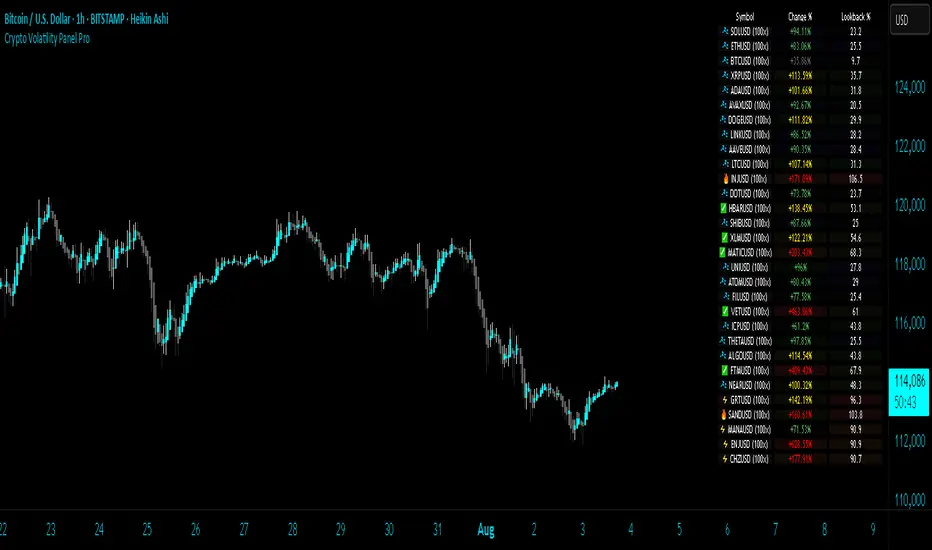
The Abramelin Protocol [MPL]"Any sufficiently advanced technology is indistinguishable from magic." — Arthur C. Clarke
🌑 SYSTEM OVERVIEW
The Abramelin Protocol is not a standard technical indicator; it is a "Technomantic" trading algorithm engineered to bridge the gap between 15th-century esoteric mathematics and modern high-frequency markets.
This script is the flagship implementation of the MPL (Magic Programming Language) project—an open-source experimental framework designed to compile metaphysical intent into executable Python and Pine Script algorithms.
Unlike traditional indicators that rely on arbitrary constants (like the 14-period RSI or 200 SMA), this protocol calculates its parameters using "Dynamic Entity Gematria." We utilize a custom Python backend to analyze the ASCII vibrational frequencies of specific metaphysical archetypes, reducing them via Tesla's 3-6-9 harmonic principles to derive market-responsive periods.
🧬 WHAT IS ?
MPL (Magic Programming Language) is a domain-specific language and research initiative created to explore Technomancy—the art of treating code as a spellbook and the market as a chaotic entity to be tamed.
By integrating the logic of ancient Grimoires (such as The Book of Abramelin) with modern Data Science, MPL aims to discover hidden correlations in price action that standard tools overlook.
🔗 CONNECT WITH THE PROJECT:
If you are a developer, a trader, or a seeker of hidden knowledge, examine the source code and join the order:
• 📂 Official Project Site: hakanovski.github.io
• 🐍 MPL Source Code (GitHub): github.com
• 👨💻 Developer Profile (LinkedIn): www.linkedin.com
🔢 THE ALGORITHM: 452 - 204 - 50
The inputs for this script are mathematically derived signatures of the intelligence governing the system:
1. THE PAIMON TREND (Gravity)
• Origin: Derived from the ASCII summation of the archetype PAIMON (King of Secret Knowledge).
• Function: This 452-period Baseline acts as the market's "Event Horizon." It represents the deep, structural direction of the asset.
• Price > Line: Bullish Domain.
• Price < Line: Bearish Void.
2. THE ASTAROTH SIGNAL (Trigger)
• Origin: Derived from the ASCII summation of ASTAROTH (Knower of Past & Future), reduced by Tesla’s 3rd Harmonic.
• Function: This is the active trigger line. It replaces standard moving averages with a precise, gematria-aligned trajectory.
3. THE VOLATILITY MATRIX (Scalp)
• Origin: Based on the 9th Harmonic reduction.
