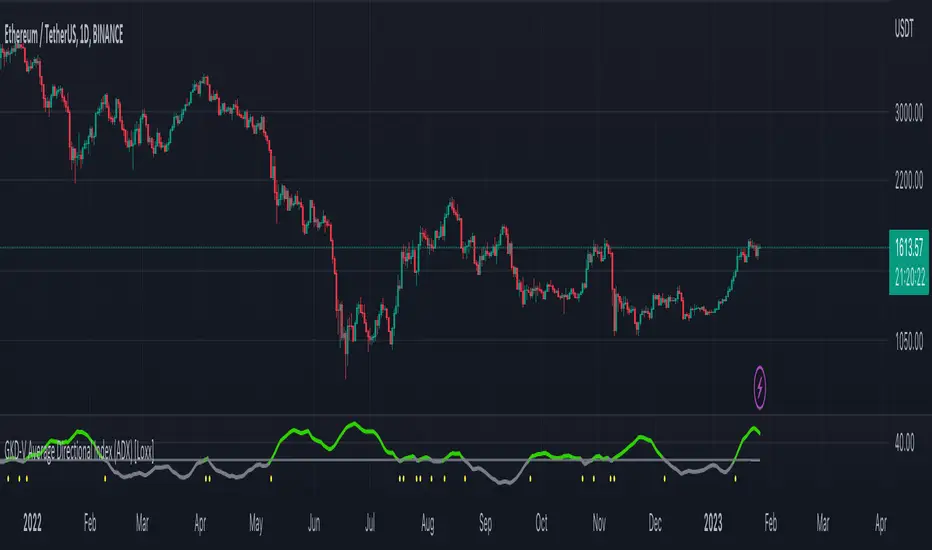
GKD-V Average Directional Index (ADX) [Loxx]Giga Kaleidoscope Average Directional Index (ADX) is a Volatility/Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends.
4. Confirmation 2 - a technical indicator used to identify trends.
5. Continuation - a technical indicator used to identify trends.
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
7. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average
Volatility/Volume: Average Directional Index (ADX) as shown on the chart above
Confirmation 1: Double Smoothed Stochastic of Momentum
Confirmation 2: Jurik Turning Point Oscillator
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Average Directional Index (ADX)
What is Average Directional Index (ADX)
Trading in the direction of a strong trend reduces risk and increases profit potential. The average directional index (ADX) is used to determine when the price is trending strongly. In many cases, it is the ultimate trend indicator. After all, the trend may be your friend, but it sure helps to know who your friends are.
ADX is used to quantify trend strength. ADX calculations are based on a moving average of price range expansion over a given period of time. The default setting is 14 bars, although other time periods can be used. ADX can be used on any trading vehicle such as stocks, mutual funds, exchange-traded funds and futures.
ADX is plotted as a single line with values ranging from a low of zero to a high of 100. ADX is non-directional; it registers trend strength whether price is trending up or down. The indicator is usually plotted in the same window as the two directional movement indicator (DMI) lines, but for our purposes here, we are only concerned with the ADX itself.
Signals
Traditional: ADX is above the threshold cutoff; both longs/shorts triggered when ADX is above the threshold cutoff
Crossing: ADX crosses above/below the threshold cutoff; longs or shorts are only valid on the candle where the cross happens. Both cross-ups and cross-downs are valid for both shorts and longs
Signal Modifiers
X-Bar Rule: If signals occur within XX bars, then the signal is still valid
Bars Rising: This is for traditional signals only. This requires that an upward slop of ADX be present over XX bars
Other things to note
The GKD trading system requires that a GKD-V indicator be present in the indicator chain, but the GKD-V indicator doesn't need to be active. You can turn on/off the Volatility Ratio as you wish so you can backtest your trading strategy with the filter on or off.
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
GKD-V Loxx Volty [Loxx]Giga Kaleidoscope Loxx Volty is a Volatility/Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends.
4. Confirmation 2 - a technical indicator used to identify trends.
5. Continuation - a technical indicator used to identify trends.
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
7. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average
Volatility/Volume: Loxx Volty as shown on the chart above
Confirmation 1: Double Smoothed Stochastic of Momentum
Confirmation 2: Jurik Turning Point Oscillator
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Loxx Volty
What is Loxx Volty
One of the lesser known qualities of Loxx smoothing is that the Loxx smoothing process is adaptive. "Loxx Volty" (a sort of market volatility) is what makes Loxx smoothing adaptive. The Loxx Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
Other things to note
The GKD trading system requires that a GKD-V indicator be present in the indicator chain, but the GKD-V indicator doesn't need to be active. You can turn on/off the Volatility Ratio as you wish so you can backtest your trading strategy with the filter on or off.
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.

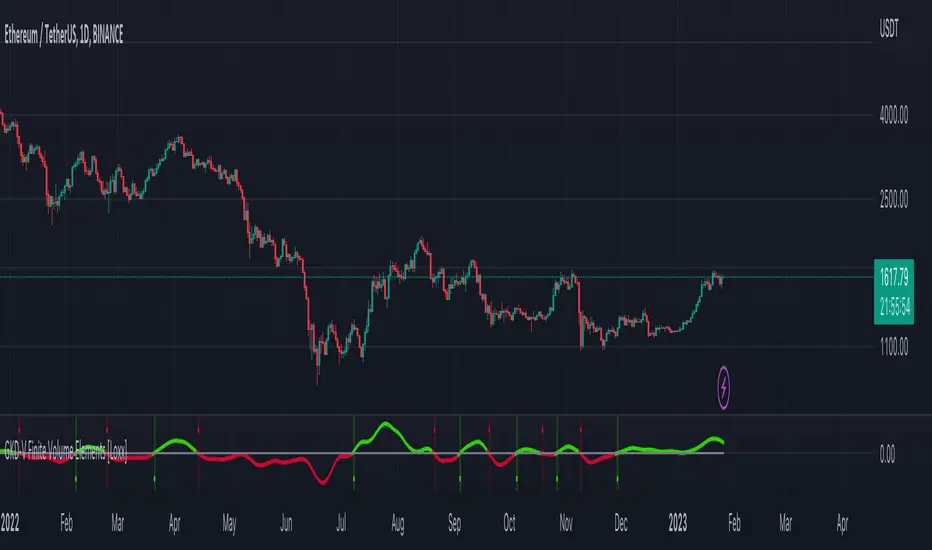
GKD-V Finite Volume Elements [Loxx]Giga Kaleidoscope Finite Volume Elements is a Volatility/Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
█ Giga Kaleidoscope Modularized Trading System
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends.
4. Confirmation 2 - a technical indicator used to identify trends.
5. Continuation - a technical indicator used to identify trends.
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
7. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-C(Continuation) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average
Volatility/Volume: Finite Volume Elements as shown on the chart above
Confirmation 1: Double Smoothed Stochastic of Momentum
Confirmation 2: Jurik Turning Point Oscillator
Continuation: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Giga Kaleidoscope Modularized Trading System Signals (based on the NNFX algorithm)
Standard Entry
1. GKD-C Confirmation 1 Signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
6. GKD-C Confirmation 1 signal was less than 7 candles prior
Continuation Entry
1. Standard Entry, Baseline Entry, or Pullback; entry triggered previously
2. GKD-B Baseline hasn't crossed since entry signal trigger
3. GKD-C Confirmation Continuation Indicator signals
4. GKD-C Confirmation 1 agrees
5. GKD-B Baseline agrees
6. GKD-C Confirmation 2 agrees
1-Candle Rule Standard Entry
1. GKD-C Confirmation 1 signal
2. GKD-B Baseline agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume agrees
1-Candle Rule Baseline Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
4. GKD-C Confirmation 1 signal was less than 7 candles prior
Next Candle:
1. Price retraced (Long: close < close or Short: close > close )
2. GKD-B Baseline agrees
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
PullBack Entry
1. GKD-B Baseline signal
2. GKD-C Confirmation 1 agrees
3. Price is beyond 1.0x Volatility of Baseline
Next Candle:
1. Price is within a range of 0.2x Volatility and 1.0x Volatility of the Goldie Locks Mean
3. GKD-C Confirmation 1 agrees
4. GKD-C Confirmation 2 agrees
5. GKD-V Volatility/Volume Agrees
█ Finite Volume Elements
What is Finite Volume Elements
The Finite Volume Element Indicator ( FVE ) was developed by Markos Katsanos and introduced in the April 2003 issue of Technical Analysis of Stocks & Commodities magazine. It was modified for volatility in the September 2003 issue of TASC.
FVE is a money flow indicator but with two important differences from existing money flow indicators:
It resolves contradictions between intraday money flow indicators (such as Chaikin’s money flow ) and intraday money flow indicators (like On Balance Volume ) by taking into account both intra- and intraday price action.
Unlike other money flow indicators which add or subtract all volume even if the security closed just 1 cent higher than the previous close, FVE uses a volatility threshold to take into account minimal price changes
Other things to note
The GKD trading system requires that a GKD-V indicator be present in the indicator chain, but the GKD-V indicator doesn't need to be active. You can turn on/off the Volatility Ratio as you wish so you can backtest your trading strategy with the filter on or off.
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
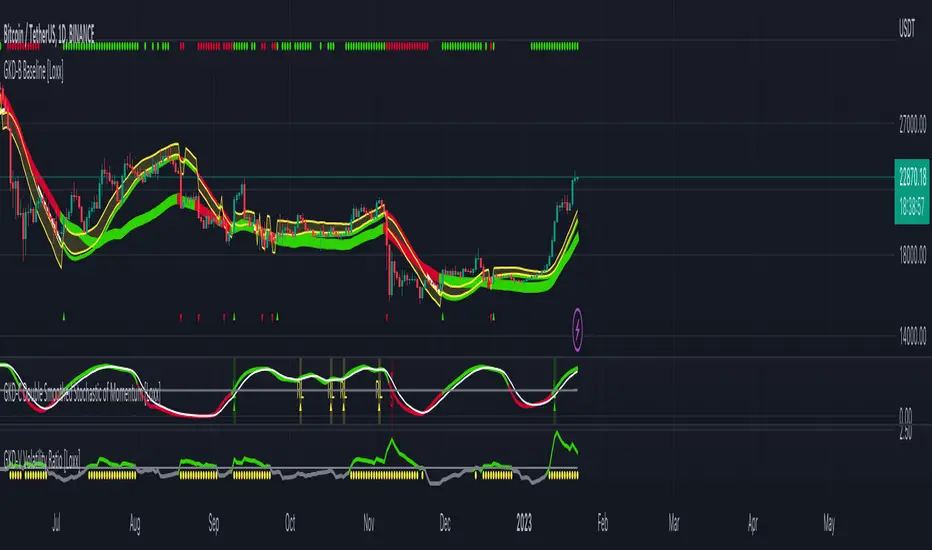
GKD-C Double Smoothed Stochastic of Momentum [Loxx]Giga Kaleidoscope Double Smoothed Stochastic of Momentum Confirmation is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average as shown on chart
Volatility/Volume: Volatility Ratio as shown on chart
Confirmation 1: Double Smoothed Stochastic of Momentum as shown on the chart above
Confirmation 2: Jurik Turning Point Oscillator
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-E Double Smoothed Stochastic of Momentum itself.
What is Double Smoothed Stochastic of Momentum?
The Double Smoothed Stochastic of Momentum demonstrates smoother indicators and therefore gives fewer false signals in comparison with the traditional oscillator.
The indicator is written in accordance with the description given in the book by Joe Dinapoli "Trading With DiNapoli Levels". This oscillator smoothing method leads to a filtering of the most "noise" component of the price movement.
The Double Smoothed Stochastic of Momentum indicator can be used in the strategies oriented to a standard stochastic. However, the stronger smoothing can lead to the loss of an array of signals. It is recommended to apply any trend indicator for more efficient use of the indicator and its signals filtering.
Signals
A GKD-C Confirmation indicator can be used as either a Confirmation 1, Confirmation 2, or Solo Confirmation indicator. See step 3 & 4 of the NNFX algorithm above to understand how this indicator fits into the GKD trading system. The Solo Confirmation setting allows you to test this indicator by itself without an additional GKD-C indicator present in the GKD protocol chain.
On the chart shown above, this indicator is shown as GKD-C Double Smoothed Stochastic of Momentum and is set to Solo Confirmation. The GKD-B Baseline, GKD-V Volatility Ratio, and this indicator satisfy the first three steps in the GKD trading system chain: GKD-B => GKD-V => GKD-C(solo).
The signals from each of these settings are as follows:
Confirmation 1 Signal
Initial Long (L): Double Smoothed Stochastic of Momentum crosses-up over middle-line*
Initial Short (S): Double Smoothed Stochastic of Momentum crosses-down under middle-line*
Continuation Long (CL): Double Smoothed Stochastic of Momentum is over middle-line, then crosses-up over the signal**
Continuation Short (CS): Double Smoothed Stochastic of Momentum is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Double Smoothed Stochastic of Momentum crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Double Smoothed Stochastic of Momentum crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Double Smoothed Stochastic of Momentum is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Double Smoothed Stochastic of Momentum crosses-up over the signal****
BL Recovery Continuation Short (RS): Double Smoothed Stochastic of Momentum is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Double Smoothed Stochastic of Momentum crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the Double Smoothed Stochastic of Momentum then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Signal
Initial Long (L): Double Smoothed Stochastic of Momentum crosses-up over middle-line*
Initial Short (S): Double Smoothed Stochastic of Momentum crosses-down under middle-line*
Continuation Long (CL): Double Smoothed Stochastic of Momentum is over middle-line, then crosses-up over the signal**
Continuation Short (CS): Double Smoothed Stochastic of Momentum is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Double Smoothed Stochastic of Momentum crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Double Smoothed Stochastic of Momentum crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Double Smoothed Stochastic of Momentum is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic of Momentum is still above middle-line; then, Double Smoothed Stochastic of Momentum crosses-up over the signal****
BL Recovery Continuation Short (RS): Double Smoothed Stochastic of Momentum is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic of Momentum is still below middle-line; then, Double Smoothed Stochastic of Momentum crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the Double Smoothed Stochastic of Momentum then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then Double Smoothed Stochastic of Momentum crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then Double Smoothed Stochastic of Momentum crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Continuation Long Confirmation 1 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 1 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-up over middle-line but Baseline is still in downtrend; and Double Smoothed Stochastic of Momentum crossed-up over middle-line on the same bar or XX bars in the future but Baseline is still in downtrend; then Baseline turns to uptrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic of Momentum crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic of Momentum is still above middle-line; then, The imported GKD-C Confirmation 1 crosses-up over the signal
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic of Momentum is still below middle-line; then, The imported GKD-C Confirmation 1 crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 2
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): Double Smoothed Stochastic of Momentum is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 2 (CS): Double Smoothed Stochastic of Momentum is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): Double Smoothed Stochastic of Momentum is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Double Smoothed Stochastic of Momentum crosses-up over the signal
BL Recovery Continuation Short (RS): Double Smoothed Stochastic of Momentum is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Double Smoothed Stochastic of Momentum crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Both
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal; Double Smoothed Stochastic of Momentum is over middle-line, then crosses-up over the signal within "Number of Bars Confirmation" bars in the future
Continuation Short Confirmation 2 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal; Double Smoothed Stochastic of Momentum is under middle-line, then crosses-down under the signal within "Number of Bars Confirmation" bars in the future
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line and Double Smoothed Stochastic of Momentum is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, the imported GKD-C Confirmation 1 crosses-up over its signal, and Double Smoothed Stochastic of Momentum crosses-up over its signal within "Number of Bars Confirmation" bars in the future
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line and Double Smoothed Stochastic of Momentum is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, the imported GKD-C Confirmation 1 crosses-down under its signal, and Double Smoothed Stochastic of Momentum crosses-down under its signal within "Number of Bars Confirmation" bars in the future
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Both; Confirmation Type: (continuations don't change from the variations above)
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then Double Smoothed Stochastic of Momentum crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Double Smoothed Stochastic of Momentum crosses-up over middle-line, then the imported GKD-C Confirmation 1 indicator crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then Double Smoothed Stochastic of Momentum crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Double Smoothed Stochastic of Momentum crosses-down under middle-line, then the imported GKD-C Confirmation 1 indicator crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic of Momentum crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Double Smoothed Stochastic of Momentum crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic of Momentum crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Double Smoothed Stochastic of Momentum crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Solo Confirmation Signals
Initial Long (L): Double Smoothed Stochastic of Momentum crosses-up over middle-line
Initial Short (S): Double Smoothed Stochastic of Momentum crosses-down under middle-line
Continuation Long (CL): Double Smoothed Stochastic of Momentum is over middle-line, then crosses-up over the signal
Continuation Short (CS): Double Smoothed Stochastic of Momentum is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): Double Smoothed Stochastic of Momentum crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars
Post Baseline Cross Short (BS): Double Smoothed Stochastic of Momentum crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars
BL Recovery Continuation Long (RL): Double Smoothed Stochastic of Momentum above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic of Momentum is still above middle-line
BL Recovery Continuation Short (RS): Double Smoothed Stochastic of Momentum below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic of Momentum is still below middle-line
X-bar Rule settings
This rule only applies when this indicator "Confirmation Type" set to "Confirmation 2"
Requirements
Inputs: Confirmation 1 and Solo Confirmation: GKD-V Volatility/Volume indicator; Confirmation 2: GKD-C Confirmation indicator
Output: Confirmation 2 and Solo Confirmation: GKD-E Exit indicator; Confirmation 1: GKD-C Confirmation indicator
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
GKD-C Double Smoothed Stochastic [Loxx]Giga Kaleidoscope Double Smoothed Stochastic Confirmation is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average as shown on chart
Volatility/Volume: Volatility Ratio as shown on chart
Confirmation 1: Double Smoothed Stochastic as shown on the chart above
Confirmation 2: Jurik Turning Point Oscillator
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-E Double Smoothed Stochastic itself.
What is Double Smoothed Stochastic?
The Double Smoothed Stochastic demonstrates smoother indicators and therefore gives fewer false signals in comparison with the traditional oscillator.
The indicator is written in accordance with the description given in the book by Joe Dinapoli "Trading With DiNapoli Levels". This oscillator smoothing method leads to a filtering of the most "noise" component of the price movement.
The Double Smoothed Stochastic indicator can be used in the strategies oriented to a standard stochastic. However, the stronger smoothing can lead to the loss of an array of signals. It is recommended to apply any trend indicator for more efficient use of the indicator and its signals filtering.
Signals
A GKD-C Confirmation indicator can be used as either a Confirmation 1, Confirmation 2, or Solo Confirmation indicator. See step 3 & 4 of the NNFX algorithm above to understand how this indicator fits into the GKD trading system. The Solo Confirmation setting allows you to test this indicator by itself without an additional GKD-C indicator present in the GKD protocol chain.
On the chart shown above, this indicator is shown as GKD-C Double Smoothed Stochastic and is set to Solo Confirmation. The GKD-B Baseline, GKD-V Volatility Ratio, and this indicator satisfy the first three steps in the GKD trading system chain: GKD-B => GKD-V => GKD-C(solo).
The signals from each of these settings are as follows:
Confirmation 1 Signal
Initial Long (L): Double Smoothed Stochastic crosses-up over middle-line*
Initial Short (S): Double Smoothed Stochastic crosses-down under middle-line*
Continuation Long (CL): Double Smoothed Stochastic is over middle-line, then crosses-up over the signal**
Continuation Short (CS): Double Smoothed Stochastic is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Double Smoothed Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Double Smoothed Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Double Smoothed Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Double Smoothed Stochastic crosses-up over the signal****
BL Recovery Continuation Short (RS): Double Smoothed Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Double Smoothed Stochastic crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the Double Smoothed Stochastic then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Signal
Initial Long (L): Double Smoothed Stochastic crosses-up over middle-line*
Initial Short (S): Double Smoothed Stochastic crosses-down under middle-line*
Continuation Long (CL): Double Smoothed Stochastic is over middle-line, then crosses-up over the signal**
Continuation Short (CS): Double Smoothed Stochastic is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Double Smoothed Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Double Smoothed Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Double Smoothed Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic is still above middle-line; then, Double Smoothed Stochastic crosses-up over the signal****
BL Recovery Continuation Short (RS): Double Smoothed Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic is still below middle-line; then, Double Smoothed Stochastic crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the Double Smoothed Stochastic then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then Double Smoothed Stochastic crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then Double Smoothed Stochastic crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Continuation Long Confirmation 1 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 1 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-up over middle-line but Baseline is still in downtrend; and Double Smoothed Stochastic crossed-up over middle-line on the same bar or XX bars in the future but Baseline is still in downtrend; then Baseline turns to uptrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic is still above middle-line; then, The imported GKD-C Confirmation 1 crosses-up over the signal
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic is still below middle-line; then, The imported GKD-C Confirmation 1 crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 2
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): Double Smoothed Stochastic is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 2 (CS): Double Smoothed Stochastic is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): Double Smoothed Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Double Smoothed Stochastic crosses-up over the signal
BL Recovery Continuation Short (RS): Double Smoothed Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Double Smoothed Stochastic crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Both
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal; Double Smoothed Stochastic is over middle-line, then crosses-up over the signal within "Number of Bars Confirmation" bars in the future
Continuation Short Confirmation 2 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal; Double Smoothed Stochastic is under middle-line, then crosses-down under the signal within "Number of Bars Confirmation" bars in the future
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line and Double Smoothed Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, the imported GKD-C Confirmation 1 crosses-up over its signal, and Double Smoothed Stochastic crosses-up over its signal within "Number of Bars Confirmation" bars in the future
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line and Double Smoothed Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, the imported GKD-C Confirmation 1 crosses-down under its signal, and Double Smoothed Stochastic crosses-down under its signal within "Number of Bars Confirmation" bars in the future
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Both; Confirmation Type: (continuations don't change from the variations above)
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then Double Smoothed Stochastic crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Double Smoothed Stochastic crosses-up over middle-line, then the imported GKD-C Confirmation 1 indicator crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then Double Smoothed Stochastic crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Double Smoothed Stochastic crosses-down under middle-line, then the imported GKD-C Confirmation 1 indicator crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Double Smoothed Stochastic crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, Double Smoothed Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Double Smoothed Stochastic crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Solo Confirmation Signals
Initial Long (L): Double Smoothed Stochastic crosses-up over middle-line
Initial Short (S): Double Smoothed Stochastic crosses-down under middle-line
Continuation Long (CL): Double Smoothed Stochastic is over middle-line, then crosses-up over the signal
Continuation Short (CS): Double Smoothed Stochastic is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): Double Smoothed Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars
Post Baseline Cross Short (BS): Double Smoothed Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars
BL Recovery Continuation Long (RL): Double Smoothed Stochastic above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Double Smoothed Stochastic is still above middle-line
BL Recovery Continuation Short (RS): Double Smoothed Stochastic below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Double Smoothed Stochastic is still below middle-line
X-bar Rule settings
This rule only applies when this indicator "Confirmation Type" set to "Confirmation 2"
Requirements
Inputs: Confirmation 1 and Solo Confirmation: GKD-V Volatility/Volume indicator; Confirmation 2: GKD-C Confirmation indicator
Output: Confirmation 2 and Solo Confirmation: GKD-E Exit indicator; Confirmation 1: GKD-C Confirmation indicator
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.

GKD-C DiNapoli Stochastic [Loxx]Giga Kaleidoscope DiNapoli Stochastic Confirmation is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Leader Exponential Moving Average as shown on chart
Volatility/Volume: Volatility Ratio as shown on chart
Confirmation 1: DiNapoli Stochastic as shown on the chart above
Confirmation 2: Jurik Turning Point Oscillator
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-E DiNapoli Stochastic itself.
What is DiNapoli Stochastic?
The DiNapoli Stochastic demonstrates smoother indicators and therefore gives fewer false signals in comparison with the traditional oscillator.
The indicator is written in accordance with the description given in the book by Joe Dinapoli "Trading With DiNapoli Levels". This oscillator smoothing method leads to a filtering of the most "noise" component of the price movement.