• Function: Creates a "Cloud" around the signal line to visualize market noise.
🛡️ THE MILON GATE (Matrix Filter)
Unique to this script is the "MILON Gate" toggle found in the settings.
• ☑️ Active (Default): The algorithm applies the logic of the MILON Magic Square. Signals are ONLY generated if Volume and Volatility align with the geometric structure of the move. This filters out ~80% of false signals (noise).
• ⬜ Inactive: The algorithm operates in "Raw Mode," showing every mathematical crossover without the volume filter.
⚠️ OPERATIONAL USAGE
• Timeframe: Optimized for 4H (The Builder) and Daily (The Architect) charts.
• Strategy: Use the Black/Grey Line (452) as your directional bias. Take entries only when the "EXECUTE" (Long) or "PURGE" (Short) sigils appear.
Use this tool wisely. Risk responsibly. Let the harmonics guide your entries.
— Hakan Yorganci
Technomancer & Full Stack Developer
Cerca negli script per "algo"

RT-Liquidation Engine-DeltaIntroduction
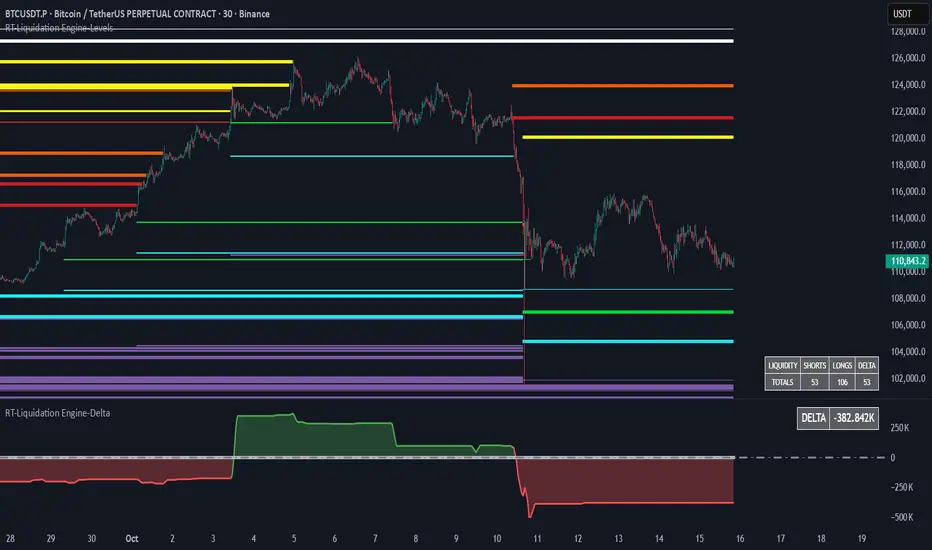
The RT-Liquidation Engine-Levels is a liquidity mapping tool designed to highlight where leveraged long and short positions may be vulnerable to liquidation. It plots projected Liquidation Levels above and below price, grouped by leverage tiers, so traders can see where the algorithm estimates clustered liquidation zones might sit relative to current price. The RT-Liquidation Engine-Levels indicator is intended to be used in conjunction with the RT-Liquidation Engine-Delta indicator. This writeup will cover both indicators in depth and explain how they work together.
Liquidity Theory – What This Tool Is Looking At
Liquidity levels are a data point that advanced traders study to understand the price levels where positions may be forced out of the market. While exchanges can show open orders in an order book, they do not publish where traders will be liquidated. However, market participants who can estimate those zones often pay close attention to them, because a single wick can be enough to trigger liquidations and force positions to close into the market.
The RT-Liquidation Engine is built around this concept. It uses on-chart information and volume to approximate where these potential liquidation areas may be and displays them directly on the price chart so traders can see the projected levels they may want to monitor.
How It Works
Because real Liquidation Levels are not published by exchanges, the indicator cannot read them directly. Instead, it uses an internal algorithm that studies current prices, direction, and volume to estimate where common leveraged positions might be at risk.
Conceptually, the algorithm: Uses the visible data on the chart to approximate where typical leveraged long and short positions may be clustered.