The DiNapoli Stochastic indicator can be used in the strategies oriented to a standard stochastic. However, the stronger smoothing can lead to the loss of an array of signals. It is recommended to apply any trend indicator for more efficient use of the indicator and its signals filtering.
Signals
A GKD-C Confirmation indicator can be used as either a Confirmation 1, Confirmation 2, or Solo Confirmation indicator. See step 3 & 4 of the NNFX algorithm above to understand how this indicator fits into the GKD trading system. The Solo Confirmation setting allows you to test this indicator by itself without an additional GKD-C indicator present in the GKD protocol chain.
On the chart shown above, this indicator is shown as GKD-C DiNapoli Stochastic and is set to Solo Confirmation. The GKD-B Baseline, GKD-V Volatility Ratio, and this indicator satisfy the first three steps in the GKD trading system chain: GKD-B => GKD-V => GKD-C(solo).
The signals from each of these settings are as follows:
Confirmation 1 Signal
Initial Long (L): DiNapoli Stochastic crosses-up over middle-line*
Initial Short (S): DiNapoli Stochastic crosses-down under middle-line*
Continuation Long (CL): DiNapoli Stochastic is over middle-line, then crosses-up over the signal**
Continuation Short (CS): DiNapoli Stochastic is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): DiNapoli Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): DiNapoli Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): DiNapoli Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, DiNapoli Stochastic crosses-up over the signal****
BL Recovery Continuation Short (RS): DiNapoli Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, DiNapoli Stochastic crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the DiNapoli Stochastic then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Signal
Initial Long (L): DiNapoli Stochastic crosses-up over middle-line*
Initial Short (S): DiNapoli Stochastic crosses-down under middle-line*
Continuation Long (CL): DiNapoli Stochastic is over middle-line, then crosses-up over the signal**
Continuation Short (CS): DiNapoli Stochastic is under middle-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): DiNapoli Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): DiNapoli Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): DiNapoli Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while DiNapoli Stochastic is still above middle-line; then, DiNapoli Stochastic crosses-up over the signal****
BL Recovery Continuation Short (RS): DiNapoli Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while DiNapoli Stochastic is still below middle-line; then, DiNapoli Stochastic crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the middle-line respectively. This means that if the Baseline trend then moves against the DiNapoli Stochastic then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then DiNapoli Stochastic crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then DiNapoli Stochastic crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Continuation Long Confirmation 1 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 1 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-up over middle-line but Baseline is still in downtrend; and DiNapoli Stochastic crossed-up over middle-line on the same bar or XX bars in the future but Baseline is still in downtrend; then Baseline turns to uptrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, DiNapoli Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while DiNapoli Stochastic is still above middle-line; then, The imported GKD-C Confirmation 1 crosses-up over the signal
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while DiNapoli Stochastic is still below middle-line; then, The imported GKD-C Confirmation 1 crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 2
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): DiNapoli Stochastic is over middle-line, then crosses-up over the signal
Continuation Short Confirmation 2 (CS): DiNapoli Stochastic is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): DiNapoli Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, DiNapoli Stochastic crosses-up over the signal
BL Recovery Continuation Short (RS): DiNapoli Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, DiNapoli Stochastic crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Both
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): The imported GKD-C Confirmation 1 indicator is over middle-line, then crosses-up over the signal; DiNapoli Stochastic is over middle-line, then crosses-up over the signal within "Number of Bars Confirmation" bars in the future
Continuation Short Confirmation 2 (CS): The imported GKD-C Confirmation 1 indicator is under middle-line, then crosses-down under the signal; DiNapoli Stochastic is under middle-line, then crosses-down under the signal within "Number of Bars Confirmation" bars in the future
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above middle-line and DiNapoli Stochastic is above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, the imported GKD-C Confirmation 1 crosses-up over its signal, and DiNapoli Stochastic crosses-up over its signal within "Number of Bars Confirmation" bars in the future
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below middle-line and DiNapoli Stochastic is below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, the imported GKD-C Confirmation 1 crosses-down under its signal, and DiNapoli Stochastic crosses-down under its signal within "Number of Bars Confirmation" bars in the future
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Both; Confirmation Type: (continuations don't change from the variations above)
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over middle-line, then DiNapoli Stochastic crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, DiNapoli Stochastic crosses-up over middle-line, then the imported GKD-C Confirmation 1 indicator crosses-up over the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under middle-line, then DiNapoli Stochastic crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, DiNapoli Stochastic crosses-down under middle-line, then the imported GKD-C Confirmation 1 indicator crosses-down under the middle-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, DiNapoli Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, DiNapoli Stochastic crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under middle-line but Baseline is still in uptrend; and, DiNapoli Stochastic crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, DiNapoli Stochastic crossed-down under middle-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under middle-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Solo Confirmation Signals
Initial Long (L): DiNapoli Stochastic crosses-up over middle-line
Initial Short (S): DiNapoli Stochastic crosses-down under middle-line
Continuation Long (CL): DiNapoli Stochastic is over middle-line, then crosses-up over the signal
Continuation Short (CS): DiNapoli Stochastic is under middle-line, then crosses-down under the signal
Post Baseline Cross Long (BL): DiNapoli Stochastic crossed-up over middle-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars
Post Baseline Cross Short (BS): DiNapoli Stochastic crossed-down under middle-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars
BL Recovery Continuation Long (RL): DiNapoli Stochastic above middle-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while DiNapoli Stochastic is still above middle-line
BL Recovery Continuation Short (RS): DiNapoli Stochastic below middle-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while DiNapoli Stochastic is still below middle-line
X-bar Rule settings
This rule only applies when this indicator "Confirmation Type" set to "Confirmation 2"
Requirements
Inputs: Confirmation 1 and Solo Confirmation: GKD-V Volatility/Volume indicator; Confiration 2: GKD-C Confirmation indicator
Output: Confirmation 2 and Solo Confirmation: GKD-E Exit indicator; Confiration 1: GKD-C Confirmation indicator
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
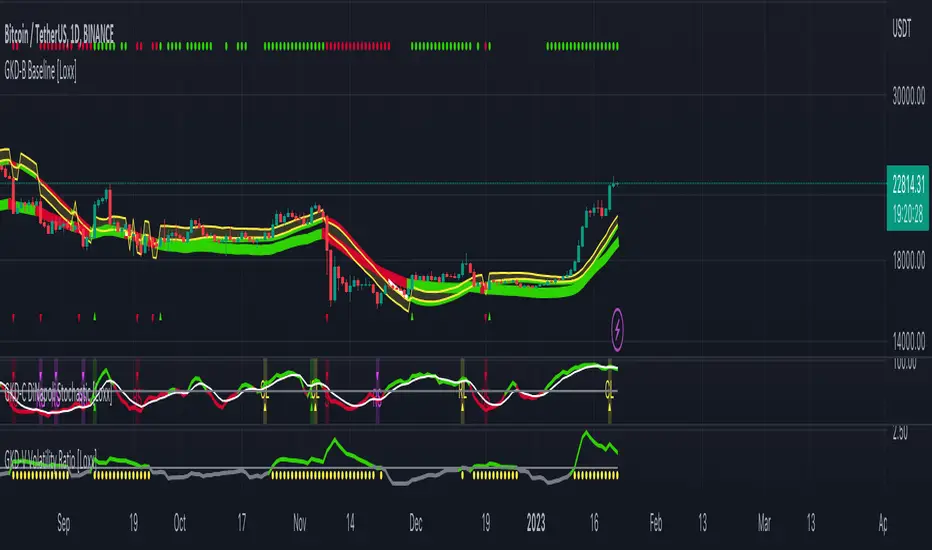
GKD-C Fisher Transform [Loxx]Giga Kaleidoscope Fisher Transform Confirmation is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio
Confirmation 1: Fisher Transform as shown on the chart above
Confirmation 2: Vortex
Exit: Fisher Transform
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-E Fisher Transform itself.
What is Fisher Transform?
The Fisher Transform is a technical indicator created by John F. Ehlers that converts prices into a Gaussian normal distribution. The indicator highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset.
What's different in this version?
This version also includes Loxx's Exotic Source Types. You can read about these sources here:
Signals
A GKD-C Confirmation indicator can be used as either a Confirmation 1, Confirmation 2, or Solo Confirmation indicator. See step 3 & 4 of the NNFX algorithm above to understand how this indicator fits into the GKD trading system. The Solo Confirmation setting allows you to test this indicator by itself without an additional GKD-C indicator present in the GKD protocol chain.
On the chart shown above, this indicator is shown as GKD-C Fisher Transform and is set to Solo Confirmation. The GKD-B Baseline, GKD-V Volatility Ratio, and this indicator satisfy the first three steps in the GKD trading system chain: GKD-B => GKD-V => GKD-C(solo).
The signals from each of these settings are as follows:
Confirmation 1 Signal
Initial Long (L): Fisher crosses-up over zero-line*
Initial Short (S): Fisher crosses-down under zero-line*
Continuation Long (CL): Fisher is over zero-line, then crosses-up over the signal**
Continuation Short (CS): Fisher is under zero-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Fisher crossed-up over zero-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Fisher crossed-down under zero-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Fisher is above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Fisher crosses-up over the signal****
BL Recovery Continuation Short (RS): Fisher is below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Fisher crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the zero-line respectively. This means that if the Baseline trend then moves against the Fisher Transform then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Signal
Initial Long (L): Fisher crosses-up over zero-line*
Initial Short (S): Fisher crosses-down under zero-line*
Continuation Long (CL): Fisher is over zero-line, then crosses-up over the signal**
Continuation Short (CS): Fisher is under zero-line, then crosses-down under the signal**
Post Baseline Cross Long (BL): Fisher crossed-up over zero-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars***
Post Baseline Cross Short (BS): Fisher crossed-down under zero-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars***
BL Recovery Continuation Long (RL): Fisher is above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Fisher is still above zero-line; then, Fisher crosses-up over the signal****
BL Recovery Continuation Short (RS): Fisher is below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Fisher is still below zero-line; then, Fisher crosses-down under the signal****
*All signals are shown regardless of Baseline and Volatility/Volume qualification
**All signals are shown regardless of Baseline qualification; however, when Baseline filter is active, only true continuations are shown. When the Baseline filter is not active, then all continuations are shown. True continuations are when the Baseline is active and maintains its uptrend/downtrend after the initial cross-up/cross-down over the zero-line respectively. This means that if the Baseline trend then moves against the Fisher Transform then any continuation signals are voided until another initial Long/Short. All continuations are will either show as regular continuations or be converted into recovery continuations
***All signals are shown regardless of Volatility/Volume qualification
****When the Baseline filter is active, some regular continuations are converted to recovery continuations and are shown. When the Baseline filter is not active, then these signals are not shown.
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over zero-line, then Fisher Transform crosses-up over the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under zero-line, then Fisher Transform crosses-down under the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Continuation Long Confirmation 1 (CL): The imported GKD-C Confirmation 1 indicator is over zero-line, then crosses-up over the signal
Continuation Short Confirmation 1 (CS): The imported GKD-C Confirmation 1 indicator is under zero-line, then crosses-down under the signal
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-up over zero-line but Baseline is still in downtrend; and Fisher crossed-up over zero-line on the same bar or XX bars in the future but Baseline is still in downtrend; then Baseline turns to uptrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under zero-line but Baseline is still in uptrend; and, Fisher crossed-down under zero-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Fisher is still above zero-line; then, The imported GKD-C Confirmation 1 crosses-up over the signal
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Fisher is still below zero-line; then, The imported GKD-C Confirmation 1 crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 2
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): Fisher is over zero-line, then crosses-up over the signal
Continuation Short Confirmation 2 (CS): Fisher is under zero-line, then crosses-down under the signal
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): Fisher is above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, Fisher crosses-up over the signal
BL Recovery Continuation Short (RS): Fisher is below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, Fisher crosses-down under the signal
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Both
Initial Long (L): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Initial Short (S): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Continuation Long Confirmation 2 (CL): The imported GKD-C Confirmation 1 indicator is over zero-line, then crosses-up over the signal; Fisher is over zero-line, then crosses-up over the signal within "Number of Bars Confirmation" bars in the future
Continuation Short Confirmation 2 (CS): The imported GKD-C Confirmation 1 indicator is under zero-line, then crosses-down under the signal; Fisher is under zero-line, then crosses-down under the signal within "Number of Bars Confirmation" bars in the future
Post Baseline Cross Long (BL): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
Post Baseline Cross Short (BS): same as Confirmation 2 Confluence Background Color Signals; Confirmation Order: Regular; Confirmation Type: Confirmation 1
BL Recovery Continuation Long (RL): The imported GKD-C Confirmation 1 indicator is above zero-line and Fisher is above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend; then, the imported GKD-C Confirmation 1 crosses-up over its signal, and Fisher crosses-up over its signal within "Number of Bars Confirmation" bars in the future
BL Recovery Continuation Short (RS): The imported GKD-C Confirmation 1 indicator is below zero-line and Fisher is below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend; then, the imported GKD-C Confirmation 1 crosses-down under its signal, and Fisher crosses-down under its signal within "Number of Bars Confirmation" bars in the future
Confirmation 2 Confluence Background Color Signals; Confirmation Order: Both; Confirmation Type: (continuations don't change from the variations above)
Initial Long (L): The imported GKD-C Confirmation 1 indicator crosses-up over zero-line, then Fisher Transform crosses-up over the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Fisher crosses-up over zero-line, then the imported GKD-C Confirmation 1 indicator crosses-up over the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Initial Short (S): The imported GKD-C Confirmation 1 indicator crosses-down under zero-line, then Fisher Transform crosses-down under the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below); OR, Fisher crosses-down under zero-line, then the imported GKD-C Confirmation 1 indicator crosses-down under the zero-line on the same bar or "Number of Bars Confirmation" bars in the future (see X-bar rule below)
Post Baseline Cross Long (BL): The imported GKD-C Confirmation 1 crossed-down under zero-line but Baseline is still in uptrend; and, Fisher crossed-down under zero-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Fisher crossed-down under zero-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under zero-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Post Baseline Cross Short (BS): The imported GKD-C Confirmation 1 crossed-down under zero-line but Baseline is still in uptrend; and, Fisher crossed-down under zero-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below); OR, Fisher crossed-down under zero-line but Baseline is still in uptrend; and, the imported GKD-C Confirmation 1 crossed-down under zero-line on the same bar or XX bars in the future but Baseline is still in uptrend; then Baseline turns to downtrend within "Maximum Allowable PSBC Bars Back" bars (see X-bar rule below)
Solo Confirmation Signals
Initial Long (L): Fisher crosses-up over zero-line
Initial Short (S): Fisher crosses-down under zero-line
Continuation Long (CL): Fisher is over zero-line, then crosses-up over the signal
Continuation Short (CS): Fisher is under zero-line, then crosses-down under the signal
Post Baseline Cross Long (BL): Fisher crossed-up over zero-line but Baseline is still in downtrend, then Baseline turns to uptrend within XX bars
Post Baseline Cross Short (BS): Fisher crossed-down under zero-line but Baseline is still in uptrend, then Baseline turns to downtrend within XX bars
BL Recovery Continuation Long (RL): Fisher above zero-line. Baseline already crossed down into downtrend, then baseline crosses back up to uptrend while Fisher is still above zero-line
BL Recovery Continuation Short (RS): Fisher below zero-line. Baseline already crossed up into uptrend, then baseline crosses back down to downtrend while Fisher is still below zero-line
X-bar Rule settings
This rule only applies when this indicator "Confirmation Type" set to "Confirmation 2"
Requirements
Inputs: Confirmation 1 and Solo Confirmation: GKD-V Volatility/Volume indicator; Confirmation 2: GKD-C Confirmation indicator
Output: Confirmation 2 and Solo Confirmation: GKD-E Exit indicator; Confirmation 1: GKD-C Confirmation indicator
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.

GKD-E Fisher Transform [Loxx]Giga Kaleidoscope Fisher Transform Exit is an Exit module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio
Confirmation 1: Vortex
Confirmation 2: Fisher Transform
Exit: Fisher Transform as shown on the chart above
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-E Fisher Transform itself.
What is Fisher Transform?
The Fisher Transform is a technical indicator created by John F. Ehlers that converts prices into a Gaussian normal distribution. The indicator highlights when prices have moved to an extreme, based on recent prices. This may help in spotting turning points in the price of an asset.
What's different in this version?
This version also includes Loxx's Exotic Source Types. You can read about these sources here:
Exit signals
Exit Long type 1: Fisher is above zero and crosses down under the Fisher signal
Exit Long type 2: Fisher is above overbought level and crosses down the Fisher signal
Exit Short type 1: Fisher is below zero and crosses up over the Fisher signal
Exit Short type 2: Fisher is below oversold level and crosses up over the Fisher signal
Requirements
Input: Any Confirmation 2 indicator
Output: Export to "GKD-BT Backtest"
Other things to note
A GKD Exit indicator is required to complete the GKD trading system chain, but you are not requried to activate the Exits. You can turn on/off the exits inside this indicator, but an exit indiator is sitll required to be present in the GKD protocol chain.
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.

GKD-V Volatility Ratio [Loxx]Giga Kaleidoscope Volatility Ratio is a Volatility/Volume module included in Loxx's "Giga Kaleidoscope Modularized Trading System".
What is Loxx's "Giga Kaleidoscope Modularized Trading System"?
The Giga Kaleidoscope Modularized Trading System is a trading system built on the philosophy of the NNFX (No Nonsense Forex) algorithmic trading.
What is an NNFX algorithmic trading strategy?
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend (such as "Baseline" shown on the chart above)
3. Confirmation 1 - a technical indicator used to identify trends. This should agree with the "Baseline"
4. Confirmation 2 - a technical indicator used to identify trends. This filters/verifies the trend identified by "Baseline" and "Confirmation 1"
5. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown.
6. Exit - a technical indicator used to determine when a trend is exhausted.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v1.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 module (Confirmation 1/2, Numbers 3 and 4 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 5 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 6 in the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data between modules. Data is passed between each module as described below:
GKD-B => GKD-V => GKD-C(1) => GKD-C(2) => GKD-E => GKD-BT
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Strategy with 1-3 take profits, trailing stop loss, multiple types of PnL volatility, and 2 backtesting styles
Baseline: Hull Moving Average
Volatility/Volume: Volatility Ratio as shown on the chart above
Confirmation 1: Vortex
Confirmation 2: Fisher Transform
Exit: Rex Oscillator
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD protocol chain.
Now that you have a general understanding of the NNFX algorithm and the GKD trading system. Let's go over what's inside the GKD-V Volatility Ratio itself.
What is Volatility Ratio?
Volatility Ratio is a comparison between volatility and its moving average. This indicator includes 11 different types of volatility as well as 63 different moving averages.
You can read about the moving average types here:
Volatility Types Included
v1.0 Included Volatility
Close-to-Close
Close-to-Close volatility is a classic and most commonly used volatility measure, sometimes referred to as historical volatility .
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a bigger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility calculated using only stock's closing prices. It is the simplest volatility estimator. But in many cases, it is not precise enough. Stock prices could jump considerably during a trading session, and return to the open value at the end. That means that a big amount of price information is not taken into account by close-to-close volatility .
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. That is useful as close to close prices could show little difference while large price movements could have happened during the day. Thus Parkinson's volatility is considered to be more precise and requires less data for calculation than the close-close volatility .
One drawback of this estimator is that it doesn't take into account price movements after market close. Hence it systematically undervalues volatility . That drawback is taken into account in the Garman-Klass's volatility estimator.
Garman-Klass
Garman Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing price. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change is a process of continuous diffusion (Geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremums.
Researchers Rogers and Satchel have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates drift term (mean return not equal to zero). As a result, it provides a better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. It means an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
We can think of the Yang-Zhang volatility as the combination of the overnight (close-to-open volatility ) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility . It considered being 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman-Klass-Yang-Zhang (GKYZ) volatility estimator consists of using the returns of open, high, low, and closing prices in its calculation.
GKYZ volatility estimator takes into account overnight jumps but not the trend, i.e. it assumes that the underlying asset follows a GBM process with zero drift. Therefore the GKYZ volatility estimator tends to overestimate the volatility when the drift is different from zero. However, for a GBM process, this estimator is eight times more efficient than the close-to-close volatility estimator.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, the main applications being technical analysis and volatility modeling.
The moving average is designed as such that older observations are given lower weights. The weights fall exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility . It's the standard deviation of ln(close/close(1))
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by θ.
θavg(var ;M) + (1 − θ) avg (var ;N) = 2θvar/(M+1-(M-1)L) + 2(1-θ)var/(M+1-(M-1)L)
Solving for θ can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg (var; N) against avg (var; M) - avg (var; N) and using the resulting beta estimate as θ.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Signals
1. Traditional: The traditional signal is volatility is either high or low. This is non-directional. When the Volatility Ratio is above 1, then there is enough volatility to trade long or short. This signal type has a bar risings option that requires that the Volatility Ratio is not only above 1 but also rising for the last XX bars.
2. Crossing: This is experimental. When a cross-up above 1 or cross-down below one occurs then, and only then, is there enough volatility to trade long or short. This is also non-directional.
3. Both Traditional and Crossing
X-bar Rule
If a signal registers XX bars ago, then the signal is still valid. This is an optional feature.
Other things to note
The GKD trading system requires that a GKD-V indicator be present in the indicator chain, but the GKD-V indicator doesn't need to be active. You can turn on/off the Volatility Ratio as you wish so you can backtest your trading strategy with the filter on or off.
Additional features will be added in future releases.
This indicator is only available to ALGX Trading VIP group members . You can see the Author's Instructions below to get more information on how to get access.
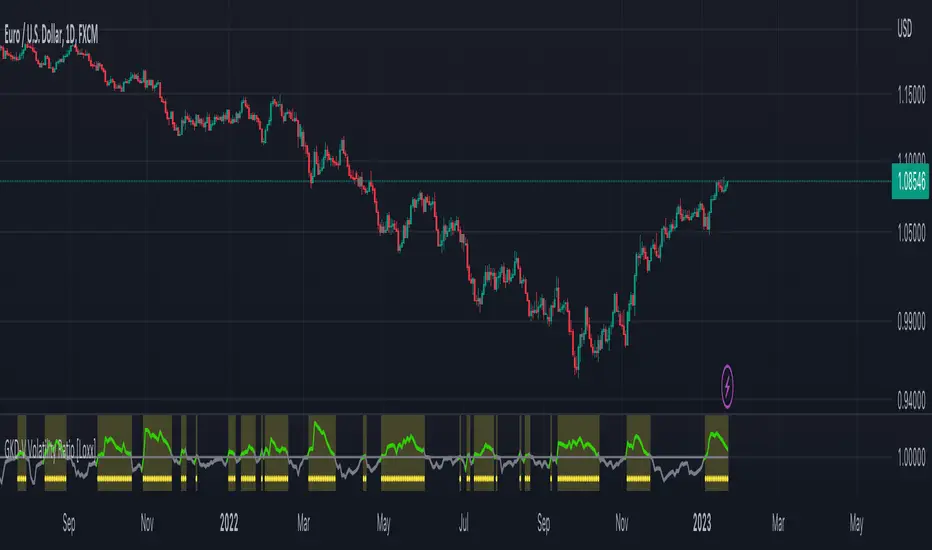
Goertzel Cycle Period [Loxx]Goertzel Cycle Period is an indicator that uses Goertzel algorithm to extract the cycle period of ticker's price input to then be injected into advanced, adaptive indicators and technical analysis algorithms.
The following information is extracted from: "MESA vs Goertzel-DFT, 2003 by Dennis Meyers"
Background
MESA which stands for Maximum Entropy Spectral Analysis is a widely used mathematical technique designed to find the frequencies present in data. MESA was developed by J.P Burg for his Ph.D dissertation at Stanford University in 1975. The use of the MESA technique for stocks has been written about in many articles and has been popularized as a trading technique by John Ehlers.
The Fourier Transform is a mathematical technique named after the famed French mathematician Jean Baptiste Joseph Fourier 1768-1830. In its digital form, namely the discrete-time Fourier Transform (DFT) series, is a widely used mathematical technique to find the frequencies of discrete time sampled data. The use of the DFT has been written about in many articles in this magazine (see references section).
Today, both MESA and DFT are widely used in science and engineering in digital signal processing. The application of MESA and Fourier mathematical techniques are prevalent in our everyday life from everything from television to cell phones to wireless internet to satellite communications.
MESA Advantages & Disadvantage
MESA is a mathematical technique that calculates the frequencies of a time series from the autoregressive coefficients of the time series. We have all heard of regression. The simplest regression is the straight line regression of price against time where price(t) = a+b*t and where a and b are calculated such that the square of the distance between price and the best fit straight line is minimized (also called least squares fitting). With autoregression we attempt to predict tomorrows price by a linear combination of M past prices.
One of the major advantages of MESA is that the frequency examined is not constrained to multiples of 1/N (1/N is equal to the DFT frequency spacing and N is equal to the number of sample points). For instance with the DFT and N data points we can only look a frequencies of 1/N, 2/N, Ö.., 0.5. With MESA we can examine any frequency band within that range and any frequency spacing between i/N and (i+1)/N . For example, if we had 100 bars of price data, we might be interested in looking for all cycles between 3 bars per cycle and 30 bars/ cycle only and with a frequency spacing of 0.5 bars/cycle. DFT would examine all bars per cycle of between 2 and 50 with a frequency spacing constrained to 1/100.
Another of the major advantages of MESA is that the dominant spectral (frequency) peaks of the price series, if they exist, can be identified with fewer samples than the DFT technique. For instance if we had a 10 bar price period and a high signal to noise ratio we could accurately identify this period with 40 data samples using the MESA technique. This same resolution might take 128 samples for the DFT. One major disadvantage of the MESA technique is that with low signal to noise ratios, that is below 6db (signal amplitude/noise amplitude < 2), the ability of MESA to find the dominant frequency peaks is severely diminished.(see Kay, Ref 10, p 437). With noisy price series this disadvantage can become a real problem. Another disadvantage of MESA is that when the dominant frequencies are found another procedure has to be used to get the amplitude and phases of these found frequencies. This two stage process can make MESA much slower than the DFT and FFT . The FFT stands for Fast Fourier Transform. The Fast Fourier Transform(FFT) is a computationally efficient algorithm which is a designed to rapidly evaluate the DFT. We will show in examples below the comparisons between the DFT & MESA using constructed signals with various noise levels.
DFT Advantages and Disadvantages.
The mathematical technique called the DFT takes a discrete time series(price) of N equally spaced samples and transforms or converts this time series through a mathematical operation into set of N complex numbers defined in what is called the frequency domain. Why would we what to do that? Well it turns out that we can do all kinds of neat analysis tricks in the frequency domain which are just to hard to do, computationally wise, with the original price series in the time domain. If we make the assumption that the price series we are examining is made up of signals of various frequencies plus noise, than in the frequency domain we can easily filter out the frequencies we have no interest in and minimize the noise in the data. We could then transform the resultant back into the time domain and produce a filtered price series that hopefully would be easier to trade. The advantages of the DFT and itís fast computation algorithm the FFT, are that it is extremely fast in calculating the frequencies of the input price series. In addition it can determine frequency peaks for very noisy price series even when the signal amplitude is less than the noise amplitude. One of the disadvantages of the FFT is that straight line, parabolic trends and edge effects in the price series can distort the frequency spectrum. In addition, end effects in the price series can distort the frequency spectrum. Another disadvantage of the FFT is that it needs a lot more data than MESA for spectral resolution. However this disadvantage has largely been nullified by the speed of today's computers.
Goertzel algorithm attempts to resolve these problems...
What is the Goertzel algorithm?
The Goertzel algorithm is a technique in digital signal processing (DSP) for efficient evaluation of the individual terms of the discrete Fourier transform (DFT). It is useful in certain practical applications, such as recognition of dual-tone multi-frequency signaling (DTMF) tones produced by the push buttons of the keypad of a traditional analog telephone. The algorithm was first described by Gerald Goertzel in 1958.
Like the DFT, the Goertzel algorithm analyses one selectable frequency component from a discrete signal. Unlike direct DFT calculations, the Goertzel algorithm applies a single real-valued coefficient at each iteration, using real-valued arithmetic for real-valued input sequences. For covering a full spectrum, the Goertzel algorithm has a higher order of complexity than fast Fourier transform (FFT) algorithms, but for computing a small number of selected frequency components, it is more numerically efficient. The simple structure of the Goertzel algorithm makes it well suited to small processors and embedded applications.
The main calculation in the Goertzel algorithm has the form of a digital filter, and for this reason the algorithm is often called a Goertzel filter
Where is Goertzel algorithm used?
This package contains the advanced mathematical technique called the Goertzel algorithm for discrete Fourier transforms. This mathematical technique is currently used in today's space-age satellite and communication applications and is applied here to stock and futures trading.
While the mathematical technique called the Goertzel algorithm is unknown to many, this algorithm is used everyday without even knowing it. When you press a cell phone button have you ever wondered how the telephone company knows what button tone you pushed? The answer is the Goertzel algorithm. This algorithm is built into tiny integrated circuits and immediately detects which of the 12 button tones(frequencies) you pushed.
Future Additions:
Bartels test for cycle significance, testing output cycles for utility
Hodrick Prescott Detrending, smoothing
Zero-Lag Regression Detrending, smoothing
High-pass or Double WMA filtering of source input price data
References:
1. Burg, J. P., ëMaximum Entropy Spectral Analysisî, Ph.D. dissertation, Stanford University, Stanford, CA. May 1975.
2. Kay, Steven M., ìModern Spectral Estimationî, Prentice Hall, 1988
3. Marple, Lawrence S. Jr., ìDigital Spectral Analysis With Applicationsî, Prentice Hall, 1987
4. Press, William H., et al, ìNumerical Receipts in C++: the Art of Scientific Computingî,
Cambridge Press, 2002.
5. Oppenheim, A, Schafer, R. and Buck, J., ìDiscrete Time Signal Processingî, Prentice Hall,
1996, pp663-634
6. Proakis, J. and Manolakis, D. ìDigital Signal Processing-Principles, Algorithms and
Applicationsî, Prentice Hall, 1996., pp480-481
7. Goertzel, G., ìAn Algorithm for he evaluation of finite trigonometric seriesî American Math
Month, Vol 65, 1958 pp34-35.
TopTenAlgo 10. SQZMOM_LSvwMA with Bar ColorEN: This Algorithm is a derivative of John Carter's "TTM Squeeze" volatility indicator. Many strategists have taken the indicator on Tradingview with simple moving averages and have looked at the biggest mistake only by dealing with squeeze and exit processes to squeeze. But I used the algorithm to determine where the markets would actually explode. For example, instead of using SMAs , I tested them on the Linear Regression Curve using Volume Weighted Moving Averages and Hull MAs. This gave me the opportunity to develop a more responsive algorithm and identify where the actual explosion would occur. The Gray Circles in the midline show that the market is entering a new jam (in the Bollinger Bands and Keltner Channel). This means low volatility , the market prepares itself for an explosive move (up or down). White Circles mean that it is about to get out of the jam. The Blue Circles, which no one can calculate, now inform that the exit is no longer jammed and that the explosion has taken place.
Mr. Carter recommends that you wait until the first gray after a gray cross and take a position in the momentum direction (for example, if the momentum value is above zero, relax). Exit position when the momentum changes (increase or decrease, this is indicated by a color change). In this algorithm, I tried to achieve good entry points using an additional indicator such as ADX and WaveTrend. To draw the histogram, I used a different method based on Linear Regression . Mr.Carter uses a simple momentum indicator .
In summary, this algorithm is a strict algorithm in which additional 4-5 indicators are blended. Conveniences for Everyone ...
This algorithm is prepared with @Top10Algo ...
TR: Bu Algoritma John Carter'ın "TTM Squeeze" volatilite göstergesinin bir türevidir. Bir çok stratejist Tradingview' de gösterge' yi basit hareketli ortalamalarla ele almış ve en büyük hatayı sadece sıkışma ve sıkışmadan çıkış süreçlerini ele alarak bakmışlardır. Fakat ben algoritmayı piyasaların asıl patlama yapacağı yeri tespit etmek için kullandım. Örneğin SMA' ları kullanmak yerine Hacim Ağırlıklı Hareketli Ortalamaları ve Hull MA' ları kullanarak onları Linerar Regresyon Eğrisinde stress testine tabi tuttum. Buda bana daha duyarlı bir algoritma geliştirmem ve asıl patlamanın olacağı yerleri tespit etmem için fırsat verdi. Orta hattaki Gri Daireler, piyasanın yeni bir sıkışmaya girdiğini gösteriyor ( Bollinger Bantları ve Keltner Kanalı'nda). Bu, düşük volatilite anlamına gelir, piyasa kendisini patlayıcı bir harekete hazırlar (yukarı veya aşağı). Beyaz Daireler ise sıkışmadan çıkmak üzere olduğu anlamına gelir. Hiç kimsenin hesap edemediği Mavi Daireler ise artık sıkışmadan çıkıldığını ve patlamanın gerçekleştiğini haber verir.
Mr.Carter, gri bir çarpı işaretinden sonra ilk griye kadar beklemenizi ve momentum yönünde bir pozisyon almanızı önerir (örneğin, momentum değeri sıfırın üstünde ise, rahat olun). Momentum değiştiğinde pozisyondan çıkın (artırma veya azaltma, bunu o bir renk değişikliği ile belirtilir). Bu algoritmada ben, ADX ve WaveTrend gibi ek bir gösterge kullanarak iyi giriş noktalarıelde etmeye çalıştım. Histogramı çizmek için ise Linear Regresyon tabanlı farklı bir yöntem kullandım. Mr.Carter basit bir momentum göstergesi kullanır.
Özetle bu algoritma ek 4-5 göstergenin harmanlandığı sıkı bir algoritmadır. Herkese Kolaylıklar dilerim...
Bu algoritma @Top10Algo ile beraber hazırlanmıştır... Kodlamadaki katkılarından ve yol göstericiliğinden dolayı teşekkürü bir borç bilirim.
TopTenAlgo 10. SQZMOM_LSvwMA with Bar Color (Not Based Volume)EN: This Algorithm is a derivative of John Carter's "TTM Squeeze" volatility indicator. Many strategists have taken the indicator on Tradingview with simple moving averages and have looked at the biggest mistake only by dealing with squeeze and exit processes to squeeze. But I used the algorithm to determine where the markets would actually explode. For example, instead of using SMAs , I tested them on the Linear Regression Curve using Volume Weighted Moving Averages and Hull MAs. This gave me the opportunity to develop a more responsive algorithm and identify where the actual explosion would occur. The Gray Circles in the midline show that the market is entering a new jam (in the Bollinger Bands and Keltner Channel). This means low volatility , the market prepares itself for an explosive move (up or down). White Circles mean that it is about to get out of the jam. The Blue Circles, which no one can calculate, now inform that the exit is no longer jammed and that the explosion has taken place.
Mr. Carter recommends that you wait until the first gray after a gray cross and take a position in the momentum direction (for example, if the momentum value is above zero, relax). Exit position when the momentum changes (increase or decrease, this is indicated by a color change). In this algorithm, I tried to achieve good entry points using an additional indicator such as ADX and WaveTrend. To draw the histogram, I used a different method based on Linear Regression . Mr.Carter uses a simple momentum indicator .
In summary, this algorithm is a strict algorithm in which additional 4-5 indicators are blended. Conveniences for Everyone ... (For Symbols that cannot be read on the Volume Indicator)
This algorithm is prepared with @Top10Algo ...
TR: Bu Algoritma John Carter'ın "TTM Squeeze" volatilite göstergesinin bir türevidir. Bir çok stratejist Tradingview' de gösterge' yi basit hareketli ortalamalarla ele almış ve en büyük hatayı sadece sıkışma ve sıkışmadan çıkış süreçlerini ele alarak bakmışlardır. Fakat ben algoritmayı piyasaların asıl patlama yapacağı yeri tespit etmek için kullandım. Örneğin SMA' ları kullanmak yerine Hacim Ağırlıklı Hareketli Ortalamaları ve Hull MA' ları kullanarak onları Linerar Regresyon Eğrisinde stress testine tabi tuttum. Buda bana daha duyarlı bir algoritma geliştirmem ve asıl patlamanın olacağı yerleri tespit etmem için fırsat verdi. Orta hattaki Gri Daireler, piyasanın yeni bir sıkışmaya girdiğini gösteriyor ( Bollinger Bantları ve Keltner Kanalı'nda). Bu, düşük volatilite anlamına gelir, piyasa kendisini patlayıcı bir harekete hazırlar (yukarı veya aşağı). Beyaz Daireler ise sıkışmadan çıkmak üzere olduğu anlamına gelir. Hiç kimsenin hesap edemediği Mavi Daireler ise artık sıkışmadan çıkıldığını ve patlamanın gerçekleştiğini haber verir.
Mr.Carter, gri bir çarpı işaretinden sonra ilk griye kadar beklemenizi ve momentum yönünde bir pozisyon almanızı önerir (örneğin, momentum değeri sıfırın üstünde ise, rahat olun). Momentum değiştiğinde pozisyondan çıkın (artırma veya azaltma, bunu o bir renk değişikliği ile belirtilir). Bu algoritmada ben, ADX ve WaveTrend gibi ek bir gösterge kullanarak iyi giriş noktalarıelde etmeye çalıştım. Histogramı çizmek için ise Linear Regresyon tabanlı farklı bir yöntem kullandım. Mr.Carter basit bir momentum göstergesi kullanır.
Özetle bu algoritma ek 4-5 göstergenin harmanlandığı sıkı bir algoritmadır. Herkese Kolaylıklar dilerim... (Hacim Göstergesi okunamayan Semboller için)
Bu algoritma @Top10Algo ile beraber hazırlanmıştır...

THE QUANTUM TRADER BITCOINThe Quantum Trader is a Algorithmic Automated Trading System that trades XBTUSD and BTC/USD with an emphasis on minimizing risk.
This algorithm trades multiple of our individual algorithms in an attempt to have a large number of uncorrelated algorithms trading concurrently,
thereby smoothing out the equity curve in an attempt to provide more consistency in the returns.
The Quantum trader utilizes swing trading algorithms along with day trading algorithms which can enter positions either Long or Short, and
take profits either Long or Short depending on market characteristics.
The Quantum Trader was built for automated trading, but can be used for manual trading also.
The Quantum Trader was designed to be used with Heikin Ashi candles on 3H chart. Indicator uses security function for profit points so alerts will give a warning
however, gaps are OFF and Lookahead is ON and trades are entered, and profits are taken at candle close.
Trades are placed following a strict algorithm, and nothing is left to subjective opinion.
The Quantum Trader utilizes a sophisticated pattern recognition algorithms that have been rigorously tested, and has been traded live since March 2019
When compared to other algorithmic trading systems, the quantum trader places fewer trades which helps contribute to the smaller draw down seen in the back-testing.
Algorithmic Trading Strategy Compared to Paid Signal Groups and Online Trading Classes
While there is an appeal to paid signal groups, and online trading classes. Most of the trading tips and signals you find online are sadly too basic and lacking an analytical approach to defend the statements which are made.
Comments are made and repeated that simply don’t have any empirical evidence to back them up.
In algorithmic trading back-testing and monthly system overviews is (or should be) part of the design methodology, the strategy will be analyzed for multiple time periods to include bull and bear markets.
We test and trade our algorithms across multiple market cycles to include Bear and Bull markets.
With Algorithmic Trading, nothing is left to interpretation. The algo will place trades as it sees fit and will attempt to generate positive returns as trades are methodically placed on individuals accounts.
There is no staring at charts, no drawing of trend lines , no signals to take and all the negative emotions involved with trading are minimized.
Lastly, the potential for human errors is minimized since trades are placed automatically by the Automated Trading System as opposed to signals learned in an online trading course or signals received.

Copeland Dynamic Dominance Matrix System | GForgeCopeland Dynamic Dominance Matrix System | GForge - v1
---
📊 COMPREHENSIVE SYSTEM OVERVIEW
The GForge Dynamic BB% TrendSync System represents a revolutionary approach to algorithmic portfolio management, combining cutting-edge statistical analysis, momentum detection, and regime identification into a unified framework. This system processes up to 39 different cryptocurrency assets simultaneously, using advanced mathematical models to determine optimal capital allocation across dynamic market conditions.
Core Innovation: Multi-Dimensional Analysis
Unlike traditional single-asset indicators, this system operates on multiple analytical dimensions:
Momentum Analysis: Dual Bollinger Band Modified Deviation (DBBMD) calculations
Relative Strength: Comprehensive dominance matrix with head-to-head comparisons
Fundamental Screening: Alpha and Beta statistical filtering
Market Regime Detection: Five-component statistical testing framework
Portfolio Optimization: Dynamic weighting and allocation algorithms
Risk Management: Multi-layered protection and regime-based positioning
---
🔧 DETAILED COMPONENT BREAKDOWN
1. Dynamic Bollinger Band % Modified Deviation Engine (DBBMD)
The foundation of this system is an advanced oscillator that combines two independent Bollinger Band systems with asymmetric parameters to create unique momentum readings.
Technical Implementation:
[
// BB System 1: Fast-reacting with extended standard deviation
primary_bb1_ma_len = 40 // Shorter MA for responsiveness
primary_bb1_sd_len = 65 // Longer SD for stability
primary_bb1_mult = 1.0 // Standard deviation multiplier
// BB System 2: Complementary asymmetric design
primary_bb2_ma_len = 8 // Longer MA for trend following
primary_bb2_sd_len = 66 // Shorter SD for volatility sensitivity
primary_bb2_mult = 1.7 // Wider bands for reduced noise
Key Features:
Asymmetric Design: The intentional mismatch between MA and Standard Deviation periods creates unique oscillation characteristics that traditional Bollinger Bands cannot achieve
Percentage Scale: All readings are normalized to 0-100% scale for consistent interpretation across assets
Multiple Combination Modes:
BB1 Only: Fast/reactive system
BB2 Only: Smooth/stable system
Average: Balanced blend (recommended)
Both Required: Conservative (both must agree)
Either One: Aggressive (either can trigger)
Mean Deviation Filter: Additional volatility-based layer that measures the standard deviation of the DBBMD% itself, creating dynamic trigger bands
Signal Generation Logic:
// Primary thresholds
primary_long_threshold = 71 // DBBMD% level for bullish signals
primary_short_threshold = 33 // DBBMD% level for bearish signals
// Mean Deviation creates dynamic bands around these thresholds
upper_md_band = combined_bb + (md_mult * bb_std)
lower_md_band = combined_bb - (md_mult * bb_std)
// Signal triggers when DBBMD crosses these dynamic bands
long_signal = lower_md_band > long_threshold
short_signal = upper_md_band < short_threshold
For more information on this BB% indicator, find it here:
2. Revolutionary Dominance Matrix System
This is the system's most sophisticated innovation - a comprehensive framework that compares every asset against every other asset to determine relative strength hierarchies.
Mathematical Foundation:
The system constructs a mathematical matrix where each cell represents whether asset i dominates asset j:
// Core dominance matrix (39x39 for maximum assets)
var matrix dominance_matrix = matrix.new(39, 39, 0)
// For each qualifying asset pair (i,j):
for i = 0 to active_count - 1
for j = 0 to active_count - 1
if i != j
// Calculate price ratio BB% TrendSync for asset_i/asset_j
ratio_array = calculate_price_ratios(asset_i, asset_j)
ratio_dbbmd = calculate_dbbmd(ratio_array)
// Asset i dominates j if ratio is in uptrend
if ratio_dbbmd_state == 1
matrix.set(dominance_matrix, i, j, 1)
Copeland Scoring Algorithm:
Each asset receives a dominance score calculated as:
Dominance Score = Total Wins - Total Losses
// Calculate net dominance for each asset
for i = 0 to active_count - 1
wins = 0
losses = 0
for j = 0 to active_count - 1
if i != j
if matrix.get(dominance_matrix, i, j) == 1
wins += 1
else
losses += 1
copeland_score = wins - losses
array.set(dominance_scores, i, copeland_score)
Head-to-Head Analysis Process:
Ratio Construction: For each asset pair, calculate price_asset_A / price_asset_B
DBBMD Application: Apply the same DBBMD analysis to these ratios
Trend Determination: If ratio DBBMD shows uptrend, Asset A dominates Asset B
Matrix Population: Store dominance relationships in mathematical matrix
Score Calculation: Sum wins minus losses for final ranking
This creates a tournament-style ranking where each asset's strength is measured against all others, not just against a benchmark.
3. Advanced Alpha & Beta Filtering System
The system incorporates fundamental analysis through Capital Asset Pricing Model (CAPM) calculations to filter assets based on risk-adjusted performance.
Alpha Calculation (Excess Return Analysis):
// CAPM Alpha calculation
f_calc_alpha(asset_prices, benchmark_prices, alpha_length, beta_length, risk_free_rate) =>
// Calculate asset and benchmark returns
asset_returns = calculate_returns(asset_prices, alpha_length)
benchmark_returns = calculate_returns(benchmark_prices, alpha_length)
// Get beta for expected return calculation
beta = f_calc_beta(asset_prices, benchmark_prices, beta_length)
// Average returns over period
avg_asset_return = array_average(asset_returns) * 100
avg_benchmark_return = array_average(benchmark_returns) * 100
// Expected return using CAPM: E(R) = Beta * Market_Return + Risk_Free_Rate
expected_return = beta * avg_benchmark_return + risk_free_rate
// Alpha = Actual Return - Expected Return
alpha = avg_asset_return - expected_return
Beta Calculation (Volatility Relationship):
// Beta measures how much an asset moves relative to benchmark
f_calc_beta(asset_prices, benchmark_prices, length) =>
// Calculate return series for both assets
asset_returns =
benchmark_returns =
// Populate return arrays
for i = 0 to length - 1
asset_return = (current_price - previous_price) / previous_price
benchmark_return = (current_bench - previous_bench) / previous_bench
// Calculate covariance and variance
covariance = calculate_covariance(asset_returns, benchmark_returns)
benchmark_variance = calculate_variance(benchmark_returns)
// Beta = Covariance(Asset, Market) / Variance(Market)
beta = covariance / benchmark_variance
Filtering Applications:
Alpha Filter: Only includes assets with alpha above specified threshold (e.g., >0.5% monthly excess return)
Beta Filter: Screens for desired volatility characteristics (e.g., beta >1.0 for aggressive assets)
Combined Screening: Both filters must pass for asset qualification
Dynamic Thresholds: User-configurable parameters for different market conditions
4. Intelligent Tie-Breaking Resolution System
When multiple assets have identical dominance scores, the system employs sophisticated methods to determine final rankings.
Standard Tie-Breaking Hierarchy:
// Primary tie-breaking logic
if score_i == score_j // Tied dominance scores
// Level 1: Compare Beta values (higher beta wins)
beta_i = array.get(beta_values, i)
beta_j = array.get(beta_values, j)
if beta_j > beta_i
swap_positions(i, j)
else if beta_j == beta_i
// Level 2: Compare Alpha values (higher alpha wins)
alpha_i = array.get(alpha_values, i)
alpha_j = array.get(alpha_values, j)
if alpha_j > alpha_i
swap_positions(i, j)
Advanced Tie-Breaking (Head-to-Head Analysis):
For the top 3 performers, an enhanced tie-breaking mechanism analyzes direct head-to-head price ratio performance:
// Advanced tie-breaker for top performers
f_advanced_tiebreaker(asset1_idx, asset2_idx, lookback_period) =>
// Calculate price ratio over lookback period
ratio_history =
for k = 0 to lookback_period - 1
price_ratio = price_asset1 / price_asset2
array.push(ratio_history, price_ratio)
// Apply simplified trend analysis to ratio
current_ratio = array.get(ratio_history, 0)
average_ratio = calculate_average(ratio_history)
// Asset 1 wins if current ratio > average (trending up)
if current_ratio > average_ratio
return 1 // Asset 1 dominates
else
return -1 // Asset 2 dominates
5. Five-Component Aggregate Market Regime Filter
This sophisticated framework combines multiple statistical tests to determine whether market conditions favor trending strategies or require defensive positioning.