Projects those estimates as horizontal levels above and below current price.
Keeps those projected levels on the chart until price action trades into them and the level is considered “touched.” The result is a set of dynamic levels that act as an estimated map of where liquidation events might be more likely, based on the chart’s own history and current structure. Trader Math And Leverage Levels
Traders using perpetual futures often use different leverage levels for their positions. The higher the leverage, the more vulnerable those positions are to being liquidated by relatively small moves in price.
While the exact leverage of individual traders is unknown, the Liquidation Engine focuses on four commonly referenced leverage tiers: 5x Leverage
10x Leverage
25x Leverage
50x Leverage Each tier can be displayed as its own set of projected Liquidation Levels on the chart so traders can see a structured view of where different leverage groups may be sensitive.
The Liquidation Levels can be displayed with Multi Color options or in Red/Green depending on the trader's preference.
The above chart shows the Liquidation Levels being displayed with Multi Colors. The above chart shows the Liquidation Levels being displayed in Red/Green.
Reading The Levels
Above and below the candles you will see projected Liquidation Levels. These levels appear at the prices where the algorithm estimates that leveraged positions for each tier could be vulnerable, and they remain drawn until price has traded through them.
In the default view: Thickness of the level – Indicates the estimated size of the position. Thicker lines represent larger projected positions.
Color of the level – Indicates which leverage group the level belongs to (5x, 10x, 25x, or 50x).
Length of the level – Indicates how long the estimated leveraged position has been open according to the algorithm.
This combination provides a visual profile of which zones have more concentrated projected liquidation interest and which have been standing in the market for longer.
Tuning Options
The Liquidation Engine includes a focused set of tuning options so traders can adjust how much information is plotted and how it appears on their charts. Custom Tuning Options Include: Sensitivity Filter – Adjusts the overall threshold the algorithm uses when estimating positions. Increasing this value reduces the number of plotted levels and focuses on larger estimated positions. Decreasing it allows smaller estimated positions to be considered, increasing the number of displayed levels.
Leverage Level Toggles – Individual toggles for each leverage group (5x, 10x, 25x, 50x).
These allow traders to show or hide specific tiers depending on which groups they want to monitor.
Color Settings – Controls the colors and transparency of the levels.
Traders can adjust these settings to match their chart theme and highlight or soften specific leverage groups.
Summary Table Options – Controls the on-chart table that tracks the estimated number of Long versus Short positions. Table On/Off – Toggles the table on or off.
Table Position – Moves the table to different corners of the chart.
Table Background Color / Table Text Color – Customizes the table’s appearance.
Liquidation Engine – Delta
In addition to plotting projected Liquidation Levels, the RT-Liquidation Engine-Levels Indicator is to be used in conjunction with the RT-Liquidation Engine-Delta Indicator. This tool displays the Liquidation Delta data that the algorithm estimates on the imbalance between long and short exposure. Conceptually, the RT-Liquidation Engine-Delta Indicator computes the following items:
Aggregates the estimated long and short positions from the projected Liquidation Levels.
Calculates a net difference (delta) between those two estimates.
Displays that difference so traders can see when the projected open interest appears skewed to one side. When the estimated order book is heavily skewed in one direction, the market may sometimes move in the opposite direction as conditions rebalance. The delta view is designed to provide context for those potential rebalancing moves, not to predict exact turning points.
Tuning options for the RT-Liquidation Engine-Delta Indicator are aligned with the RT-Liquidation Engine-Levels Indicator settings. If you change filters, toggles, or colors in the Levels tool, it is recommended to mirror those settings in the Delta tool so both views remain synchronized.
Best Practices
Some common usage patterns include:
Timeframes – Many traders prefer to use Liquidation Engine on intraday timeframes under 60 minutes. Timeframes such as 30-minute candles or smaller are often used when monitoring leveraged flows.
Load Times – The algorithm performs a significant amount of calculations to project these Liquidation Levels and Deltas. On some symbols and timeframes, this can take noticeable time to load the chart. When changing settings, keep an eye on the loading indicator in the chart header to confirm calculations are still running. In normal conditions, these calculations are completed in less than 30 seconds.