Component 1: Augmented Dickey-Fuller (ADF) Test
Tests for unit root presence to distinguish between trending and mean-reverting price series.
// Simplified ADF implementation
calculate_adf_statistic(price_series, lookback) =>
// Calculate first differences
differences =
for i = 0 to lookback - 2
diff = price_series - price_series
array.push(differences, diff)
// Statistical analysis of differences
mean_diff = calculate_mean(differences)
std_diff = calculate_standard_deviation(differences)
// ADF statistic approximation
adf_stat = mean_diff / std_diff
// Compare against threshold for trend determination
is_trending = adf_stat <= adf_threshold
Component 2: Directional Movement Index (DMI)
Classic Wilder indicator measuring trend strength through directional movement analysis.
// DMI calculation for trend strength
calculate_dmi_signal(high_data, low_data, close_data, period) =>
// Calculate directional movements
plus_dm_sum = 0.0
minus_dm_sum = 0.0
true_range_sum = 0.0
for i = 1 to period
// Directional movements
up_move = high_data - high_data
down_move = low_data - low_data
// Accumulate positive/negative movements
if up_move > down_move and up_move > 0
plus_dm_sum += up_move
if down_move > up_move and down_move > 0
minus_dm_sum += down_move
// True range calculation
true_range_sum += calculate_true_range(i)
// Calculate directional indicators
di_plus = 100 * plus_dm_sum / true_range_sum
di_minus = 100 * minus_dm_sum / true_range_sum
// ADX calculation
dx = 100 * math.abs(di_plus - di_minus) / (di_plus + di_minus)
adx = dx // Simplified for demonstration
// Trending if ADX above threshold
is_trending = adx > dmi_threshold
Component 3: KPSS Stationarity Test
Complementary test to ADF that examines stationarity around trend components.
// KPSS test implementation
calculate_kpss_statistic(price_series, lookback, significance_level) =>
// Calculate mean and variance
series_mean = calculate_mean(price_series, lookback)
series_variance = calculate_variance(price_series, lookback)
// Cumulative sum of deviations
cumulative_sum = 0.0
cumsum_squared_sum = 0.0
for i = 0 to lookback - 1
deviation = price_series - series_mean
cumulative_sum += deviation
cumsum_squared_sum += math.pow(cumulative_sum, 2)
// KPSS statistic
kpss_stat = cumsum_squared_sum / (lookback * lookback * series_variance)
// Compare against critical values
critical_value = significance_level == 0.01 ? 0.739 :
significance_level == 0.05 ? 0.463 : 0.347
is_trending = kpss_stat >= critical_value
Component 4: Choppiness Index
Measures market directionality using fractal dimension analysis of price movement.
// Choppiness Index calculation
calculate_choppiness(price_data, period) =>
// Find highest and lowest over period
highest = price_data
lowest = price_data
true_range_sum = 0.0
for i = 0 to period - 1
if price_data > highest
highest := price_data
if price_data < lowest
lowest := price_data
// Accumulate true range
if i > 0
true_range = calculate_true_range(price_data, i)
true_range_sum += true_range
// Choppiness calculation
range_high_low = highest - lowest
choppiness = 100 * math.log10(true_range_sum / range_high_low) / math.log10(period)
// Trending if choppiness below threshold (typically 61.8)
is_trending = choppiness < 61.8
Component 5: Hilbert Transform Analysis
Phase-based cycle detection and trend identification using mathematical signal processing.
// Hilbert Transform trend detection
calculate_hilbert_signal(price_data, smoothing_period, filter_period) =>
// Smooth the price data
smoothed_price = calculate_moving_average(price_data, smoothing_period)
// Calculate instantaneous phase components
// Simplified implementation for demonstration
instant_phase = smoothed_price
delayed_phase = calculate_moving_average(price_data, filter_period)
// Compare instantaneous vs delayed signals
phase_difference = instant_phase - delayed_phase
// Trending if instantaneous leads delayed
is_trending = phase_difference > 0
Aggregate Regime Determination:
// Combine all five components
regime_calculation() =>
trending_count = 0
total_components = 0
// Test each enabled component
if enable_adf and adf_signal == 1
trending_count += 1
if enable_adf
total_components += 1
// Repeat for all five components...
// Calculate trending proportion
trending_proportion = trending_count / total_components
// Market is trending if proportion above threshold
regime_allows_trading = trending_proportion >= regime_threshold
The system only allows asset positions when the specified percentage of components indicate trending conditions. During choppy or mean-reverting periods, the system automatically positions in USD to preserve capital.
6. Dynamic Portfolio Weighting Framework
Six sophisticated allocation methodologies provide flexibility for different market conditions and risk preferences.
Weighting Method Implementations:
1. Equal Weight Distribution:
// Simple equal allocation
if weighting_mode == "Equal Weight"
weight_per_asset = 1.0 / selection_count
for i = 0 to selection_count - 1
array.push(weights, weight_per_asset)
2. Linear Dominance Scaling:
// Linear scaling based on dominance scores
if weighting_mode == "Linear Dominance"
// Normalize scores to 0-1 range
min_score = array.min(dominance_scores)
max_score = array.max(dominance_scores)
score_range = max_score - min_score
total_weight = 0.0
for i = 0 to selection_count - 1
score = array.get(dominance_scores, i)
normalized = (score - min_score) / score_range
weight = 1.0 + normalized * concentration_factor
array.push(weights, weight)
total_weight += weight
// Normalize to sum to 1.0
for i = 0 to selection_count - 1
current_weight = array.get(weights, i)
array.set(weights, i, current_weight / total_weight)
3. Conviction Score (Exponential):
// Exponential scaling for high conviction
if weighting_mode == "Conviction Score"
// Combine dominance score with DBBMD strength
conviction_scores =
for i = 0 to selection_count - 1
dominance = array.get(dominance_scores, i)
dbbmd_strength = array.get(dbbmd_values, i)
conviction = dominance + (dbbmd_strength - 50) / 25
array.push(conviction_scores, conviction)
// Exponential weighting
total_weight = 0.0
for i = 0 to selection_count - 1
conviction = array.get(conviction_scores, i)
normalized = normalize_score(conviction)
weight = math.pow(1 + normalized, concentration_factor)
array.push(weights, weight)
total_weight += weight
// Final normalization
normalize_weights(weights, total_weight)
Advanced Features:
Minimum Position Constraint: Prevents dust allocations below specified threshold
Concentration Factor: Adjustable parameter controlling weight distribution aggressiveness
Dominance Boost: Extra weight for assets exceeding specified dominance thresholds
Dynamic Rebalancing: Automatic weight recalculation on portfolio changes
7. Intelligent USD Management System
The system treats USD as a competing asset with its own dominance score, enabling sophisticated cash management.
USD Scoring Methodologies:
Smart Competition Mode (Recommended):
f_calculate_smart_usd_dominance() =>
usd_wins = 0
// USD beats assets in downtrends or weak uptrends
for i = 0 to active_count - 1
asset_state = get_asset_state(i)
asset_dbbmd = get_asset_dbbmd(i)
// USD dominates shorts and weak longs
if asset_state == -1 or (asset_state == 1 and asset_dbbmd < long_threshold)
usd_wins += 1
// Calculate Copeland-style score
base_score = usd_wins - (active_count - usd_wins)
// Boost during weak market conditions
qualified_assets = count_qualified_long_assets()
if qualified_assets <= active_count * 0.2
base_score := math.round(base_score * usd_boost_factor)
base_score
Auto Short Count Mode:
// USD dominance based on number of bearish assets
usd_dominance = count_assets_in_short_state()
// Apply boost during low activity
if qualified_long_count <= active_count * 0.2
usd_dominance := usd_dominance * usd_boost_factor
Regime-Based USD Positioning:
When the five-component regime filter indicates unfavorable conditions, the system automatically overrides all asset signals and positions 100% in USD, protecting capital during choppy markets.
8. Multi-Asset Infrastructure & Data Management
The system maintains comprehensive data structures for up to 39 assets simultaneously.
Data Collection Framework:
// Full OHLC data matrices (200 bars depth for performance)
var matrix open_data = matrix.new(39, 200, na)
var matrix high_data = matrix.new(39, 200, na)
var matrix low_data = matrix.new(39, 200, na)
var matrix close_data = matrix.new(39, 200, na)
// Real-time data collection
if barstate.isconfirmed
for i = 0 to active_count - 1
ticker = array.get(assets, i)
= request.security(ticker, timeframe.period,
[open , high , low , close ],
lookahead=barmerge.lookahead_off)
// Store in matrices with proper shifting
matrix.set(open_data, i, 0, nz(o, 0))
matrix.set(high_data, i, 0, nz(h, 0))
matrix.set(low_data, i, 0, nz(l, 0))
matrix.set(close_data, i, 0, nz(c, 0))
Asset Configuration:
The system comes pre-configured with 39 major cryptocurrency pairs across multiple exchanges:
Major Pairs: BTC, ETH, XRP, SOL, DOGE, ADA, etc.
Exchange Coverage: Binance, KuCoin, MEXC for optimal liquidity
Configurable Count: Users can activate 2-39 assets based on preferences
Custom Tickers: All asset selections are user-modifiable
---
⚙️ COMPREHENSIVE CONFIGURATION GUIDE
Portfolio Management Settings
Maximum Portfolio Size (1-10):
Conservative (1-2): High concentration, captures strong trends
Balanced (3-5): Moderate diversification with trend focus
Diversified (6-10): Lower concentration, broader market exposure
Dominance Clarity Threshold (0.1-1.0):
Low (0.1-0.4): Prefers diversification, holds multiple assets frequently
Medium (0.5-0.7): Balanced approach, context-dependent allocation
High (0.8-1.0): Concentration-focused, single asset preference
Signal Generation Parameters
DBBMD Thresholds:
// Standard configuration
primary_long_threshold = 71 // Conservative: 75+, Aggressive: 65-70
primary_short_threshold = 33 // Conservative: 25-30, Aggressive: 35-40
// BB System parameters
bb1_ma_len = 40 // Fast system: 20-50
bb1_sd_len = 65 // Stability: 50-80
bb2_ma_len = 8 // Trend: 60-100
bb2_sd_len = 66 // Sensitivity: 10-20
Risk Management Configuration
Alpha/Beta Filters:
Alpha Threshold: 0.0-2.0% (higher = more selective)
Beta Threshold: 0.5-2.0 (1.0+ for aggressive assets)
Calculation Periods: 20-50 bars (longer = more stable)
Regime Filter Settings:
Trending Threshold: 0.3-0.8 (higher = stricter trend requirements)
Component Lookbacks: 30-100 bars (balance responsiveness vs stability)
Enable/Disable: Individual component control for customization
---
📊 PERFORMANCE TRACKING & VISUALIZATION
Real-Time Dashboard Features
The compact dashboard provides essential information:
Current Holdings: Asset names and allocation percentages
Dominance Score: Current position's relative strength ranking
Active Assets: Qualified long signals vs total asset count
Returns: Total portfolio performance percentage
Maximum Drawdown: Peak-to-trough decline measurement
Trade Count: Total portfolio transitions executed
Regime Status: Current market condition assessment
Comprehensive Ranking Table
The left-side table displays detailed asset analysis:
Ranking Position: Numerical order by dominance score
Asset Symbol: Clean ticker identification with color coding
Dominance Score: Net wins minus losses in head-to-head comparisons
Win-Loss Record: Detailed breakdown of dominance relationships
DBBMD Reading: Current momentum percentage with threshold highlighting
Alpha/Beta Values: Fundamental analysis metrics when filters enabled
Portfolio Weight: Current allocation percentage in signal portfolio
Execution Status: Visual indicator of actual holdings vs signals
Visual Enhancement Features
Color-Coded Assets: 39 distinct colors for easy identification
Regime Background: Red tinting during unfavorable market conditions
Dynamic Equity Curve: Portfolio value plotted with position-based coloring
Status Indicators: Symbols showing execution vs signal states
---
🔍 ADVANCED TECHNICAL FEATURES
State Persistence System
The system maintains asset states across bars to prevent excessive switching:
// State tracking for each asset and ratio combination
var array asset_states = array.new(1560, 0) // 39 * 40 ratios
// State changes only occur on confirmed threshold breaks
if long_crossover and current_state != 1
current_state := 1
array.set(asset_states, asset_index, 1)
else if short_crossover and current_state != -1
current_state := -1
array.set(asset_states, asset_index, -1)
Transaction Cost Integration
Realistic modeling of trading expenses:
// Transaction cost calculation
transaction_fee = 0.4 // Default 0.4% (fees + slippage)
// Applied on portfolio transitions
if should_execute_transition
was_holding_assets = check_current_holdings()
will_hold_assets = check_new_signals()
// Charge fees for meaningful transitions
if transaction_fee > 0 and (was_holding_assets or will_hold_assets)
fee_amount = equity * (transaction_fee / 100)
equity -= fee_amount
total_fees += fee_amount
Dynamic Memory Management
Optimized data structures for performance:
200-Bar History: Sufficient for calculations while maintaining speed
Matrix Operations: Efficient storage and retrieval of multi-asset data
Array Recycling: Memory-conscious data handling for long-running backtests
Conditional Calculations: Skip unnecessary computations during initialization
12H 30 assets portfolio
---
🚨 SYSTEM LIMITATIONS & TESTING STATUS
CURRENT DEVELOPMENT PHASE: ACTIVE TESTING & OPTIMIZATION
This system represents cutting-edge algorithmic trading technology but remains in continuous development. Key considerations:
Known Limitations:
Requires significant computational resources for 39-asset analysis
Performance varies significantly across different market conditions
Complex parameter interactions may require extensive optimization
Slippage and liquidity constraints not fully modeled for all assets
No consideration for market impact in large position sizes
Areas Under Active Development:
Enhanced regime detection algorithms
Improved transaction cost modeling
Additional portfolio weighting methodologies
Machine learning integration for parameter optimization
Cross-timeframe analysis capabilities
---
🔒 ANTI-REPAINTING ARCHITECTURE & LIVE TRADING READINESS
One of the most critical aspects of any trading system is ensuring that signals and calculations are based on confirmed, historical data rather than current bar information that can change throughout the trading session. This system implements comprehensive anti-repainting measures to ensure 100% reliability for live trading .
The Repainting Problem in Trading Systems
Repainting occurs when an indicator uses current, unconfirmed bar data in its calculations, causing:
False Historical Signals: Backtests appear better than reality because calculations change as bars develop
Live Trading Failures: Signals that looked profitable in testing fail when deployed in real markets
Inconsistent Results: Different results when running the same indicator at different times during a trading session
Misleading Performance: Inflated win rates and returns that cannot be replicated in practice
GForge Anti-Repainting Implementation
This system eliminates repainting through multiple technical safeguards:
1. Historical Data Usage for All Calculations
// CRITICAL: All calculations use PREVIOUS bar data (note the offset)
= request.security(ticker, timeframe.period,
[open , high , low , close , close],
lookahead=barmerge.lookahead_off)
// Store confirmed previous bar OHLC for calculations
matrix.set(open_data, i, 0, nz(o1, 0)) // Previous bar open
matrix.set(high_data, i, 0, nz(h1, 0)) // Previous bar high
matrix.set(low_data, i, 0, nz(l1, 0)) // Previous bar low
matrix.set(close_data, i, 0, nz(c1, 0)) // Previous bar close
// Current bar close only for visualization
matrix.set(current_prices, i, 0, nz(c0, 0)) // Live price display
2. Confirmed Bar State Processing
// Only process data when bars are confirmed and closed
if barstate.isconfirmed
// All signal generation and portfolio decisions occur here
// using only historical, unchanging data
// Shift historical data arrays
for i = 0 to active_count - 1
for bar = math.min(data_bars, 199) to 1
// Move confirmed data through historical matrices
old_data = matrix.get(close_data, i, bar - 1)
matrix.set(close_data, i, bar, old_data)
// Process new confirmed bar data
calculate_all_signals_and_dominance()
3. Lookahead Prevention
// Explicit lookahead prevention in all security calls
request.security(ticker, timeframe.period, expression,
lookahead=barmerge.lookahead_off)
// This ensures no future data can influence current calculations
// Essential for maintaining signal integrity across all timeframes
4. State Persistence with Historical Validation
// Asset states only change based on confirmed threshold breaks
// using historical data that cannot change
var array asset_states = array.new(1560, 0)
// State changes use only confirmed, previous bar calculations
if barstate.isconfirmed
=
f_calculate_enhanced_dbbmd(confirmed_price_array, ...)
// Only update states after bar confirmation
if long_crossover_confirmed and current_state != 1
current_state := 1
array.set(asset_states, asset_index, 1)
Live Trading vs. Backtesting Consistency
The system's architecture ensures identical behavior in both environments:
Backtesting Mode:
Uses historical offset data for all calculations
Processes confirmed bars with `barstate.isconfirmed`
Maintains identical signal generation logic
No access to future information
Live Trading Mode:
Uses same historical offset data structure
Waits for bar confirmation before signal updates
Identical mathematical calculations and thresholds
Real-time price display without affecting signals
Technical Implementation Details
Data Collection Timing
// Example of proper data collection timing
if barstate.isconfirmed // Wait for bar to close
// Collect PREVIOUS bar's confirmed OHLC data
for i = 0 to active_count - 1
ticker = array.get(assets, i)
// Get confirmed previous bar data (note offset)
=
request.security(ticker, timeframe.period,
[open , high , low , close , close],
lookahead=barmerge.lookahead_off)
// ALL calculations use prev_* values
// current_close only for real-time display
portfolio_calculations_use_previous_bar_data()
Signal Generation Process
// Signal generation workflow (simplified)
if barstate.isconfirmed and data_bars >= minimum_required_bars
// Step 1: Calculate DBBMD using historical price arrays
for i = 0 to active_count - 1
historical_prices = get_confirmed_price_history(i) // Uses offset data
= calculate_dbbmd(historical_prices)
update_asset_state(i, state)
// Step 2: Build dominance matrix using confirmed data
calculate_dominance_relationships() // All historical data
// Step 3: Generate portfolio signals
new_portfolio = generate_target_portfolio() // Based on confirmed calculations
// Step 4: Compare with previous signals for changes
if portfolio_signals_changed()
execute_portfolio_transition()
Verification Methods for Users
Users can verify the anti-repainting behavior through several methods:
1. Historical Replay Test
Run the indicator on historical data
Note signal timing and portfolio changes
Replay the same period - signals should be identical
No retroactive changes in historical signals
2. Intraday Consistency Check
Load indicator during active trading session
Observe that previous day's signals remain unchanged
Only current day's final bar should show potential signal changes
Refresh indicator - historical signals should be identical
Live Trading Deployment Considerations
Data Quality Assurance
Exchange Connectivity: Ensure reliable data feeds for all 39 assets
Missing Data Handling: System includes safeguards for data gaps
Price Validation: Automatic filtering of obvious price errors
Timeframe Synchronization: All assets synchronized to same bar timing
Performance Impact of Anti-Repainting Measures
The robust anti-repainting implementation requires additional computational resources:
Memory Usage: 200-bar historical data storage for 39 assets
Processing Delay: Signals update only after bar confirmation
Calculation Overhead: Multiple historical data validations
Alert Timing: Slight delay compared to current-bar indicators
However, these trade-offs are essential for reliable live trading performance and accurate backtesting results.
Critical: Equity Curve Anti-Repainting Architecture
The most sophisticated aspect of this system's anti-repainting design is the temporal separation between signal generation and performance calculation . This creates a realistic trading simulation that perfectly matches live trading execution.
The Timing Sequence
// STEP 1: Store what we HELD during the current bar (for performance calc)
if barstate.isconfirmed
// Record positions that were active during this bar
array.clear(held_portfolio)
array.clear(held_weights)
for i = 0 to array.size(execution_portfolio) - 1
array.push(held_portfolio, array.get(execution_portfolio, i))
array.push(held_weights, array.get(execution_weights, i))
// STEP 2: Calculate performance based on what we HELD
portfolio_return = 0.0
for i = 0 to array.size(held_portfolio) - 1
held_asset = array.get(held_portfolio, i)
held_weight = array.get(held_weights, i)
// Performance from current_price vs reference_price
// This is what we ACTUALLY earned during this bar
if held_asset != "USD"
current_price = get_current_price(held_asset) // End of bar
reference_price = get_reference_price(held_asset) // Start of bar
asset_return = (current_price - reference_price) / reference_price
portfolio_return += asset_return * held_weight
// STEP 3: Apply return to equity (realistic timing)
equity := equity * (1 + portfolio_return)
// STEP 4: Generate NEW signals for NEXT period (using confirmed data)
= f_generate_target_portfolio()
// STEP 5: Execute transitions if signals changed
if signal_changed
// Update execution_portfolio for NEXT bar
array.clear(execution_portfolio)
array.clear(execution_weights)
for i = 0 to array.size(new_signal_portfolio) - 1
array.push(execution_portfolio, array.get(new_signal_portfolio, i))
array.push(execution_weights, array.get(new_signal_weights, i))
Why This Prevents Equity Curve Repainting
Performance Attribution: Returns are calculated based on positions that were **actually held** during each bar, not future signals
Signal Timing: New signals are generated **after** performance calculation, affecting only **future** bars
Realistic Execution: Mimics real trading where you earn returns on current positions while planning future moves
No Retroactive Changes: Once a bar closes, its performance contribution to equity is permanent and unchangeable
The One-Bar Offset Mechanism
This system implements a critical one-bar timing offset:
// Bar N: Performance Calculation
// ================================
// 1. Calculate returns on positions held during Bar N
// 2. Update equity based on actual holdings during Bar N
// 3. Plot equity point for Bar N (based on what we HELD)
// Bar N: Signal Generation
// ========================
// 4. Generate signals for Bar N+1 (using confirmed Bar N data)
// 5. Send alerts for what will be held during Bar N+1
// 6. Update execution_portfolio for Bar N+1
// Bar N+1: The Cycle Continues
// =============================
// 1. Performance calculated on positions from Bar N signals
// 2. New signals generated for Bar N+2
Alert System Timing
The alert system reflects this sophisticated timing:
Transaction Cost Realism
Even transaction costs follow realistic timing:
// Fees applied when transitioning between different portfolios
if should_execute_transition
// Charge fees BEFORE taking new positions (realistic timing)
if transaction_fee > 0
fee_amount = equity * (transaction_fee / 100)
equity -= fee_amount // Immediate cost impact
total_fees += fee_amount
// THEN update to new portfolio
update_execution_portfolio(new_signals)
transitions += 1
// Fees reduce equity immediately, affecting all future calculations
// This matches real trading where fees are deducted upon execution
LIVE TRADING CERTIFICATION:
This system has been specifically designed and tested for live trading deployment. The comprehensive anti-repainting measures ensure that:
Backtesting results accurately represent real trading potential
Signals are generated using only confirmed, historical data
No retroactive changes can occur to previously generated signals
Portfolio transitions are based on reliable, unchanging calculations
Performance metrics reflect realistic trading outcomes including proper timing
Users can deploy this system with confidence that live trading results will closely match backtesting performance, subject to normal market execution factors such as slippage and liquidity.
---
⚡ ALERT SYSTEM & AUTOMATION
The system provides comprehensive alerting for automation and monitoring:
Available Alert Conditions
Portfolio Signal Change: Triggered when new portfolio composition is generated
Regime Override Active: Alerts when market regime forces USD positioning
Individual Asset Signals: Can be configured for specific asset transitions
Performance Thresholds: Drawdown or return-based notifications
---
📈 BACKTESTING & PERFORMANCE ANALYSIS
8 Comprehensive Metrics Tracking
The system maintains detailed performance statistics:
Equity Curve: Real-time portfolio value progression
Returns Calculation: Total and annualized performance metrics
Drawdown Analysis: Peak-to-trough decline measurements
Transaction Counting: Portfolio transition frequency
Fee Tracking: Cumulative transaction cost impact
Win Rate Analysis: Success rate of position changes
Backtesting Configuration
// Backtesting parameters
initial_capital = 10000.0 // Starting capital
use_custom_start = true // Enable specific start date
custom_start = timestamp("2023-09-01") // Backtest beginning
transaction_fee = 0.4 // Combined fees and slippage %
// Performance calculation
total_return = (equity - initial_capital) / initial_capital * 100
current_drawdown = (peak_equity - equity) / peak_equity * 100
---
🔧 TROUBLESHOOTING & OPTIMIZATION
Common Configuration Issues
Insufficient Data: Ensure 100+ bars available before start date
[*} Not Compiling: Go on an asset's price chart with 2 or 3 years of data to
make the system compile or just simply reapply the indicator again
Too Many Assets: Reduce active count if experiencing timeouts
Regime Filter Too Strict: Lower trending threshold if always in USD
Excessive Switching: Increase MD multiplier or adjust thresholds
---
💡 USER FEEDBACK & ENHANCEMENT REQUESTS
The continuous evolution of this system depends heavily on user experience and community feedback. Your insights will help motivate me for new improvements and new feature developments.
---
⚖️ FINAL COMPREHENSIVE RISK DISCLAIMER
TRADING INVOLVES SUBSTANTIAL RISK OF LOSS
This indicator is a sophisticated analytical tool designed for educational and research purposes. Important warnings and considerations:
System Limitations:
No algorithmic system can guarantee profitable outcomes
Complex systems may fail in unexpected ways during extreme market events
Historical backtesting does not account for all real-world trading challenges
Slippage, liquidity constraints, and market impact can significantly affect results
System parameters require careful optimization and ongoing monitoring
The creator and distributor of this indicator assume no liability for any financial losses, system failures, or adverse outcomes resulting from its use. This tool is provided "as is" without any warranties, express or implied.
By using this indicator, you acknowledge that you have read, understood, and agreed to assume all risks associated with algorithmic trading and cryptocurrency investments.
GKD-C Wavelet Oscillator [Loxx]The Giga Kaleidoscope GKD-C Wavelet Oscillator is a Confirmation module included in AlgxTrading's "Giga Kaleidoscope Modularized Trading System."
█ GKD-C Wavelet Oscillator, a brief overview
The Wavelet Oscillator is an advanced technical analysis tool that integrates wavelet transformations with the Kalman filter to provide a nuanced understanding of market trends and momentum. At the heart of this oscillator is the Haar wavelet transform, a mathematical technique that breaks down price data into different frequency components. The Haar transform works by analyzing the price series in pairs, calculating the average and difference between adjacent data points, effectively separating the underlying signal (trend) from noise or minor fluctuations. This decomposition allows the oscillator to isolate significant price movements and reconstruct them with greater clarity through the inverse Haar transform. The Kalman filter is then applied to further smooth the signal, refining the data and reducing the impact of short-term volatility.
This process enhances the oscillator's ability to detect subtle shifts in market dynamics that might be missed by conventional indicators. The GKD-C Wavelet Oscillator utilizes these refined signals to generate two types of trading signals: Zero-line crosses, where the oscillator moves above or below a central reference point, indicating potential bullish or bearish momentum, and Signal crosses, where the current oscillator value crosses its previous value, signaling possible trend reversals. These features make the Wavelet Oscillator particularly effective in identifying key turning points in the market, providing traders with a powerful tool for anticipating and responding to changes in price momentum within the GKD trading system. (Read the sections below to learn how traders can test these different signal types using AlgxTrading's GKD trading system.)
GKD-C Wavelet Oscillator in Zero-line crosses mode
GKD-C Wavelet Oscillator in Signal crosses mode
To explain the features included in the GKD-C Wavelet Oscillator, let's first dive into the details of the Giga Kaleidoscope (GKD) Modularized Trading System.
█ Giga Kaleidoscope (GKD) Modularized Trading System
The GKD Trading System is a comprehensive, algorithmic trading framework from AlgxTrading, designed to optimize trading strategies across various market conditions. It employs a modular approach, incorporating elements such as volatility assessment, trend identification through a baseline, multiple confirmation strategies for signal accuracy, and volume analysis. Key components also include specialized strategies for entry and exit, enabling precise trade execution. The system allows for extensive backtesting, providing traders with the ability to evaluate the effectiveness of their strategies using historical data. Aimed at reducing setup time, the GKD system empowers traders to focus more on strategy refinement and execution, leveraging a wide array of technical indicators for informed decision-making.
🔶 Core components of a GKD Algorithmic Trading System
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system. The GKD algorithm is built on the principles of trend, momentum, and volatility. There are eight core components in the GKD trading algorithm:
🔹 Volatility - In the GKD trading system, volatility is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. There are 17+ different types of volatility available in the GKD system including Average True Range (ATR), True Range Double (TRD), Close-to-Close, Garman-Klass, and more.
🔹 Baseline (GKD-B) - The baseline is essentially a moving average and is used to determine the overall direction of the market. The baseline in the GKD trading system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other GKD indicators.
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards or price is above the baseline, then only long trades are taken, and if the baseline is sloping downwards or price is below the baseline, then only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
🔹 Confirmation 1, Confirmation 2, Continuation (GKD-C) - The GKD trading system incorporates technical confirmation indicators for the generation of its primary long and short signals, essential for its operation.
The GKD trading system distinguishes three specific categories. The first category, Confirmation 1, encompasses technical indicators designed to identify trends and generate explicit trading signals. The second category, Confirmation 2, a technical indicator used to identify trends; this type of indicator is primarily used to filter the Confirmation 1 indicator signals; however, this type of confirmation indicator also generates signals*. Lastly, the Continuation category includes technical indicators used in conjunction with Confirmation 1 and Confirmation 2 to generate a special type of trading signal called a "Continuation"
In a full GKD trading system all three categories generate signals. (see the section “GKD Trading System Signals” below)
🔹 Volatility/Volume (GKD-V) - Volatility/Volume indicators are used to measure the amount of buying and selling activity in a market. They are based on the trading Volatility/Volume of the market, and can provide information about the strength of the trend. In the GKD trading system, Volatility/Volume indicators are used to confirm trading signals generated by the various other GKD indicators. In the GKD trading system, Volatility is a proxy for Volume and vice versa.
Volatility/Volume indicators reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by GKD-C confirmation and GKD-B baseline indicators.
🔹 Exit (GKD-E) - The exit indicator in the GKD system is an indicator that is deemed effective at identifying optimal exit points. The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
🔹 Backtest (GKD-BT) - The GKD-BT backtest indicators link all other GKD-C, GKD-B, GKD-E, GKD-V, and GKD-M components together to create a GKD trading system. GKD-BT backtests generate signals (see the section “GKD Trading System Signals” below) from the confluence of various GKD indicators that are imported into the GKD-BT backtest. Backtest types include: GKD-BT solo and full GKD backtest strategies used for a single ticker; GKD-BT optimizers used to optimize a single indicator or the full GKD trading system; GKD-BT Multi-ticker used to backtest a single indicator or the full GKD trading system across up to ten tickers; GKD-BT exotic backtests like CC, Baseline, and Giga Stacks used to test confluence between GKD components to then be injected into a core GKD-BT Multi-ticker backtest or single ticker strategy.
🔹 Metamorphosis (GKD-M)** - The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, GKD-E, or GKD-V slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
*(see the section “GKD Trading System Signals” below)
**(not a required component of the GKD algorithm)
🔶 What does the application of the GKD trading system look like?
Example trading system:
Volatility: Average True Range (ATR) (selectable in all backtests and other related GKD indicators)
GKD-B Baseline: GKD-B Multi-Ticker Baseline using Hull Moving Average
GKD-C Confirmation 1: GKD-C Advance Trend Pressure
GKD-C Confirmation 2: GKD-C Dorsey Inertia
GKD-C Continuation: GKD-C Stochastic of RSX
GKD-V Volatility/Volume: GKD-V Damiani Volatmeter
GKD-E Exit: GKD-E MFI
GKD-BT Backtest: GKD-BT Multi-Ticker Full GKD Backtest
GKD-M Metamorphosis: GKD-M Baseline Optimizer
**all indicators mentioned above are included in the same AlgxTrading package**
Each module is passed to a GKD-BT backtest module. In the backtest module, all components are combined to formulate trading signals and statistical output. This chaining of indicators requires that each module conform to AlgxTrading's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the various indictor types in the GKD algorithm.
🔶 GKD Trading System Signals
🔹 Standard Entry requires a sequence of conditions including a confirmation signal from GKD-C, baseline agreement, price criteria related to the Goldie Locks Zone, and concurrence from a second confirmation and volatility/volume indicators.
🔹 1-Candle Standard Entry introduces a two-phase process where initial conditions must be met, followed by a retraction in price and additional confirmations in the subsequent candle, including baseline, confirmations 1 and 2, and volatility/volume criteria.
🔹 Baseline Entry focuses on signals generated by the GKD-B Baseline, requiring agreement from confirmation signals, specific price conditions within the Goldie Locks Zone, and a timing condition related to the confirmation 1 signal.
🔹 1-Candle Baseline Entry mirrors the baseline entry but adds a requirement for a price retraction and subsequent confirmations in the following candle, maintaining the focus on the baseline's guidance.
🔹 Volatility/Volume Entry is predicated on signals from volatility/volume indicators, requiring support from confirmations, price criteria within the Goldie Locks Zone, baseline agreement, and a timing condition for the confirmation 1 signal.
🔹 1-Candle Volatility/Volume Entry adapts the volatility/volume entry to include a phase of initial signal and agreement, followed by a retracement phase that seeks further agreement from the system's components in the subsequent candle.
🔹 Confirmation 2 Entry is based on the second confirmation signal, requiring the first confirmation's agreement, specific price criteria, agreement from volatility/volume indicators, and baseline, with a timing condition for the confirmation 1 signal.
🔹 1-Candle Confirmation 2 Entry adds a retracement requirement to the confirmation 2 entry, necessitating additional agreements from the system's components in the candle following the signal.
🔹 PullBack Entry initiates with a baseline signal and agreement from the first confirmation, with a price condition related to volatility. It then looks for price to return within the Goldie Locks Zone and seeks further agreement from the system's components in the subsequent candle.
🔹 Continuation Entry allows for the continuation of an active position, based on a previously triggered entry strategy. It requires that the baseline hasn't crossed since the initial trigger, alongside ongoing agreements from confirmations and the baseline.
█ GKD-C Wavelet Oscillator, a deep dive
Now that you have a basic understanding of the GKD trading system. let's dive deeper into the features included in the GKD-C Wavelet Oscillator
🔶 GKD-C Wavelet Oscillator Modes aka "Confirmation Type"
The GKD-C Wavelet Oscillator has 4 modes: Confirmation for confirmation 1 and 2; Continuation; Multi-ticker for multi-ticker confirmation 1 and 2; and Optimizer.
🔹 Confirmation: When in this mode, the GKD-C Wavelet Oscillator generates confirmation 1 and 2 signals. These values can then be exported to a GKD-BT backtest strategy.
Signal Key: L = Long, S = Short
GKD-C Wavelet Oscillator in Confirmation mode
Confirmation Exports
GKD-C Wavelet Oscillator in attached to a GKD-BT backtest strategy
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
🔹 Continuation: When in this mode, the GKD-C Wavelet Oscillator generates continuation signals.
Signal Key: L = Long, S = Short, CL = Continuation Long, CS = Continuation Short
GKD-C Wavelet Oscillator in Continuation mode
Continuation Exports
🔹 Multi-ticker: When in this mode, the GKD-C Wavelet Oscillator generates multi-ticker confirmation 1 and 2. This mode allows users to generate confirmation 1 and 2, and continuation signals for up to 10 different tickers. These values can then be exported to a GKD-BT Multi-ticker backtest.
Signal Key: L = Long, S = Short
GKD-C Wavelet Oscillator in Multi-ticker mode
Multi-ticker Exports
GKD-C Wavelet Oscillator attached to the GKD-BT Multi-ticker SCS Backtest
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
🔹 Optimizer: When in this mode, the GKD-C Wavelet Oscillator generates optimization signals. These signals allow the user to backtest a range of input values. These values are exported to a GKD-BT optimizer backtest.
Signal Key: L = Long, S = Short
GKD-C Wavelet Oscillator in Optimizer mode
Optimizer Inputs and Exports
GKD-C Wavelet Oscillator attacked to the GKD-BT Optimizer SCS Backtest
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
█ Conclusion
The GKD-C Wavelet Oscillator serves as a multi-modal component of the GKD trading system allowing traders to optimize and backtest acorss a range of input parameters and tickers. These features decrease total build time required to create a custom GKD algorithmic trading system by allowing users to spend more time trading and less time guessing.
█ How to Access
You can see the Author's Instructions below to learn how to get access.

Mxwll OptAlgoIntroducing the Mxwll OptAlgo
Mxwll OptAlgo is a sophisticated algorithmic trading tool designed to identify potential long and short signals. It leverages an optimized combination of the M-Swift average, M-Smooth average, and M-RSI to fine-tune custom lengths and improve signal accuracy. The Mxwll OptAlgo provides long and short signals across various trading assets and timeframes. Additionally, it features optimized Take Profit (TP) and Stop Loss (SL) settings to help traders manage risk.
Key Features
Step-by-Step Complete Optimization: A systematic approach to optimize trading parameters.
Buy/Sell Signals: Clear indicators for long and short positions.
Easy to Use: User-friendly interface for seamless trading.
Predictive counter trend channels
Integrated trend following system and counter trend trading system
3-optimized strategies working cooperatively
Alerts and auto trading capabilities
How It Works
The Mxwll OptAlgo is comprised of three strategies:
Trend following using the OptAlgo
AI Reversal counter trend trading
Market crash shorting
Mxwll OptAlgo can be used for market analysis and trading similarly to any moving average.
The Mxwll OptAlgo MA is composed of two distinct moving averages to be used for trend following strategies.
M-Swift Average: The M-Swift Average accounts for volume and weights current price movement heavier than older price movement - allowing for improved responsiveness to current price movement. Volume is additionally weighted to the average to determine the significance of the price move and the resulting response of the M-Swift average. The M-Swift average consists of an HVWMA with OBV weighting. The HVWMA is used to create a moving average that adapts to volume, attempting to respond to significant price moves with high volume quicker and significant price moves with low volume slower - which might not be indicative of the start of a strong trend. To further reduce the M-Swift average’s responsiveness to weak volume price moves, the average is weighted with a normalized OBV. With this, the M-Swift moving average uses these two indicators to create a responsive moving average to significant price moves with high volume.
M-Smooth Average: The M-Smooth average consists of a McGinley average.
The McGinley Average is designed to address some of the limitations of traditional moving averages, such as the Simple Moving Average (SMA) or Exponential Moving Average (EMA), by reducing their lag and more accurately reflecting the market's true movements, especially during periods of volatility.
The McGinley Dynamic automatically adjusts its smoothing factor based on market speed. This means it responds more quickly to fast-moving markets and slows down during periods of consolidation, reducing the likelihood of false signals.
Unlike traditional moving averages that have a fixed period and can lag significantly behind fast-moving prices, the McGinley Dynamic adjusts dynamically, which helps to reduce lag and keeps the moving average closer to the price action.
The M-Smooth average uses bar low prices as a series during an uptrend - bar high prices as a series during a downtrend. A cross above the M-Smooth average indicates an uptrend, while a cross below the M-Smooth average indicates a downtrend. When this cross event occurs the M-Smooth average will “flip” from calculating on lows to highs, or highs to lows, contingent on the direction of the trend. The expectation is that a cross event of the M-Smooth average requires a substantial price move and, subsequent to this cross, price will continue to trend in the direction of the cross.
OptAlgo: The OptAlgo is simply the average of the M-Swift average and the M-smooth average.
By combining the M-Swift average and the M-Smooth average, the final output results in an average that slows during ranging markets and quickly adjusts to high volume breakouts and high volume reversals that initiate a trend. Due to the combination, the average will keep up quickly with a trend but remain at an appropriate distance from the current price - requiring a significant counter trend price move to change the direction of the OptAlgo average.
How does the OptAlgo follow trends?
The OptAlgo, comprising the two moving averages above, considers a cross event of the OptAlgo as a change in trend indication. The OptAlgo can be thought of as a moving average that significantly deviates from price. For price to cross the OptAlgo, a substantial price move must occur, and this event is treated as a "strong trend" or "new trend" indication.
M-RSI: The M-RSI is a fundamental component of the trend following strategy. Prior to a trend following “long” or “short” signal, the M-RSI must generate a signal in confluence with an OptAlgo cross event. When price crosses over the opt algo its color will change to green, indicating an uptrend. A buy signal will generate should the M-RSI provide a similar indication. The M-RSI portion of the trend following strategy is explained below. When price crosses under the opt algo its color will change to green, indicating a downtrend, and a sell signal becomes eligible. The foundational logic for using the Opt Algo as a trend following strategy is to treat crossovers/crossunders of the Opt Algo as strong trend indications, and trade them.
Steps to generate a trend following long signal:
1: M-RSI extends into oversold territory
2: Price crosses over the OptAlgo
Steps to generate a trend following short signal:
1: M-RSI extends into overbought territory
2: Price crosses under the OptAlgo
Our trend following strategy considers crossovers/crossunders at key market turning points as buy/sell opportunities. This strategy integrates the Mxwll RSI and Mxwll OptAlgo MA to determine entry points in anticipation of trend continuation.
The Mxwll RSI must move below/above the optimized OB/OS level prior to a cross event for a long/short signal to be considered. Entry points for this strategy are marked as "Long" or "Short".
At its core, the OptAlgo trend following strategy tries to enter a trend as close to the origin point as possible. As with any trend following strategy, price may not continue to move in the expected direction following entry, resulting in a losing trade.
AI Reversal Predictions
Our AI reversals strategy uses AI suggested turning points to capitalize on price reversions back towards the OptAlgo. These levels are considered by the AI on the selected days, and entry points at these levels are marked as "LLO" or "SLO".
How AI reversals work
Our AI reversals strategy attempts to trade price reversions back toward the Opt Algo.
These levels are calculated on specific days of the week, but can be traded any day. The internal algorithm determines which HTF highs/lows are most likely to function as tradable support/resistance levels. For instance, if Friday consists of heavy trading activity and high/low prices are tracked/recorded as causing significant support / resistance when tested in the future, the algorithm will consider support and resistance levels created on Friday as future tradable levels.
Additionally, if support/resistance levels created on Wednesday are recorded as weak or unpredictable when traded at in the future, the algorithm will not consider support/resistance levels generated on Thursday as tradable, and will not generate long or shit signals for these levels.
In the background, the AI reversals strategy is tracking success rates at multiple support and resistance levels. The best performers, if there are any, will be considered tradable. A “best performer” is calculated as the raw price move up to a threshold (i.e. 0.5%) that occurs subsequent to a test of the level.
Crash Short
The "Crash Short" strategy prioritizes short positions during retracements of a sell off. A simple yet effective strategy.
How Crash Short Works
The Crash Short strategy uses a customized momentum indicator (similar to ROC, MOM, etc.) to identify strong downside price moves. When our customized momentum indicator gives strong sell indications, the RSI is then referenced to identify an upside retracement. When the RSI exceeds a user-inputted level, a “Crash Short” signal is generated.
What is the customized momentum indicator?
The customized momentum indicator is the RoCR (Rate of Change Ratio). Instead of classic ROC, which is close - close , the RoCR divides the current close by a previous close. This formula creates a ratio that is more normalized than a simple price difference. This ratio is used to determine upside/downside momentum, with values greater than 1 indicating bullish momentum and values less than 1 indicating bearish momentum. The RoCR looks for deviating values to the downside (less than 1) to identify strong selling. From there, once the RSI crosses over an optimized level (such as 35), the indicator will print a sell signal titled "Crash Short".
Predictive Countertrend Channels
Our Predictive Countertrend Channel applies a two-stage recursive filter to smooth data using exponential decay and periodic adjustments for trend extraction. Our counter trend channels aren't directly used for signal processing; however, these channels provide useful visual cues for extended market moves.
Instructions for Optimization
Step 1: Optimize Mxwll OptAlgo
Begin by optimizing the M-Swift and M-Smooth averages for better signal accuracy.
This step simply finds better performing M-Swift and M-Smooth lookbacks. Again, if the strategy is unprofitable you will be notified and from there decide not to use the strategy.
Step 2: Optimize Mxwll RSI
Refine the Mxwll RSI settings to explore potential adjustments in smoothness and signal output. This step aims to evaluate whether these adjustments could improve the accuracy of the signals generated by Mxwll OptAlgo, while being mindful of any potential impacts.
Step 3: Optimize TP/SL
Consider adjusting the Take Profit and Stop Loss settings to potentially manage risk.
Step 4: Optimize Bars Between Trades
Set the number of bars between trades to regulate the frequency of trade executions. This adjustment may help in reducing the risk of overtrading and support a more disciplined trading strategy.
Step 5: Optimize Trade Flip
Adjust the trade flip parameters to potentially improve the management of transitions between long and short positions. This adjustment is intended to help achieve smoother trade executions, though outcomes may vary.
Step 6: Optimize RSI OB/OB Levels
Consider adjusting the overbought (OB) and oversold (OS) RSI levels to explore potential improvements in signal sensitivity. Careful calibration of these levels may help refine the accuracy of trend reversal signals, although results may depend on market conditions.
Finished!
From this point, consider setting alerts to make the most of the Mxwll Opt Algo's potential accuracy.
The effectiveness of the Opt Algo signal output can be evaluated using the "PF" table, which indicates the profit factor score for the strategy. A profit factor (PF) of less than or equal to 1 suggests that the strategy may not be profitable.
Disclaimer
No strategy works on any timeframe on any asset, so, if the Opt Algo underperforms for the asset/timeframe you're analyzing, the Opt Algo PF table lets you know it hasn't been generating accurate signals, in which case you can decide not to use it!
Optimization Disclaimer
Optimization can be tricky. It's helpful to test numerous strategies in aggregate to see if a strategy has potential. Despite this, optimization can cause overfitting. Overfitting occurs when a strategy is too closely fit to the data it's trading. Overfit backtests are deceptively phenomenal. While the historical performance looks great, the future expectancy of the strategy remains unpredictable - an overfit strategy will profit from periods of random price movement which, being random, are irreproducible and cannot be profited from other than their initial occurrence. When a strategy trades random price movement profitably, any and all profit earned can be reduced to chance. Keep this in mind when using the in-built optimization system. Optimization should be kept to a minimum, a tool to point you in the right direction, whether confirming potential or signifying a useless system.

GKD-BT Optimizer SCSC Backtest [Loxx]The Giga Kaleidoscope GKD-BT Optimizer SCSC Backtest (Solo Confirmation Super Complex) is a Backtest module included in AlgxTrading's "Giga Kaleidoscope Modularized Trading System." (see the section Giga Kaleidoscope (GKD) Modularized Trading System below for an explanation of the GKD trading system)
**the backtest data rendered to the chart above and all screenshots below use $5 commission per trade and 10% equity per trade with $1 million initial capital**
█ GKD-BT Optimizer SCSC Backtest
The GKD-BT Optimizer SCSC Backtest is a comprehensive backtesting module designed to optimize the combination of key GKD indicators within AlgxTrading's "Giga Kaleidoscope Modularized Trading System." This module facilitates precise strategy refinement by allowing traders to configure and optimize the following critical GKD indicators:
GKD-B Baseline
GKD-V Volatility/Volume
GKD-C Confirmation 1
GKD-C Continuation
Each indicator is equipped with an "Optimizer" mode, enabling dynamic feedback and iterative improvements directly into the backtesting environment. This integrated approach ensures that each component contributes effectively to the overall strategy, providing a robust framework for achieving optimized trading outcomes.
The GKD-BT Optimizer supports granular test configurations including a single take profit and stop loss setting, and allows for targeted testing within specified date ranges to simulate forward testing with historical data. This feature is essential for evaluating the resilience and effectiveness of trading strategies under various market conditions.