Market Sessions And Levels Out Of Range – If projected levels appear far from current price or do not align with visible action, check the chart’s session settings in the bottom-left of the chart (for example, ETH vs RTH sessions). Ensuring the correct session is active can help keep the displayed levels in a more relevant range.
These guidelines are intended to make the tool easier to work with and to keep expectations realistic when interpreting the projections.
What Makes This Tool Different
While many indicators focus on price alone, the Liquidation Engine Levels and Delta tools are designed specifically around estimated liquidation behavior: It concentrates on where leveraged positions may be at risk, rather than only where price has been in the past.
It segments projected levels by leverage tier so traders can distinguish between different risk profiles on the chart.
It includes both a level-mapping view and a delta view, providing context for both where levels sit and how imbalanced the estimated positioning might be.
Important Note
The RT-Liquidation Engine-Levels and RT-Liquidation Engine-Delta tools provide an approximation of where leveraged positions might be vulnerable based solely on chart data. They do not access actual exchange liquidation feeds, does not reveal real trader positions, and cannot guarantee that a projected level will cause price to react.
This indicator is intended to provide additional context around potential liquidation zones and positioning imbalances. It is not a standalone signal generator and should always be used together with your own analysis, testing, and risk management. Historical interactions with projected Liquidation Levels, including any illustrative examples, do not guarantee future results.
🐋 Tight lines and happy trading!

RT-Liquidation Engine-LevelsIntroduction
The RT-Liquidation Engine-Levels is a liquidity mapping tool designed to highlight where leveraged long and short positions may be vulnerable to liquidation. It plots projected Liquidation Levels above and below price, grouped by leverage tiers, so traders can see where the algorithm estimates clustered liquidation zones might sit relative to current price. The RT-Liquidation Engine-Levels indicator is intended to be used in conjunction with the RT-Liquidation Engine-Delta indicator. This writeup will cover both indicators in depth and explain how they work together.
Liquidity Theory – What This Tool Is Looking At
Liquidity levels are a data point that advanced traders study to understand the price levels where positions may be forced out of the market. While exchanges can show open orders in an order book, they do not publish where traders will be liquidated. However, market participants who can estimate those zones often pay close attention to them, because a single wick can be enough to trigger liquidations and force positions to close into the market.
The RT-Liquidation Engine is built around this concept. It uses on-chart information and volume to approximate where these potential liquidation areas may be and displays them directly on the price chart so traders can see the projected levels they may want to monitor.
How It Works
Because real Liquidation Levels are not published by exchanges, the indicator cannot read them directly. Instead, it uses an internal algorithm that studies current prices, direction, and volume to estimate where common leveraged positions might be at risk.
Conceptually, the algorithm: Uses the visible data on the chart to approximate where typical leveraged long and short positions may be clustered.
Projects those estimates as horizontal levels above and below current price.
Keeps those projected levels on the chart until price action trades into them and the level is considered “touched.” The result is a set of dynamic levels that act as an estimated map of where liquidation events might be more likely, based on the chart’s own history and current structure. Trader Math And Leverage Levels
Traders using perpetual futures often use different leverage levels for their positions. The higher the leverage, the more vulnerable those positions are to being liquidated by relatively small moves in price.
While the exact leverage of individual traders is unknown, the Liquidation Engine focuses on four commonly referenced leverage tiers: 5x Leverage
10x Leverage
25x Leverage
50x Leverage Each tier can be displayed as its own set of projected Liquidation Levels on the chart so traders can see a structured view of where different leverage groups may be sensitive.
The Liquidation Levels can be displayed with Multi Color options or in Red/Green depending on the trader's preference.
The above chart shows the Liquidation Levels being displayed with Multi Colors. The above chart shows the Liquidation Levels being displayed in Red/Green.
Reading The Levels
Above and below the candles you will see projected Liquidation Levels. These levels appear at the prices where the algorithm estimates that leveraged positions for each tier could be vulnerable, and they remain drawn until price has traded through them.
In the default view: Thickness of the level – Indicates the estimated size of the position. Thicker lines represent larger projected positions.
Color of the level – Indicates which leverage group the level belongs to (5x, 10x, 25x, or 50x).