Furthermore, the module is designed with user-centric features such as:
Customizable Trading Panel: Displays critical backtest results and trade statistics, which can be shown or hidden as per user preference.
Highlighting Thresholds: Users can set thresholds for Total Percent Wins, Percent Profitable, and Profit Factor, which helps in quickly identifying the most relevant metrics for analysis.
The detailed setup ensures that traders can not only adjust their strategies based on historical performance but also fine-tune their approach to meet specific trading objectives.
🔶 To configure this indicator: ***all GKD indicators listed below are all included in the AlgxTrading trading system package***
1. Add GKD-C Confirmation, GKD-B Baseline, GKD-V Volatility/Volume, and GKD-C Continuation to your chart
2. In the GKD-B Baseline indicator, change "Baseline Type" to "Optimizer"
3. In the GKD-V Volatility/Volume indicator, change "Volatility/Volume Type" to "Optimizer"
4. In the GKD-C Confirmation 1 indicator, change "Confirmation Type" to "Optimizer"
5. In the GKD-C Continuation indicator, change "Confirmation Type" to "Optimizer"
An example of steps 2-5. In the screenshot example below, we change the value "Confirmation Type" in the GKD-C Fisher Transform indicator to "Optimizer"
6. In the GKD-BT Optimizer SCSC Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-B Baseline indicator into the field "Import GKD-B Baseline indicator"
7. In the GKD-BT Optimizer SCSC Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-V Volatility/Volume indicator into the field "Import GKD-V Volatility/Volume indicator"
8. In the GKD-BT Optimizer SCSC Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-C Confirmation 1 indicator into the field "Import GKD-C Confirmation 1 indicator"
9. In the GKD-BT Optimizer SCSC Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-C Continuation indicator into the field "Import GKD-C Continuation indicator"
An example of steps 6-9. In the screenshot example below, we import the value "Input into NEW GKD-BT Backtest" from the GKD-C Fisher Transform indicator into the GKD-BT Optimizer SCSC Backtest
10. Decide which of the 5 indicators you wish to optimize in first in the GKD-BT Optimizer SCSC Backtest. Change the value of the import from "Input into NEW GKD-BT Backtest" to "Input into NEW GKD-BT Optimizer Signals"
An example of step 10. In the screenshot example below, we chose to optimize the Confirmation 1 indicator, the GKD-C Fisher Transform. We change the value of the field "Import GKD-C Confirmation 1 indicator" from "Input into NEW GKD-BT Backtest" to "Input into NEW GKD-BT Optimizer Signals"
11. In the GKD-BT Optimizer SCSC Backtest and under the "Optimization Settings", use the dropdown menu "Optimization Indicator" to select the type of indicator you selected from step 12 above: "Baseline", "Volatility/Volume", "Confirmation 1", or "Continuation"
12. In the GKD-BT Optimizer SCSC Backtest and under the "Optimization Settings", import the value "Input into NEW GKD-BT Optimizer Start" from the indicator you selected to optimize in step 12 above into the field "Import Optimization Indicator Start"
13. In the GKD-BT Optimizer SCSC Backtest and under the "Optimization Settings", import the value "Input into NEW GKD-BT Optimizer Skip" from the indicator you selected to optimize in step 12 above into the field "Import Optimization Indicator Skip"
An example of step 11. In the screenshot example below, we select "Confirmation 1" from the "Optimization Indicator" dropdown menu
An example of steps 12 and 13. In the screenshot example below, we import "Import Optimization Indicator Start" and "Import Optimization Indicator Skip" from the GKD-C Fisher Transform indicator into their respective fields
🔶 This backtest includes the following metrics
Net profit: Overall profit or loss achieved.
Total Closed Trades: Total number of closed trades, both winning and losing.
Total Percent Wins: Total wins, whether long or short, for the selected time interval regardless of commissions and other profit-modifying addons.
Percent Profitable: Total wins, whether long or short, that are also profitable, taking commissions into account.
Profit Factor: The ratio of gross profits to gross losses, indicating how much money the strategy made for every unit of money it lost.
Average Profit per Trade: The average gain or loss per trade, calculated by dividing the net profit by the total number of closed trades.
Average Number of Bars in Trade: The average number of bars that elapsed during trades for all closed trades.
🔶 Summary of notable settings not already explained above
🔹 Backtest Properties
These settings define the financial and logistical parameters of the trading simulation, including:
Initial Capital: Specifies the starting balance for the backtest, setting the baseline for measuring profitability and loss.
Order Size: Determines the size of trades, which can be fixed or a percentage of the equity, affecting risk and return.
Order Type: Chooses between fixed contract sizes or a percentage-based order size, allowing for static or dynamic trading volumes.
Commission per Order: Accounts for trading costs, subtracting these from profits to provide a more accurate net performance result.
🔹 Signal Qualifiers
This group of settings establishes criteria related to the strategy's Baseline, and Volatility/Volume indicators in relation to the GKD-C Confirmation 1 indicator, which is crucial for validating trade signals. These include:
Maximum Allowable Post Signal Baseline Cross Bars Back: Sets the maximum number of bars that can elapse after a signal generated by a GKD-C Confirmation 1 indicator triggers. If the GKD-C Confirmation 1 indicator generates a long/short signal that doesn't yet agree with the trend position of the Baseline, then should the Baseline "catch-up" to the long/short trend of the GKD-C Confirmation 1 indicator within the number of bars specified by this setting, then a signal is generated.
Maximum Allowable Post Signal Volatility/Volume Cross Bars Back: Sets the maximum number of bars that can elapse after a signal generated by a GKD-C Confirmation 1 indicator triggers. If the GKD-C Confirmation 1 indicator generates a long/short signal that doesn't yet agree with the position of the Volatility/Volume, then should the Volatility/Volume "catch-up" with the long/short of the GKD-C Confirmation 1 indicator within the number of bars specified by this setting, then a signal is generated.
🔹 Signal Settings
Signal Options: These settings allow users to toggle the visibility of different types of entries based on the strategy criteria, such as standard entries, baseline entries, and continuation entries.
Standard Entry Rules Settings: Detailed criteria for standard entries can be customized here, including conditions on baseline agreement, price within specific zones, and agreement with other confirmation indicators.
1-Candle Rule Standard Entry Rules Settings: Similar to standard entries, but with a focus on conditions that must be met within a one-candle timeframe.
Baseline Entry Rules Settings: Specifies rules for entries based on the baseline, including conditions on confirmation agreement and price zones.
Volatility/Volume Entry Rules Settings: This includes settings for entries based on volatility or volume conditions, with specific rules on confirmation agreement and baseline agreement.
Continuation Entry Rules Settings: This group outlines the conditions for continuation entries, focusing on agreement with baseline and confirmation indicators since the entry signal trigger.
🔹 Volatility Settings
Volatility PnL Settings: Parameters for defining the type of volatility measure to use, its period, and multipliers for profit and stop levels.
Volatility Types Included
Standard Deviation of Logarithmic Returns: Quantifies asset volatility using the standard deviation applied to logarithmic returns, capturing symmetric price movements and financial returns' compound nature.
Exponential Weighted Moving Average (EWMA) for Volatility: Focuses on recent market information by applying exponentially decreasing weights to squared logarithmic returns, offering a dynamic view of market volatility.
Roger-Satchell Volatility Measure: Estimates asset volatility by analyzing the high, low, open, and close prices, providing a nuanced view of intraday volatility and market dynamics.
Close-to-Close Volatility Measure: Calculates volatility based on the closing prices of stocks, offering a streamlined but limited perspective on market behavior.
Parkinson Volatility Measure: Enhances volatility estimation by including high and low prices of the trading day, capturing a more accurate reflection of intraday market movements.
Garman-Klass Volatility Measure: Incorporates open, high, low, and close prices for a comprehensive daily volatility measure, capturing significant price movements and market activity.
Yang-Zhang Volatility Measure: Offers an efficient estimation of stock market volatility by combining overnight and intraday price movements, capturing opening jumps and overall market dynamics.
Garman-Klass-Yang-Zhang Volatility Measure: Merges the benefits of Garman-Klass and Yang-Zhang measures, providing a fuller picture of market volatility including opening market reactions.
Pseudo GARCH(2,2) Volatility Model: Mimics a GARCH(2,2) process using exponential moving averages of squared returns, highlighting volatility shocks and their future impact.
ER-Adaptive Average True Range (ATR): Adjusts the ATR period length based on market efficiency, offering a volatility measure that adapts to changing market conditions.
Adaptive Deviation: Dynamically adjusts its calculation period to offer a nuanced measure of volatility that responds to the market's intrinsic rhythms.
Median Absolute Deviation (MAD): Provides a robust measure of statistical variability, focusing on deviations from the median price, offering resilience against outliers.
Mean Absolute Deviation (MAD): Measures the average magnitude of deviations from the mean price, facilitating a straightforward understanding of volatility.
ATR (Average True Range): Finds the average of true ranges over a specified period, indicating the expected price movement and market volatility.
True Range Double (TRD): Offers a nuanced view of volatility by considering a broader range of price movements, identifying significant market sentiment shifts.
🔹 Other Settings
Backtest Dates: Users can specify the timeframe for the backtest, including start and end dates, as well as the acceptable entry time window.
Volatility Inputs: Additional settings related to volatility calculations, such as static percent, internal filter period for median absolute deviation, and parameters for specific volatility models.
UI Options: Settings to customize the user interface, including table activation, date panel visibility, and aesthetics like color and text size.
Export Options: Allows users to select the type of data to export from the backtest, focusing on metrics like net profit, total closed trades, and average profit per trade.
█ Giga Kaleidoscope (GKD) Modularized Trading System
The GKD Trading System is a comprehensive, algorithmic trading framework from AlgxTrading, designed to optimize trading strategies across various market conditions. It employs a modular approach, incorporating elements such as volatility assessment, trend identification through a baseline, multiple confirmation strategies for signal accuracy, and volume analysis. Key components also include specialized strategies for entry and exit, enabling precise trade execution. The system allows for extensive backtesting, providing traders with the ability to evaluate the effectiveness of their strategies using historical data. Aimed at reducing setup time, the GKD system empowers traders to focus more on strategy refinement and execution, leveraging a wide array of technical indicators for informed decision-making.
🔶 Core components of a GKD Algorithmic Trading System
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system. The GKD algorithm is built on the principles of trend, momentum, and volatility. There are eight core components in the GKD trading algorithm:
🔹 Volatility - In the GKD trading system, volatility is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. There are 17+ different types of volatility available in the GKD system including Average True Range (ATR), True Range Double (TRD), Close-to-Close, Garman-Klass, and more.
🔹 Baseline (GKD-B) - The baseline is essentially a moving average and is used to determine the overall direction of the market. The baseline in the GKD trading system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other GKD indicators.
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards or price is above the baseline, then only long trades are taken, and if the baseline is sloping downwards or price is below the baseline, then only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
🔹 Confirmation 1, Confirmation 2, Continuation (GKD-C) - The GKD trading system incorporates technical confirmation indicators for the generation of its primary long and short signals, essential for its operation.
The GKD trading system distinguishes three specific categories. The first category, Confirmation 1 , encompasses technical indicators designed to identify trends and generate explicit trading signals. The second category, Confirmation 2 , a technical indicator used to identify trends; this type of indicator is primarily used to filter the Confirmation 1 indicator signals; however, this type of confirmation indicator also generates signals*. Lastly, the Continuation category includes technical indicators used in conjunction with Confirmation 1 and Confirmation 2 to generate a special type of trading signal called a "Continuation"
In a full GKD trading system all three categories generate signals. (see the section “GKD Trading System Signals” below)
🔹 Volatility/Volume (GKD-V) - Volatility/Volume indicators are used to measure the amount of buying and selling activity in a market. They are based on the trading Volatility/Volume of the market, and can provide information about the strength of the trend. In the GKD trading system, Volatility/Volume indicators are used to confirm trading signals generated by the various other GKD indicators. In the GKD trading system, Volatility is a proxy for Volume and vice versa.
Volatility/Volume indicators reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by GKD-C confirmation and GKD-B baseline indicators.
🔹 Exit (GKD-E) - The exit indicator in the GKD system is an indicator that is deemed effective at identifying optimal exit points. The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
🔹 Backtest (GKD-BT) - The GKD-BT backtest indicators link all other GKD-C, GKD-B, GKD-E, GKD-V, and GKD-M components together to create a GKD trading system. GKD-BT backtests generate signals (see the section “GKD Trading System Signals” below) from the confluence of various GKD indicators that are imported into the GKD-BT backtest. Backtest types include: GKD-BT solo and full GKD backtest strategies used for a single ticker; GKD-BT optimizers used to optimize a single indicator or the full GKD trading system; GKD-BT Multi-ticker used to backtest a single indicator or the full GKD trading system across up to ten tickers; GKD-BT exotic backtests like CC, Baseline, and Giga Stacks used to test confluence between GKD components to then be injected into a core GKD-BT Multi-ticker backtest or single ticker strategy.
🔹 Metamorphosis (GKD-M) ** - The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, GKD-E, or GKD-V slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
*see the section “GKD Trading System Signals” below
**not a required component of the GKD algorithm
🔶 What does the application of the GKD trading system look like?
Example trading system:
Volatility: Average True Range (ATR) (selectable in all backtests and other related GKD indicators)
GKD-B Baseline: GKD-B Multi-Ticker Baseline using Hull Moving Average
GKD-C Confirmation 1 : GKD-C Advance Trend Pressure
GKD-C Confirmation 2: GKD-C Dorsey Inertia
GKD-C Continuation: GKD-C Stochastic of RSX
GKD-V Volatility/Volume: GKD-V Damiani Volatmeter
GKD-E Exit: GKD-E MFI
GKD-BT Backtest: GKD-BT Multi-Ticker Full GKD Backtest
GKD-M Metamorphosis: GKD-M Baseline Optimizer
**all indicators mentioned above are included in the same AlgxTrading package**
Each module is passed to a GKD-BT backtest module. In the backtest module, all components are combined to formulate trading signals and statistical output. This chaining of indicators requires that each module conform to AlgxTrading's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the various indictor types in the GKD algorithm.
🔶 GKD Trading System Signals
Standard Entry requires a sequence of conditions including a confirmation signal from GKD-C, baseline agreement, price criteria related to the Goldie Locks Zone, and concurrence from a second confirmation and volatility/volume indicators.
1-Candle Standard Entry introduces a two-phase process where initial conditions must be met, followed by a retraction in price and additional confirmations in the subsequent candle, including baseline, confirmations 1 and 2, and volatility/volume criteria.
Baseline Entry focuses on signals generated by the GKD-B Baseline, requiring agreement from confirmation signals, specific price conditions within the Goldie Locks Zone, and a timing condition related to the confirmation 1 signal.
1-Candle Baseline Entry mirrors the baseline entry but adds a requirement for a price retraction and subsequent confirmations in the following candle, maintaining the focus on the baseline's guidance.
Volatility/Volume Entry is predicated on signals from volatility/volume indicators, requiring support from confirmations, price criteria within the Goldie Locks Zone, baseline agreement, and a timing condition for the confirmation 1 signal.
1-Candle Volatility/Volume Entry adapts the volatility/volume entry to include a phase of initial signal and agreement, followed by a retracement phase that seeks further agreement from the system's components in the subsequent candle.
Confirmation 2 Entry is based on the second confirmation signal, requiring the first confirmation's agreement, specific price criteria, agreement from volatility/volume indicators, and baseline, with a timing condition for the confirmation 1 signal.
1-Candle Confirmation 2 Entry adds a retracement requirement to the confirmation 2 entry, necessitating additional agreements from the system's components in the candle following the signal.
PullBack Entry initiates with a baseline signal and agreement from the first confirmation, with a price condition related to volatility. It then looks for price to return within the Goldie Locks Zone and seeks further agreement from the system's components in the subsequent candle.
Continuation Entry allows for the continuation of an active position, based on a previously triggered entry strategy. It requires that the baseline hasn't crossed since the initial trigger, alongside ongoing agreements from confirmations and the baseline.
█ Conclusion
The GKD-BT Optimizer SCSC Backtest is a critical tool within the Giga Kaleidoscope Modularized Trading System, designed for precise strategy refinement and evaluation within the GKD framework. It enables the optimization and testing of various trading indicators and strategies under different market conditions. The module's design facilitates detailed analysis of individual trading components' performance, allowing for the optimization of indicators like Baseline, Volatility/Volume, Confirmation, and Continuation. This optimization process aids traders in identifying the most effective configurations, thereby enhancing trading outcomes and strategy efficiency within the GKD ecosystem.
█ How to Access
You can see the Author's Instructions below to learn how to get access.

GKD-BT Optimizer Full GKD Backtest [Loxx]The Giga Kaleidoscope GKD-BT Optimizer Full GKD Backtest is a Backtest module included in AlgxTrading's "Giga Kaleidoscope Modularized Trading System." (see the section Giga Kaleidoscope (GKD) Modularized Trading System below for an explanation of the GKD trading system)
**the backtest data rendered to the chart above and all screenshots below use $5 commission per trade and 10% equity per trade with $1 million initial capital**
█ GKD-BT Optimizer Full GKD Backtest
The GKD-BT Optimizer Full GKD Backtest is a comprehensive backtesting module designed to optimize the combination of key GKD indicators within AlgxTrading's "Giga Kaleidoscope Modularized Trading System." This module facilitates precise strategy refinement by allowing traders to configure and optimize the following critical GKD indicators:
GKD-B Baseline
GKD-V Volatility/Volume
GKD-C Confirmation 1
GKD-C Confirmation 2
GKD-C Continuation
Each indicator is equipped with an "Optimizer" mode, enabling dynamic feedback and iterative improvements directly into the backtesting environment. This integrated approach ensures that each component contributes effectively to the overall strategy, providing a robust framework for achieving optimized trading outcomes.
The GKD-BT Optimizer supports granular test configurations including a single take profit and stop loss setting, and allows for targeted testing within specified date ranges to simulate forward testing with historical data. This feature is essential for evaluating the resilience and effectiveness of trading strategies under various market conditions.
Furthermore, the module is designed with user-centric features such as:
Customizable Trading Panel: Displays critical backtest results and trade statistics, which can be shown or hidden as per user preference.
Highlighting Thresholds: Users can set thresholds for Total Percent Wins, Percent Profitable, and Profit Factor, which helps in quickly identifying the most relevant metrics for analysis.
The detailed setup ensures that traders can not only adjust their strategies based on historical performance but also fine-tune their approach to meet specific trading objectives.
🔶 To configure this indicator: ***all GKD indicators listed below are all included in the AlgxTrading trading system package***
1. Add GKD-C Confirmation, GKD-B Baseline, GKD-V Volatility/Volume, GKD-C Confirmation 2, and GKD-C Continuation to your chart
2. In the GKD-B Baseline indicator, change "Baseline Type" to "Optimizer"
3. In the GKD-V Volatility/Volume indicator, change "Volatility/Volume Type" to "Optimizer"
4. In the GKD-C Confirmation 1 indicator, change "Confirmation Type" to "Optimizer"
5. In the GKD-C Confirmation 2 indicator, change "Confirmation Type" to "Optimizer"
6. In the GKD-C Continuation indicator, change "Confirmation Type" to "Optimizer"
An example of steps 2-6. In the screenshot example below, we change the value "Confirmation Type" in the GKD-C Fisher Transform indicator to "Optimizer"
7. In the GKD-BT Optimizer Full GKD Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-B Baseline indicator into the field "Import GKD-B Baseline indicator"
8. In the GKD-BT Optimizer Full GKD Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-V Volatility/Volume indicator into the field "Import GKD-V Volatility/Volume indicator"
9. In the GKD-BT Optimizer Full GKD Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-C Confirmation 1 indicator into the field "Import GKD-C Confirmation 1 indicator"
10. In the GKD-BT Optimizer Full GKD Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-C Confirmation 2 indicator into the field "Import GKD-C Confirmation 2 indicator"
11. In the GKD-BT Optimizer Full GKD Backtest, import the value "Input into NEW GKD-BT Backtest" from the GKD-C Continuation indicator into the field "Import GKD-C Continuation indicator"
An example of steps 7-11. In the screenshot example below, we import the value "Input into NEW GKD-BT Backtest" from the GKD-C Coppock Curve indicator into the GKD-BT Optimizer Full GKD Backtest
12. Decide which of the 5 indicators you wish to optimize in first in the GKD-BT Optimizer Full GKD Backtest. Change the value of the import from "Input into NEW GKD-BT Backtest" to "Input into NEW GKD-BT Optimizer Signals"
An example of step 12. In the screenshot example below, we chose to optimize the Confirmation 1 indicator, the GKD-C Fisher Transform. We change the value of the field "Import GKD-C Confirmation 1 indicator" from "Input into NEW GKD-BT Backtest" to "Input into NEW GKD-BT Optimizer Signals"
13. In the GKD-BT Optimizer Full GKD Backtest and under the "Optimization Settings", use the dropdown menu "Optimization Indicator" to select the type of indicator you selected from step 12 above: "Baseline", "Volatility/Volume", "Confirmation 1", "Confirmation 2", or "Continuation"
14. In the GKD-BT Optimizer Full GKD Backtest and under the "Optimization Settings", import the value "Input into NEW GKD-BT Optimizer Start" from the indicator you selected to optimize in step 12 above into the field "Import Optimization Indicator Start"
15. In the GKD-BT Optimizer Full GKD Backtest and under the "Optimization Settings", import the value "Input into NEW GKD-BT Optimizer Skip" from the indicator you selected to optimize in step 12 above into the field "Import Optimization Indicator Skip"
An example of step 13. In the screenshot example below, we select "Confirmation 1" from the "Optimization Indicator" dropdown menu
An example of steps 14 and 15. In the screenshot example below, we import "Import Optimization Indicator Start" and "Import Optimization Indicator Skip" from the GKD-C Fisher Transform indicator into their respective fields
🔶 This backtest includes the following metrics
Net profit: Overall profit or loss achieved.
Total Closed Trades: Total number of closed trades, both winning and losing.
Total Percent Wins: Total wins, whether long or short, for the selected time interval regardless of commissions and other profit-modifying addons.
Percent Profitable: Total wins, whether long or short, that are also profitable, taking commissions into account.
Profit Factor: The ratio of gross profits to gross losses, indicating how much money the strategy made for every unit of money it lost.
Average Profit per Trade: The average gain or loss per trade, calculated by dividing the net profit by the total number of closed trades.
Average Number of Bars in Trade: The average number of bars that elapsed during trades for all closed trades.
🔶 Summary of notable settings not already explained above
🔹 Backtest Properties
These settings define the financial and logistical parameters of the trading simulation, including:
Initial Capital: Specifies the starting balance for the backtest, setting the baseline for measuring profitability and loss.
Order Size: Determines the size of trades, which can be fixed or a percentage of the equity, affecting risk and return.
Order Type: Chooses between fixed contract sizes or a percentage-based order size, allowing for static or dynamic trading volumes.
Commission per Order: Accounts for trading costs, subtracting these from profits to provide a more accurate net performance result.
🔹 Signal Qualifiers
This group of settings establishes criteria related to the strategy's Baseline, Volatility/Volume, and Confirmation 2 indicators in relation to the GKD-C Confirmation 1 indicator, which is crucial for validating trade signals. These include:
Maximum Allowable Post Signal Baseline Cross Bars Back: Sets the maximum number of bars that can elapse after a signal generated by a GKD-C Confirmation 1 indicator triggers. If the GKD-C Confirmation 1 indicator generates a long/short signal that doesn't yet agree with the trend position of the Baseline, then should the Baseline "catch-up" to the long/short trend of the GKD-C Confirmation 1 indicator within the number of bars specified by this setting, then a signal is generated.
Maximum Allowable Post Signal Volatility/Volume Cross Bars Back: Sets the maximum number of bars that can elapse after a signal generated by a GKD-C Confirmation 1 indicator triggers. If the GKD-C Confirmation 1 indicator generates a long/short signal that doesn't yet agree with the position of the Volatility/Volume, then should the Volatility/Volume "catch-up" with the long/short of the GKD-C Confirmation 1 indicator within the number of bars specified by this setting, then a signal is generated.
Maximum Allowable Post Signal Confirmation 2 Cross Bars Back: Sets the maximum number of bars that can elapse after a signal generated by a GKD-C Confirmation 1 indicator triggers. If the GKD-C Confirmation 1 indicator generates a long/short signal that doesn't yet agree with the trend position of the Confirmation 2, then should the Confirmation 2 "catch-up" to the long/short trend of the GKD-C Confirmation 1 indicator within the number of bars specified by this setting, then a signal is generated.
🔹 Signal Settings
Signal Options: These settings allow users to toggle the visibility of different types of entries based on the strategy criteria, such as standard entries, baseline entries, and continuation entries.
Standard Entry Rules Settings: Detailed criteria for standard entries can be customized here, including conditions on baseline agreement, price within specific zones, and agreement with other confirmation indicators.
1-Candle Rule Standard Entry Rules Settings: Similar to standard entries, but with a focus on conditions that must be met within a one-candle timeframe.
Baseline Entry Rules Settings: Specifies rules for entries based on the baseline, including conditions on confirmation agreement and price zones.
Volatility/Volume Entry Rules Settings: This includes settings for entries based on volatility or volume conditions, with specific rules on confirmation agreement and baseline agreement.
Confirmation 2 Entry Rules Settings: Settings here define the rules for entries based on a second confirmation indicator, detailing the required agreements and conditions.
Continuation Entry Rules Settings: This group outlines the conditions for continuation entries, focusing on agreement with baseline and confirmation indicators since the entry signal trigger.
🔹 Volatility Settings
Volatility PnL Settings: Parameters for defining the type of volatility measure to use, its period, and multipliers for profit and stop levels.
Volatility Types Included
Standard Deviation of Logarithmic Returns: Quantifies asset volatility using the standard deviation applied to logarithmic returns, capturing symmetric price movements and financial returns' compound nature.
Exponential Weighted Moving Average (EWMA) for Volatility: Focuses on recent market information by applying exponentially decreasing weights to squared logarithmic returns, offering a dynamic view of market volatility.
Roger-Satchell Volatility Measure: Estimates asset volatility by analyzing the high, low, open, and close prices, providing a nuanced view of intraday volatility and market dynamics.
Close-to-Close Volatility Measure: Calculates volatility based on the closing prices of stocks, offering a streamlined but limited perspective on market behavior.
Parkinson Volatility Measure: Enhances volatility estimation by including high and low prices of the trading day, capturing a more accurate reflection of intraday market movements.
Garman-Klass Volatility Measure: Incorporates open, high, low, and close prices for a comprehensive daily volatility measure, capturing significant price movements and market activity.
Yang-Zhang Volatility Measure: Offers an efficient estimation of stock market volatility by combining overnight and intraday price movements, capturing opening jumps and overall market dynamics.
Garman-Klass-Yang-Zhang Volatility Measure: Merges the benefits of Garman-Klass and Yang-Zhang measures, providing a fuller picture of market volatility including opening market reactions.
Pseudo GARCH(2,2) Volatility Model: Mimics a GARCH(2,2) process using exponential moving averages of squared returns, highlighting volatility shocks and their future impact.
ER-Adaptive Average True Range (ATR): Adjusts the ATR period length based on market efficiency, offering a volatility measure that adapts to changing market conditions.
Adaptive Deviation: Dynamically adjusts its calculation period to offer a nuanced measure of volatility that responds to the market's intrinsic rhythms.
Median Absolute Deviation (MAD): Provides a robust measure of statistical variability, focusing on deviations from the median price, offering resilience against outliers.
Mean Absolute Deviation (MAD): Measures the average magnitude of deviations from the mean price, facilitating a straightforward understanding of volatility.
ATR (Average True Range): Finds the average of true ranges over a specified period, indicating the expected price movement and market volatility.
True Range Double (TRD): Offers a nuanced view of volatility by considering a broader range of price movements, identifying significant market sentiment shifts.
🔹 Other Settings
Backtest Dates: Users can specify the timeframe for the backtest, including start and end dates, as well as the acceptable entry time window.
Volatility Inputs: Additional settings related to volatility calculations, such as static percent, internal filter period for median absolute deviation, and parameters for specific volatility models.
UI Options: Settings to customize the user interface, including table activation, date panel visibility, and aesthetics like color and text size.
Export Options: Allows users to select the type of data to export from the backtest, focusing on metrics like net profit, total closed trades, and average profit per trade.
█ Giga Kaleidoscope (GKD) Modularized Trading System
The GKD Trading System is a comprehensive, algorithmic trading framework from AlgxTrading, designed to optimize trading strategies across various market conditions. It employs a modular approach, incorporating elements such as volatility assessment, trend identification through a baseline, multiple confirmation strategies for signal accuracy, and volume analysis. Key components also include specialized strategies for entry and exit, enabling precise trade execution. The system allows for extensive backtesting, providing traders with the ability to evaluate the effectiveness of their strategies using historical data. Aimed at reducing setup time, the GKD system empowers traders to focus more on strategy refinement and execution, leveraging a wide array of technical indicators for informed decision-making.
🔶 Core components of a GKD Algorithmic Trading System
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system. The GKD algorithm is built on the principles of trend, momentum, and volatility. There are eight core components in the GKD trading algorithm:
🔹 Volatility - In the GKD trading system, volatility is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. There are 17+ different types of volatility available in the GKD system including Average True Range (ATR), True Range Double (TRD), Close-to-Close, Garman-Klass, and more.
🔹 Baseline (GKD-B) - The baseline is essentially a moving average and is used to determine the overall direction of the market. The baseline in the GKD trading system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other GKD indicators.
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards or price is above the baseline, then only long trades are taken, and if the baseline is sloping downwards or price is below the baseline, then only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
🔹 Confirmation 1, Confirmation 2, Continuation (GKD-C) - The GKD trading system incorporates technical confirmation indicators for the generation of its primary long and short signals, essential for its operation.
The GKD trading system distinguishes three specific categories. The first category, Confirmation 1 , encompasses technical indicators designed to identify trends and generate explicit trading signals. The second category, Confirmation 2 , a technical indicator used to identify trends; this type of indicator is primarily used to filter the Confirmation 1 indicator signals; however, this type of confirmation indicator also generates signals*. Lastly, the Continuation category includes technical indicators used in conjunction with Confirmation 1 and Confirmation 2 to generate a special type of trading signal called a "Continuation"
In a full GKD trading system all three categories generate signals. (see the section “GKD Trading System Signals” below)
🔹 Volatility/Volume (GKD-V) - Volatility/Volume indicators are used to measure the amount of buying and selling activity in a market. They are based on the trading Volatility/Volume of the market, and can provide information about the strength of the trend. In the GKD trading system, Volatility/Volume indicators are used to confirm trading signals generated by the various other GKD indicators. In the GKD trading system, Volatility is a proxy for Volume and vice versa.
Volatility/Volume indicators reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by GKD-C confirmation and GKD-B baseline indicators.
🔹 Exit (GKD-E) - The exit indicator in the GKD system is an indicator that is deemed effective at identifying optimal exit points. The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
🔹 Backtest (GKD-BT) - The GKD-BT backtest indicators link all other GKD-C, GKD-B, GKD-E, GKD-V, and GKD-M components together to create a GKD trading system. GKD-BT backtests generate signals (see the section “GKD Trading System Signals” below) from the confluence of various GKD indicators that are imported into the GKD-BT backtest. Backtest types include: GKD-BT solo and full GKD backtest strategies used for a single ticker; GKD-BT optimizers used to optimize a single indicator or the full GKD trading system; GKD-BT Multi-ticker used to backtest a single indicator or the full GKD trading system across up to ten tickers; GKD-BT exotic backtests like CC, Baseline, and Giga Stacks used to test confluence between GKD components to then be injected into a core GKD-BT Multi-ticker backtest or single ticker strategy.
🔹 Metamorphosis (GKD-M) ** - The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, GKD-E, or GKD-V slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
*see the section “GKD Trading System Signals” below
**not a required component of the GKD algorithm
🔶 What does the application of the GKD trading system look like?
Example trading system:
Volatility: Average True Range (ATR) (selectable in all backtests and other related GKD indicators)
GKD-B Baseline: GKD-B Multi-Ticker Baseline using Hull Moving Average
GKD-C Confirmation 1 : GKD-C Advance Trend Pressure
GKD-C Confirmation 2: GKD-C Dorsey Inertia
GKD-C Continuation: GKD-C Stochastic of RSX
GKD-V Volatility/Volume: GKD-V Damiani Volatmeter
GKD-E Exit: GKD-E MFI
GKD-BT Backtest: GKD-BT Multi-Ticker Full GKD Backtest
GKD-M Metamorphosis: GKD-M Baseline Optimizer
**all indicators mentioned above are included in the same AlgxTrading package**
Each module is passed to a GKD-BT backtest module. In the backtest module, all components are combined to formulate trading signals and statistical output. This chaining of indicators requires that each module conform to AlgxTrading's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the various indictor types in the GKD algorithm.
🔶 GKD Trading System Signals
Standard Entry requires a sequence of conditions including a confirmation signal from GKD-C, baseline agreement, price criteria related to the Goldie Locks Zone, and concurrence from a second confirmation and volatility/volume indicators.
1-Candle Standard Entry introduces a two-phase process where initial conditions must be met, followed by a retraction in price and additional confirmations in the subsequent candle, including baseline, confirmations 1 and 2, and volatility/volume criteria.
Baseline Entry focuses on signals generated by the GKD-B Baseline, requiring agreement from confirmation signals, specific price conditions within the Goldie Locks Zone, and a timing condition related to the confirmation 1 signal.
1-Candle Baseline Entry mirrors the baseline entry but adds a requirement for a price retraction and subsequent confirmations in the following candle, maintaining the focus on the baseline's guidance.
Volatility/Volume Entry is predicated on signals from volatility/volume indicators, requiring support from confirmations, price criteria within the Goldie Locks Zone, baseline agreement, and a timing condition for the confirmation 1 signal.
1-Candle Volatility/Volume Entry adapts the volatility/volume entry to include a phase of initial signal and agreement, followed by a retracement phase that seeks further agreement from the system's components in the subsequent candle.
Confirmation 2 Entry is based on the second confirmation signal, requiring the first confirmation's agreement, specific price criteria, agreement from volatility/volume indicators, and baseline, with a timing condition for the confirmation 1 signal.
1-Candle Confirmation 2 Entry adds a retracement requirement to the confirmation 2 entry, necessitating additional agreements from the system's components in the candle following the signal.
PullBack Entry initiates with a baseline signal and agreement from the first confirmation, with a price condition related to volatility. It then looks for price to return within the Goldie Locks Zone and seeks further agreement from the system's components in the subsequent candle.
Continuation Entry allows for the continuation of an active position, based on a previously triggered entry strategy. It requires that the baseline hasn't crossed since the initial trigger, alongside ongoing agreements from confirmations and the baseline.
█ Conclusion
The GKD-BT Optimizer Full GKD Backtest is a critical tool within the Giga Kaleidoscope Modularized Trading System, designed for precise strategy refinement and evaluation within the GKD framework. It enables the optimization and testing of various trading indicators and strategies under different market conditions. The module's design facilitates detailed analysis of individual trading components' performance, allowing for the optimization of indicators like Baseline, Volatility/Volume, Confirmation, and Continuation. This optimization process aids traders in identifying the most effective configurations, thereby enhancing trading outcomes and strategy efficiency within the GKD ecosystem.
█ How to Access
You can see the Author's Instructions below to learn how to get access.

GKD-C Derivative Oscillator [Loxx]The Giga Kaleidoscope GKD-C Derivative Oscillator is a Confirmation module included in AlgxTrading's "Giga Kaleidoscope Modularized Trading System."
█ GKD-C Derivative Oscillator, a brief overview
The Derivative Oscillator is a technical analysis tool used in trading that merges the concepts of the Relative Strength Index (RSI) and the double smoothed moving average. Essentially, it operates by taking the difference between a short-term moving average of the asset's price and a longer-term moving average, which is then double smoothed with exponential moving averages (EMAs). This process refines the RSI, aiming to provide clearer signals regarding the momentum and potential trend reversals of a security's price. The GKD-C Derivative Oscillator produces two types of signals: Zero-line or Signal crosses. (read the sections below to learn how traders can test these different signal types using AlgxTrading's GKD trading system)
GKD-C Derivative Oscillator in Zero-line crosses mode
GKD-C Derivative Oscillator in Signal crosses mode
To explain the features included in the GKD-C Derivative Oscillator , let's first dive into the details of the Giga Kaleidoscope (GKD) Modularized Trading System.
█ Giga Kaleidoscope (GKD) Modularized Trading System
The GKD Trading System is a comprehensive, algorithmic trading framework from AlgxTrading, designed to optimize trading strategies across various market conditions. It employs a modular approach, incorporating elements such as volatility assessment, trend identification through a baseline, multiple confirmation strategies for signal accuracy, and volume analysis. Key components also include specialized strategies for entry and exit, enabling precise trade execution. The system allows for extensive backtesting, providing traders with the ability to evaluate the effectiveness of their strategies using historical data. Aimed at reducing setup time, the GKD system empowers traders to focus more on strategy refinement and execution, leveraging a wide array of technical indicators for informed decision-making.
🔶 Core components of a GKD Algorithmic Trading System
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system. The GKD algorithm is built on the principles of trend, momentum, and volatility. There are eight core components in the GKD trading algorithm:
🔹 Volatility - In the GKD trading system, volatility is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. There are 17+ different types of volatility available in the GKD system including Average True Range (ATR), True Range Double (TRD), Close-to-Close, Garman-Klass, and more.
🔹 Baseline (GKD-B) - The baseline is essentially a moving average and is used to determine the overall direction of the market. The baseline in the GKD trading system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other GKD indicators.
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards or price is above the baseline, then only long trades are taken, and if the baseline is sloping downwards or price is below the baseline, then only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
🔹 Confirmation 1, Confirmation 2, Continuation (GKD-C) - The GKD trading system incorporates technical confirmation indicators for the generation of its primary long and short signals, essential for its operation.
The GKD trading system distinguishes three specific categories. The first category, Confirmation 1 , encompasses technical indicators designed to identify trends and generate explicit trading signals. The second category, Confirmation 2 , a technical indicator used to identify trends; this type of indicator is primarily used to filter the Confirmation 1 indicator signals; however, this type of confirmation indicator also generates signals*. Lastly, the Continuation category includes technical indicators used in conjunction with Confirmation 1 and Confirmation 2 to generate a special type of trading signal called a "Continuation"
In a full GKD trading system all three categories generate signals. (see the section “GKD Trading System Signals” below)
🔹 Volatility/Volume (GKD-V) - Volatility/Volume indicators are used to measure the amount of buying and selling activity in a market. They are based on the trading Volatility/Volume of the market, and can provide information about the strength of the trend. In the GKD trading system, Volatility/Volume indicators are used to confirm trading signals generated by the various other GKD indicators. In the GKD trading system, Volatility is a proxy for Volume and vice versa.
Volatility/Volume indicators reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by GKD-C confirmation and GKD-B baseline indicators.
🔹 Exit (GKD-E) - The exit indicator in the GKD system is an indicator that is deemed effective at identifying optimal exit points. The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
🔹 Backtest (GKD-BT) - The GKD-BT backtest indicators link all other GKD-C, GKD-B, GKD-E, GKD-V, and GKD-M components together to create a GKD trading system. GKD-BT backtests generate signals (see the section “GKD Trading System Signals” below) from the confluence of various GKD indicators that are imported into the GKD-BT backtest. Backtest types include: GKD-BT solo and full GKD backtest strategies used for a single ticker; GKD-BT optimizers used to optimize a single indicator or the full GKD trading system; GKD-BT Multi-ticker used to backtest a single indicator or the full GKD trading system across up to ten tickers; GKD-BT exotic backtests like CC, Baseline, and Giga Stacks used to test confluence between GKD components to then be injected into a core GKD-BT Multi-ticker backtest or single ticker strategy.
🔹 Metamorphosis (GKD-M) ** - The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, GKD-E, or GKD-V slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
*(see the section “GKD Trading System Signals” below)
**(not a required component of the GKD algorithm)
🔶 What does the application of the GKD trading system look like?
Example trading system:
Volatility: Average True Range (ATR) (selectable in all backtests and other related GKD indicators)
GKD-B Baseline: GKD-B Multi-Ticker Baseline using Hull Moving Average
GKD-C Confirmation 1 : GKD-C Advance Trend Pressure
GKD-C Confirmation 2: GKD-C Dorsey Inertia
GKD-C Continuation: GKD-C Stochastic of RSX
GKD-V Volatility/Volume: GKD-V Damiani Volatmeter
GKD-E Exit: GKD-E MFI
GKD-BT Backtest: GKD-BT Multi-Ticker Full GKD Backtest
GKD-M Metamorphosis: GKD-M Baseline Optimizer
**all indicators mentioned above are included in the same AlgxTrading package**
Each module is passed to a GKD-BT backtest module. In the backtest module, all components are combined to formulate trading signals and statistical output. This chaining of indicators requires that each module conform to AlgxTrading's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the various indictor types in the GKD algorithm.
🔶 GKD Trading System Signals
🔹 Standard Entry requires a sequence of conditions including a confirmation signal from GKD-C, baseline agreement, price criteria related to the Goldie Locks Zone, and concurrence from a second confirmation and volatility/volume indicators.
🔹 1-Candle Standard Entry introduces a two-phase process where initial conditions must be met, followed by a retraction in price and additional confirmations in the subsequent candle, including baseline, confirmations 1 and 2, and volatility/volume criteria.
🔹 Baseline Entry focuses on signals generated by the GKD-B Baseline, requiring agreement from confirmation signals, specific price conditions within the Goldie Locks Zone, and a timing condition related to the confirmation 1 signal.
🔹 1-Candle Baseline Entry mirrors the baseline entry but adds a requirement for a price retraction and subsequent confirmations in the following candle, maintaining the focus on the baseline's guidance.
🔹 Volatility/Volume Entry is predicated on signals from volatility/volume indicators, requiring support from confirmations, price criteria within the Goldie Locks Zone, baseline agreement, and a timing condition for the confirmation 1 signal.
🔹 1-Candle Volatility/Volume Entry adapts the volatility/volume entry to include a phase of initial signal and agreement, followed by a retracement phase that seeks further agreement from the system's components in the subsequent candle.
🔹 Confirmation 2 Entry is based on the second confirmation signal, requiring the first confirmation's agreement, specific price criteria, agreement from volatility/volume indicators, and baseline, with a timing condition for the confirmation 1 signal.
🔹 1-Candle Confirmation 2 Entry adds a retracement requirement to the confirmation 2 entry, necessitating additional agreements from the system's components in the candle following the signal.
🔹 PullBack Entry initiates with a baseline signal and agreement from the first confirmation, with a price condition related to volatility. It then looks for price to return within the Goldie Locks Zone and seeks further agreement from the system's components in the subsequent candle.
🔹 Continuation Entry allows for the continuation of an active position, based on a previously triggered entry strategy. It requires that the baseline hasn't crossed since the initial trigger, alongside ongoing agreements from confirmations and the baseline.
█ GKD-C Derivative Oscillator, a deep dive
Now that you have a basic understanding of the GKD trading system. let's dive deeper into the features included in the GKD-C Derivative Oscillator
🔶 GKD-C Derivative Oscillator Modes aka "Confirmation Type"
The GKD-C Derivative Oscillator has 4 modes: Confirmation for confirmation 1 and 2; Continuation; Multi-ticker for multi-ticker confirmation 1 and 2; and Optimizer.
🔹 Confirmation: When in this mode, the GKD-C Derivative Oscillator generates confirmation 1 and 2 signals. These values can then be exported to a GKD-BT backtest strategy.
Signal Key: L = Long, S = Short
GKD-C Derivative Oscillator in Confirmation mode
Confirmation Exports
GKD-C Derivative Oscillator in attached to a GKD-BT backtest strategy
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
🔹 Continuation: When in this mode, the GKD-C Derivative Oscillator generates continuation signals.
Signal Key: L = Long, S = Short, CL = Continuation Long, CS = Continuation Short
GKD-C Derivative Oscillator in Continuation mode
Continuation Exports
🔹 Multi-ticker: When in this mode, the GKD-C Derivative Oscillator generates multi-ticker confirmation 1 and 2. This mode allows users to generate confirmation 1 and 2, and continuation signals for up to 10 different tickers. These values can then be exported to a GKD-BT Multi-ticker backtest.
Signal Key: L = Long, S = Short
GKD-C Derivative Oscillator in Multi-ticker mode
Multi-ticker Exports
GKD-C Derivative Oscillator attached to the GKD-BT Multi-ticker SCS Backtest
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
🔹 Optimizer: When in this mode, the GKD-C Derivative Oscillator generates optimization signals. These signals allow the user to backtest a range of input values. These values are exported to a GKD-BT optimizer backtest.
Signal Key: L = Long, S = Short
GKD-C Derivative Oscillator in Optimizer mode
Optimizer Inputs and Exports
GKD-C Derivative Oscillator attacked to the GKD-BT Optimizer SCS Backtest
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
█ Conclusion
The GKD-C Derivative Oscillator serves as a multi-modal component of the GKD trading system allowing traders to optimize and backtest acorss a range of input parameters and tickers. These features decrease total build time required to create a custom GKD algorithmic trading system by allowing users to spend more time trading and less time guessing.
█ How to Access
You can see the Author's Instructions below to learn how to get access.

GKD-BT Multi-Ticker Baseline Backtest [Loxx]The Giga Kaleidoscope GKD-BT Multi-Ticker Baseline Backtest is a backtesting module included in Loxx's "Giga Kaleidoscope Modularized Trading System."
█ Giga Kaleidoscope GKD-BT Multi-Ticker Baseline Backtest
The Multi-Ticker SCSC Backtest is a Solo Confirmation Super Complex backtest that allows traders to test GKD-B Multi-Ticker Baseline series baselines indicators filtered. The purpose of this backtest is to enable traders to quickly evaluate the viability of a Baseline across hundreds of tickers within 30-60 minutes.
The backtest module supports testing with 1 take profit and 1 stop loss. It also offers the option to limit testing to a specific date range, allowing simulated forward testing using historical data. This backtest module only includes standard long and short signals. Additionally, users can choose to display or hide a trading panel that provides relevant information about the backtest, statistics, and the current trade. Traders can also select a highlighting threshold for Total Percent Wins and Percent Profitable, and Profit Factor.
To use this indicator:
1. Import 1-10 tickers into the GKD-B Multi-Ticker Baseline indicator
2. Import the value "Input into NEW GKD-BT Multi-ticker Backtest" from the GKD-B Multi-Ticker Baseline indicator (Volatility-Adaptive, Stepped, etc.) into the GKD-BT Multi-Ticker Baseline Backtest.
3. Import the same 1-10 tickers from number step 1 above into the GKD-BT Multi-Ticker Baseline Backtest indicator into the text area field "Input Tickers separated by commas".
3. When importing tickers, ensure that you import the same type of tickers for all 1-10 tickers. For example, test only FX or Cryptocurrency or Stocks. Do not combine different tradable asset types.
4. Make sure that your chart is set to a ticker that corresponds to the tradable asset type. For cryptocurrency testing, set the chart to BTCUSDT. For Forex testing, set the chart to EURUSD.
This backtest includes the following metrics:
1. Net profit: Overall profit or loss achieved.
2. Total Closed Trades: Total number of closed trades, both winning and losing.
3. Total Percent Wins: Total wins, whether long or short, for the selected time interval regardless of commissions and other profit-modifying add-ons.
4. Percent Profitable: Total wins, whether long or short, that are also profitable, taking commissions into account.
5. Profit Factor: The ratio of gross profits to gross losses, indicating how much money the strategy made for every unit of money it lost.
6. Average Profit per Trade: The average gain or loss per trade, calculated by dividing the net profit by the total number of closed trades.