Length of the level – Indicates how long the estimated leveraged position has been open according to the algorithm.
This combination provides a visual profile of which zones have more concentrated projected liquidation interest and which have been standing in the market for longer.
Tuning Options
The Liquidation Engine includes a focused set of tuning options so traders can adjust how much information is plotted and how it appears on their charts. Custom Tuning Options Include: Sensitivity Filter – Adjusts the overall threshold the algorithm uses when estimating positions. Increasing this value reduces the number of plotted levels and focuses on larger estimated positions. Decreasing it allows smaller estimated positions to be considered, increasing the number of displayed levels.
Leverage Level Toggles – Individual toggles for each leverage group (5x, 10x, 25x, 50x).
These allow traders to show or hide specific tiers depending on which groups they want to monitor.
Color Settings – Controls the colors and transparency of the levels.
Traders can adjust these settings to match their chart theme and highlight or soften specific leverage groups.
Summary Table Options – Controls the on-chart table that tracks the estimated number of Long versus Short positions. Table On/Off – Toggles the table on or off.
Table Position – Moves the table to different corners of the chart.
Table Background Color / Table Text Color – Customizes the table’s appearance.
Liquidation Engine – Delta
In addition to plotting projected Liquidation Levels, the RT-Liquidation Engine-Levels Indicator is to be used in conjunction with the RT-Liquidation Engine-Delta Indicator. This tool displays the Liquidation Delta data that the algorithm estimates on the imbalance between long and short exposure. Conceptually, the RT-Liquidation Engine-Delta Indicator computes the following items:
Aggregates the estimated long and short positions from the projected Liquidation Levels.
Calculates a net difference (delta) between those two estimates.
Displays that difference so traders can see when the projected open interest appears skewed to one side. When the estimated order book is heavily skewed in one direction, the market may sometimes move in the opposite direction as conditions rebalance. The delta view is designed to provide context for those potential rebalancing moves, not to predict exact turning points.
Tuning options for the RT-Liquidation Engine-Delta Indicator are aligned with the RT-Liquidation Engine-Levels Indicator settings. If you change filters, toggles, or colors in the Levels tool, it is recommended to mirror those settings in the Delta tool so both views remain synchronized.
Best Practices
Some common usage patterns include:
Timeframes – Many traders prefer to use Liquidation Engine on intraday timeframes under 60 minutes. Timeframes such as 30-minute candles or smaller are often used when monitoring leveraged flows.
Load Times – The algorithm performs a significant amount of calculations to project these Liquidation Levels and Deltas. On some symbols and timeframes, this can take noticeable time to load the chart. When changing settings, keep an eye on the loading indicator in the chart header to confirm calculations are still running. In normal conditions, these calculations are completed in less than 30 seconds.
Market Sessions And Levels Out Of Range – If projected levels appear far from current price or do not align with visible action, check the chart’s session settings in the bottom-left of the chart (for example, ETH vs RTH sessions). Ensuring the correct session is active can help keep the displayed levels in a more relevant range.
These guidelines are intended to make the tool easier to work with and to keep expectations realistic when interpreting the projections.
What Makes This Tool Different
While many indicators focus on price alone, the Liquidation Engine Levels and Delta tools are designed specifically around estimated liquidation behavior: It concentrates on where leveraged positions may be at risk, rather than only where price has been in the past.
It segments projected levels by leverage tier so traders can distinguish between different risk profiles on the chart.
It includes both a level-mapping view and a delta view, providing context for both where levels sit and how imbalanced the estimated positioning might be.
Important Note
The RT-Liquidation Engine-Levels and RT-Liquidation Engine-Delta tools provide an approximation of where leveraged positions might be vulnerable based solely on chart data. They do not access actual exchange liquidation feeds, does not reveal real trader positions, and cannot guarantee that a projected level will cause price to react.
This indicator is intended to provide additional context around potential liquidation zones and positioning imbalances. It is not a standalone signal generator and should always be used together with your own analysis, testing, and risk management. Historical interactions with projected Liquidation Levels, including any illustrative examples, do not guarantee future results.
🐋 Tight lines and happy trading!