7. Average Number of Bars in Trade: The average number of bars that elapsed during trades for all closed trades.
Summary of notable settings:
Input Tickers separated by commas: Allows the user to input tickers separated by commas, specifying the symbols or tickers of financial instruments used in the backtest. The tickers should follow the format "EXCHANGE:TICKER" (e.g., "NASDAQ:AAPL, NYSE:MSFT").
Import GKD-B Baseline: Imports the "GKD-B Multi-Ticker Baseline" indicator.
Initial Capital: Represents the starting account balance for the backtest, denominated in the base currency of the trading account.
Order Size: Determines the quantity of contracts traded in each trade.
Order Type: Specifies the type of order used in the backtest, either "Contracts" or "% Equity."
Commission: Represents the commission per order or transaction cost incurred in each trade.
**the backtest data rendered to the chart above uses $5 commission per trade and 10% equity per trade with $1 million initial capital. Each backtest result for each ticker assumes these same inputs. The results are NOT cumulative, they are separate and isolated per ticker and trading side, long or short**
█ Volatility Types included
The GKD system utilizes volatility-based take profits and stop losses. Each take profit and stop loss is calculated as a multiple of volatility. You can change the values of the multipliers in the settings as well.
This module includes 17 types of volatility:
Close-to-Close
Parkinson
Garman-Klass
Rogers-Satchell
Yang-Zhang
Garman-Klass-Yang-Zhang
Exponential Weighted Moving Average
Standard Deviation of Log Returns
Pseudo GARCH(2,2)
Average True Range
True Range Double
Standard Deviation
Adaptive Deviation
Median Absolute Deviation
Efficiency-Ratio Adaptive ATR
Mean Absolute Deviation
Static Percent
Various volatility estimators and indicators that investors and traders can use to measure the dispersion or volatility of a financial instrument's price. Each estimator has its strengths and weaknesses, and the choice of estimator should depend on the specific needs and circumstances of the user.
Close-to-Close
Close-to-Close volatility is a classic and widely used volatility measure, sometimes referred to as historical volatility.
Volatility is an indicator of the speed of a stock price change. A stock with high volatility is one where the price changes rapidly and with a larger amplitude. The more volatile a stock is, the riskier it is.
Close-to-close historical volatility is calculated using only a stock's closing prices. It is the simplest volatility estimator. However, in many cases, it is not precise enough. Stock prices could jump significantly during a trading session and return to the opening value at the end. That means that a considerable amount of price information is not taken into account by close-to-close volatility.
Despite its drawbacks, Close-to-Close volatility is still useful in cases where the instrument doesn't have intraday prices. For example, mutual funds calculate their net asset values daily or weekly, and thus their prices are not suitable for more sophisticated volatility estimators.
Parkinson
Parkinson volatility is a volatility measure that uses the stock’s high and low price of the day.
The main difference between regular volatility and Parkinson volatility is that the latter uses high and low prices for a day, rather than only the closing price. This is useful as close-to-close prices could show little difference while large price movements could have occurred during the day. Thus, Parkinson's volatility is considered more precise and requires less data for calculation than close-to-close volatility.
One drawback of this estimator is that it doesn't take into account price movements after the market closes. Hence, it systematically undervalues volatility. This drawback is addressed in the Garman-Klass volatility estimator.
Garman-Klass
Garman-Klass is a volatility estimator that incorporates open, low, high, and close prices of a security.
Garman-Klass volatility extends Parkinson's volatility by taking into account the opening and closing prices. As markets are most active during the opening and closing of a trading session, it makes volatility estimation more accurate.
Garman and Klass also assumed that the process of price change follows a continuous diffusion process (Geometric Brownian motion). However, this assumption has several drawbacks. The method is not robust for opening jumps in price and trend movements.
Despite its drawbacks, the Garman-Klass estimator is still more effective than the basic formula since it takes into account not only the price at the beginning and end of the time interval but also intraday price extremes.
Researchers Rogers and Satchell have proposed a more efficient method for assessing historical volatility that takes into account price trends. See Rogers-Satchell Volatility for more detail.
Rogers-Satchell
Rogers-Satchell is an estimator for measuring the volatility of securities with an average return not equal to zero.
Unlike Parkinson and Garman-Klass estimators, Rogers-Satchell incorporates a drift term (mean return not equal to zero). As a result, it provides better volatility estimation when the underlying is trending.
The main disadvantage of this method is that it does not take into account price movements between trading sessions. This leads to an underestimation of volatility since price jumps periodically occur in the market precisely at the moments between sessions.
A more comprehensive estimator that also considers the gaps between sessions was developed based on the Rogers-Satchel formula in the 2000s by Yang-Zhang. See Yang Zhang Volatility for more detail.
Yang-Zhang
Yang Zhang is a historical volatility estimator that handles both opening jumps and the drift and has a minimum estimation error.
Yang-Zhang volatility can be thought of as a combination of the overnight (close-to-open volatility) and a weighted average of the Rogers-Satchell volatility and the day’s open-to-close volatility. It is considered to be 14 times more efficient than the close-to-close estimator.
Garman-Klass-Yang-Zhang
Garman-Klass-Yang-Zhang (GKYZ) volatility estimator incorporates the returns of open, high, low, and closing prices in its calculation.
GKYZ volatility estimator takes into account overnight jumps but not the trend, i.e., it assumes that the underlying asset follows a Geometric Brownian Motion (GBM) process with zero drift. Therefore, the GKYZ volatility estimator tends to overestimate the volatility when the drift is different from zero. However, for a GBM process, this estimator is eight times more efficient than the close-to-close volatility estimator.
Exponential Weighted Moving Average
The Exponentially Weighted Moving Average (EWMA) is a quantitative or statistical measure used to model or describe a time series. The EWMA is widely used in finance, with the main applications being technical analysis and volatility modeling.
The moving average is designed such that older observations are given lower weights. The weights decrease exponentially as the data point gets older – hence the name exponentially weighted.
The only decision a user of the EWMA must make is the parameter lambda. The parameter decides how important the current observation is in the calculation of the EWMA. The higher the value of lambda, the more closely the EWMA tracks the original time series.
Standard Deviation of Log Returns
This is the simplest calculation of volatility. It's the standard deviation of ln(close/close(1)).
Pseudo GARCH(2,2)
This is calculated using a short- and long-run mean of variance multiplied by ?.
avg(var;M) + (1 ? ?) avg(var;N) = 2?var/(M+1-(M-1)L) + 2(1-?)var/(M+1-(M-1)L)
Solving for ? can be done by minimizing the mean squared error of estimation; that is, regressing L^-1var - avg(var; N) against avg(var; M) - avg(var; N) and using the resulting beta estimate as ?.
Average True Range
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
The true range indicator is taken as the greatest of the following: current high less the current low; the absolute value of the current high less the previous close; and the absolute value of the current low less the previous close. The ATR is then a moving average, generally using 14 days, of the true ranges.
True Range Double
A special case of ATR that attempts to correct for volatility skew.
Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma ? or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis, we usually use it to measure the level of current volatility.
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA, we can call it EMA deviation. Additionally, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to the standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, a manual recreation of the quantile function in Pine Script is used. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is a widely used indicator for many occasions in technical analysis. It is calculated as the RMA of the true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range.
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation (SD). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
8. Metamorphosis - a technical indicator that produces a compound signal from the combination of other GKD indicators*
*(not part of the NNFX algorithm)
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, and the Average Directional Index (ADX).
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
What is an Metamorphosis indicator?
The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, or GKD-E slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v2.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
6. GKD-M - Metamorphosis module (Metamorphosis, Number 8 in the NNFX algorithm, but not part of the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data to A backtest module wherein the various components of the GKD system are combined to create a trading signal.
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Multi-Ticker CC Backtest
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Advance Trend Pressure as shown on the chart above
Confirmation 2: uf2018
Continuation: Coppock Curve
Exit: Rex Oscillator
Metamorphosis: Baseline Optimizer
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system.
█ Giga Kaleidoscope Modularized Trading System Signals
Standard Entry
1. GKD-C Confirmation gives signal
2. Baseline agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
1-Candle Standard Entry
1a. GKD-C Confirmation gives signal
2a. Baseline agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
7. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
1-Candle Baseline Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Volatility/Volume Entry
1. GKD-V Volatility/Volume gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Volatility/Volume Entry
1a. GKD-V Volatility/Volume gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSVVC Bars Back' prior
Next Candle
1b. Price retraced
2b. Volatility/Volume agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Baseline agrees
Confirmation 2 Entry
1. GKD-C Confirmation 2 gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Volatility/Volume agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Confirmation 2 Entry
1a. GKD-C Confirmation 2 gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSC2C Bars Back' prior
Next Candle
1b. Price retraced
2b. Confirmation 2 agrees
3b. Confirmation 1 agrees
4b. Volatility/Volume agrees
5b. Baseline agrees
PullBack Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price is beyond 1.0x Volatility of Baseline
Next Candle
1b. Price inside Goldie Locks Zone Minimum
2b. Price inside Goldie Locks Zone Maximum
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Continuation Entry
1. Standard Entry, 1-Candle Standard Entry, Baseline Entry, 1-Candle Baseline Entry, Volatility/Volume Entry, 1-Candle Volatility/Volume Entry, Confirmation 2 Entry, 1-Candle Confirmation 2 Entry, or Pullback entry triggered previously
2. Baseline hasn't crossed since entry signal trigger
4. Confirmation 1 agrees
5. Baseline agrees
6. Confirmation 2 agrees

GKD-C XMA Histogram [Loxx]The Giga Kaleidoscope GKD-C XMA Histogram is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System."
█ GKD-C XMA Histogram
The "XMA Histogram" utilizes a dynamic approach to analyze market trends through various types of moving averages, including Exponential Moving Average (EMA), Fast Exponential Moving Average (FEMA), Linear Weighted Moving Average (LWMA), Simple Moving Average (SMA), and Smoothed Moving Average (SMMA). This flexibility allows traders to select the moving average that best fits their trading style and market conditions. The indicator calculates the selected moving average over a specified period for a given price source, then examines the difference between the current and previous values of this moving average.
A threshold, adjusted for market precision, determines significant changes. If the change in the moving average exceeds this threshold, it signals potential market momentum. The histogram visualizes this momentum, marking upward momentum with green and downward momentum with red. The XMA Histogram is designed to signal potential entry and exit points, identifying when the price crosses the moving average in a way that suggests a strong trend. This tool is particularly useful for traders looking to capitalize on trends by providing a clear, visual representation of market momentum and direction shifts.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
8. Metamorphosis - a technical indicator that produces a compound signal from the combination of other GKD indicators*
*(not part of the NNFX algorithm)
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, and the Average Directional Index (ADX).
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
What is an Metamorphosis indicator?
The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, or GKD-E slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v2.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
6. GKD-M - Metamorphosis module (Metamorphosis, Number 8 in the NNFX algorithm, but not part of the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data to A backtest module wherein the various components of the GKD system are combined to create a trading signal.
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Multi-Ticker CC Backtest
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Advance Trend Pressure as shown on the chart above
Confirmation 2: uf2018
Continuation: Coppock Curve
Exit: Rex Oscillator
Metamorphosis: Baseline Optimizer
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system.
█ Giga Kaleidoscope Modularized Trading System Signals
Standard Entry
1. GKD-C Confirmation gives signal
2. Baseline agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
1-Candle Standard Entry
1a. GKD-C Confirmation gives signal
2a. Baseline agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
7. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
1-Candle Baseline Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Volatility/Volume Entry
1. GKD-V Volatility/Volume gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Volatility/Volume Entry
1a. GKD-V Volatility/Volume gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSVVC Bars Back' prior
Next Candle
1b. Price retraced
2b. Volatility/Volume agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Baseline agrees
Confirmation 2 Entry
1. GKD-C Confirmation 2 gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Volatility/Volume agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Confirmation 2 Entry
1a. GKD-C Confirmation 2 gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSC2C Bars Back' prior
Next Candle
1b. Price retraced
2b. Confirmation 2 agrees
3b. Confirmation 1 agrees
4b. Volatility/Volume agrees
5b. Baseline agrees
PullBack Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price is beyond 1.0x Volatility of Baseline
Next Candle
1b. Price inside Goldie Locks Zone Minimum
2b. Price inside Goldie Locks Zone Maximum
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Continuation Entry
1. Standard Entry, 1-Candle Standard Entry, Baseline Entry, 1-Candle Baseline Entry, Volatility/Volume Entry, 1-Candle Volatility/Volume Entry, Confirmation 2 Entry, 1-Candle Confirmation 2 Entry, or Pullback entry triggered previously
2. Baseline hasn't crossed since entry signal trigger
4. Confirmation 1 agrees
5. Baseline agrees
6. Confirmation 2 agrees

GKD-C Momentum Candles [Loxx]The Giga Kaleidoscope GKD-C Momentum Candles is a Confirmation module included in Loxx's "Giga Kaleidoscope Modularized Trading System."
█ GKD-C Momentum Candles
The Momentum Candles indicator uses the difference between the closing and opening prices divided by the Average True Range (ATR) over 50 periods to calculate momentum. It sets upper and lower thresholds based on an ATR multiplier: the upper threshold (Tresh1) is 1 divided by the ATR multiplier, and the lower threshold (Tresh2) is the negative inverse of this value. These thresholds help identify significant momentum shifts, generating long/short signals.
█ Giga Kaleidoscope Modularized Trading System
Core components of an NNFX algorithmic trading strategy
The NNFX algorithm is built on the principles of trend, momentum, and volatility. There are six core components in the NNFX trading algorithm:
1. Volatility - price volatility; e.g., Average True Range, True Range Double, Close-to-Close, etc.
2. Baseline - a moving average to identify price trend
3. Confirmation 1 - a technical indicator used to identify trends
4. Confirmation 2 - a technical indicator used to identify trends
5. Continuation - a technical indicator used to identify trends
6. Volatility/Volume - a technical indicator used to identify volatility/volume breakouts/breakdown
7. Exit - a technical indicator used to determine when a trend is exhausted
8. Metamorphosis - a technical indicator that produces a compound signal from the combination of other GKD indicators*
*(not part of the NNFX algorithm)
What is Volatility in the NNFX trading system?
In the NNFX (No Nonsense Forex) trading system, ATR (Average True Range) is typically used to measure the volatility of an asset. It is used as a part of the system to help determine the appropriate stop loss and take profit levels for a trade. ATR is calculated by taking the average of the true range values over a specified period.
True range is calculated as the maximum of the following values:
-Current high minus the current low
-Absolute value of the current high minus the previous close
-Absolute value of the current low minus the previous close
ATR is a dynamic indicator that changes with changes in volatility. As volatility increases, the value of ATR increases, and as volatility decreases, the value of ATR decreases. By using ATR in NNFX system, traders can adjust their stop loss and take profit levels according to the volatility of the asset being traded. This helps to ensure that the trade is given enough room to move, while also minimizing potential losses.
Other types of volatility include True Range Double (TRD), Close-to-Close, and Garman-Klass
What is a Baseline indicator?
The baseline is essentially a moving average, and is used to determine the overall direction of the market.
The baseline in the NNFX system is used to filter out trades that are not in line with the long-term trend of the market. The baseline is plotted on the chart along with other indicators, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR).
Trades are only taken when the price is in the same direction as the baseline. For example, if the baseline is sloping upwards, only long trades are taken, and if the baseline is sloping downwards, only short trades are taken. This approach helps to ensure that trades are in line with the overall trend of the market, and reduces the risk of entering trades that are likely to fail.
By using a baseline in the NNFX system, traders can have a clear reference point for determining the overall trend of the market, and can make more informed trading decisions. The baseline helps to filter out noise and false signals, and ensures that trades are taken in the direction of the long-term trend.
What is a Confirmation indicator?
Confirmation indicators are technical indicators that are used to confirm the signals generated by primary indicators. Primary indicators are the core indicators used in the NNFX system, such as the Average True Range (ATR), the Moving Average (MA), and the Relative Strength Index (RSI).
The purpose of the confirmation indicators is to reduce false signals and improve the accuracy of the trading system. They are designed to confirm the signals generated by the primary indicators by providing additional information about the strength and direction of the trend.
Some examples of confirmation indicators that may be used in the NNFX system include the Bollinger Bands, the MACD (Moving Average Convergence Divergence), and the MACD Oscillator. These indicators can provide information about the volatility, momentum, and trend strength of the market, and can be used to confirm the signals generated by the primary indicators.
In the NNFX system, confirmation indicators are used in combination with primary indicators and other filters to create a trading system that is robust and reliable. By using multiple indicators to confirm trading signals, the system aims to reduce the risk of false signals and improve the overall profitability of the trades.
What is a Continuation indicator?
In the NNFX (No Nonsense Forex) trading system, a continuation indicator is a technical indicator that is used to confirm a current trend and predict that the trend is likely to continue in the same direction. A continuation indicator is typically used in conjunction with other indicators in the system, such as a baseline indicator, to provide a comprehensive trading strategy.
What is a Volatility/Volume indicator?
Volume indicators, such as the On Balance Volume (OBV), the Chaikin Money Flow (CMF), or the Volume Price Trend (VPT), are used to measure the amount of buying and selling activity in a market. They are based on the trading volume of the market, and can provide information about the strength of the trend. In the NNFX system, volume indicators are used to confirm trading signals generated by the Moving Average and the Relative Strength Index. Volatility indicators include Average Direction Index, Waddah Attar, and Volatility Ratio. In the NNFX trading system, volatility is a proxy for volume and vice versa.
By using volume indicators as confirmation tools, the NNFX trading system aims to reduce the risk of false signals and improve the overall profitability of trades. These indicators can provide additional information about the market that is not captured by the primary indicators, and can help traders to make more informed trading decisions. In addition, volume indicators can be used to identify potential changes in market trends and to confirm the strength of price movements.
What is an Exit indicator?
The exit indicator is used in conjunction with other indicators in the system, such as the Moving Average (MA), the Relative Strength Index (RSI), and the Average True Range (ATR), to provide a comprehensive trading strategy.
The exit indicator in the NNFX system can be any technical indicator that is deemed effective at identifying optimal exit points. Examples of exit indicators that are commonly used include the Parabolic SAR, and the Average Directional Index (ADX).
The purpose of the exit indicator is to identify when a trend is likely to reverse or when the market conditions have changed, signaling the need to exit a trade. By using an exit indicator, traders can manage their risk and prevent significant losses.
In the NNFX system, the exit indicator is used in conjunction with a stop loss and a take profit order to maximize profits and minimize losses. The stop loss order is used to limit the amount of loss that can be incurred if the trade goes against the trader, while the take profit order is used to lock in profits when the trade is moving in the trader's favor.
Overall, the use of an exit indicator in the NNFX trading system is an important component of a comprehensive trading strategy. It allows traders to manage their risk effectively and improve the profitability of their trades by exiting at the right time.
What is an Metamorphosis indicator?
The concept of a metamorphosis indicator involves the integration of two or more GKD indicators to generate a compound signal. This is achieved by evaluating the accuracy of each indicator and selecting the signal from the indicator with the highest accuracy. As an illustration, let's consider a scenario where we calculate the accuracy of 10 indicators and choose the signal from the indicator that demonstrates the highest accuracy.
The resulting output from the metamorphosis indicator can then be utilized in a GKD-BT backtest by occupying a slot that aligns with the purpose of the metamorphosis indicator. The slot can be a GKD-B, GKD-C, or GKD-E slot, depending on the specific requirements and objectives of the indicator. This allows for seamless integration and utilization of the compound signal within the GKD-BT framework.
How does Loxx's GKD (Giga Kaleidoscope Modularized Trading System) implement the NNFX algorithm outlined above?
Loxx's GKD v2.0 system has five types of modules (indicators/strategies). These modules are:
1. GKD-BT - Backtesting module (Volatility, Number 1 in the NNFX algorithm)
2. GKD-B - Baseline module (Baseline and Volatility/Volume, Numbers 1 and 2 in the NNFX algorithm)
3. GKD-C - Confirmation 1/2 and Continuation module (Confirmation 1/2 and Continuation, Numbers 3, 4, and 5 in the NNFX algorithm)
4. GKD-V - Volatility/Volume module (Confirmation 1/2, Number 6 in the NNFX algorithm)
5. GKD-E - Exit module (Exit, Number 7 in the NNFX algorithm)
6. GKD-M - Metamorphosis module (Metamorphosis, Number 8 in the NNFX algorithm, but not part of the NNFX algorithm)
(additional module types will added in future releases)
Each module interacts with every module by passing data to A backtest module wherein the various components of the GKD system are combined to create a trading signal.
That is, the Baseline indicator passes its data to Volatility/Volume. The Volatility/Volume indicator passes its values to the Confirmation 1 indicator. The Confirmation 1 indicator passes its values to the Confirmation 2 indicator. The Confirmation 2 indicator passes its values to the Continuation indicator. The Continuation indicator passes its values to the Exit indicator, and finally, the Exit indicator passes its values to the Backtest strategy.
This chaining of indicators requires that each module conform to Loxx's GKD protocol, therefore allowing for the testing of every possible combination of technical indicators that make up the six components of the NNFX algorithm.
What does the application of the GKD trading system look like?
Example trading system:
Backtest: Multi-Ticker CC Backtest
Baseline: Hull Moving Average
Volatility/Volume: Hurst Exponent
Confirmation 1: Advance Trend Pressure as shown on the chart above
Confirmation 2: uf2018
Continuation: Coppock Curve
Exit: Rex Oscillator
Metamorphosis: Baseline Optimizer
Each GKD indicator is denoted with a module identifier of either: GKD-BT, GKD-B, GKD-C, GKD-V, GKD-M, or GKD-E. This allows traders to understand to which module each indicator belongs and where each indicator fits into the GKD system.
█ Giga Kaleidoscope Modularized Trading System Signals
Standard Entry
1. GKD-C Confirmation gives signal
2. Baseline agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
1-Candle Standard Entry
1a. GKD-C Confirmation gives signal
2a. Baseline agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Baseline Entry
1. GKD-B Baseline gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Volatility/Volume agrees
7. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
1-Candle Baseline Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSBC Bars Back' prior
Next Candle
1b. Price retraced
2b. Baseline agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Volatility/Volume Entry
1. GKD-V Volatility/Volume gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Confirmation 2 agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Volatility/Volume Entry
1a. GKD-V Volatility/Volume gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSVVC Bars Back' prior
Next Candle
1b. Price retraced
2b. Volatility/Volume agrees
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Baseline agrees
Confirmation 2 Entry
1. GKD-C Confirmation 2 gives signal
2. Confirmation 1 agrees
3. Price inside Goldie Locks Zone Minimum
4. Price inside Goldie Locks Zone Maximum
5. Volatility/Volume agrees
6. Baseline agrees
7. Confirmation 1 signal was less than 7 candles prior
1-Candle Confirmation 2 Entry
1a. GKD-C Confirmation 2 gives signal
2a. Confirmation 1 agrees
3a. Price inside Goldie Locks Zone Minimum
4a. Price inside Goldie Locks Zone Maximum
5a. Confirmation 1 signal was less than 'Maximum Allowable PSC2C Bars Back' prior
Next Candle
1b. Price retraced
2b. Confirmation 2 agrees
3b. Confirmation 1 agrees
4b. Volatility/Volume agrees
5b. Baseline agrees
PullBack Entry
1a. GKD-B Baseline gives signal
2a. Confirmation 1 agrees
3a. Price is beyond 1.0x Volatility of Baseline
Next Candle
1b. Price inside Goldie Locks Zone Minimum
2b. Price inside Goldie Locks Zone Maximum
3b. Confirmation 1 agrees
4b. Confirmation 2 agrees
5b. Volatility/Volume agrees
Continuation Entry
1. Standard Entry, 1-Candle Standard Entry, Baseline Entry, 1-Candle Baseline Entry, Volatility/Volume Entry, 1-Candle Volatility/Volume Entry, Confirmation 2 Entry, 1-Candle Confirmation 2 Entry, or Pullback entry triggered previously
2. Baseline hasn't crossed since entry signal trigger
4. Confirmation 1 agrees
5. Baseline agrees
6. Confirmation 2 agrees