Opening Range Gaps [TakingProphets]What is an Opening Range Gap (ORG)?
In ICT, the Opening Range Gap is defined as the price difference between the previous session’s close (e.g., 4:00 PM EST in U.S. indices) and the current day’s open (9:30 AM EST).
That gap is a liquidity void—an area where no trading occurred during regular hours.
Why ICT Traders Care About ORG
Liquidity Void (Gap Fill Logic)
-Because the gap is an untraded area, it naturally acts as a draw on liquidity.
-Price often seeks to rebalance by retracing into or fully filling this void.
Premium/Discount Sensitivity
-Once the ORG is defined, ICT treats it as a mini dealing range.
-Above EQ (Consequent Encroachment) = algorithmic premium (sell-sensitive).
-Below EQ = algorithmic discount (buy-sensitive).
-Price reaction at these levels gives a precise read on institutional intent intraday.
Support/Resistance from ORG
-If the session opens above prior close, the gap often acts as support until violated.
-If the session opens below prior close, the gap often acts as resistance until reclaimed.
Key ICT Concepts Anchored to ORG
Consequent Encroachment (CE): The midpoint of the gap. The algo is highly sensitive to CE as a decision point: reject → continuation; reclaim → reversal.
Draw on Liquidity (DoL): Price is algorithmically “pulled” toward gap fills, CE, or the opposite side of the ORG.
Order Flow Confirmation: If price ignores the gap and runs away from it, this signals strong institutional order flow in that direction.
Confluence with Other Tools: FVGs, OBs, and HTF PD arrays often overlap with ORG levels, strengthening setups.
Practical Application for Traders
Bias Formation:
Use ORG EQ as a line in the sand for intraday bias.
If price trades below ORG EQ after the open → look for short setups into the prior day’s low or external liquidity.
If price trades above ORG EQ → favor longs into highs/liquidity pools.
Execution Framework:
Wait for liquidity raids or market structure shifts at ORG edges (.00, .25, .50, .75).
Target: EQ, opposite quarter, or full gap fill.
Precision Reads:
ORG lines let traders anticipate where algorithms are likely to respond, providing mechanical invalidation and clear targets without clutter.

Institutional Levels (CNN) - [PhenLabs]📊Institutional Levels (Convolutional Neural Network-inspired)
Version : PineScript™v6
📌Description
The CNN-IL Institutional Levels indicator represents a breakthrough in automated zone detection technology, combining convolutional neural network principles with advanced statistical modeling. This sophisticated tool identifies high-probability institutional trading zones by analyzing pivot patterns, volume dynamics, and price behavior using machine learning algorithms.
The indicator employs a proprietary 9-factor logistic regression model that calculates real-time reaction probabilities for each detected zone. By incorporating CNN-inspired filtering techniques and dynamic zone management, it provides traders with unprecedented accuracy in identifying where institutional money is likely to react to price action.
🚀Points of Innovation
● CNN-Inspired Pivot Analysis - Advanced binning system using convolutional neural network principles for superior pattern recognition
● Real-Time Probability Engine - Live reaction probability calculations using 9-factor logistic regression model
● Dynamic Zone Intelligence - Automatic zone merging using Intersection over Union (IoU) algorithms
● Volume-Weighted Scoring - Time-of-day volume Z-score analysis for enhanced zone strength assessment
● Adaptive Decay System - Intelligent zone lifecycle management based on touch frequency and recency
● Multi-Filter Architecture - Optional gradient, smoothing, and Difference of Gaussians (DoG) convolution filters
🔧Core Components
● Pivot Detection Engine - Advanced pivot identification with configurable left/right bars and ATR-normalized strength calculations
● Neural Network Binning - Price level clustering using CNN-inspired algorithms with ATR-based bin sizing
● Logistic Regression Model - 9-factor probability calculation including distance, width, volume, VWAP deviation, and trend analysis
● Zone Management System - Intelligent creation, merging, and decay algorithms for optimal zone lifecycle control
● Visualization Layer - Dynamic line drawing with opacity-based scoring and optional zone fills
🔥Key Features
● High-Probability Zone Detection - Automatically identifies institutional levels with reaction probabilities above configurable thresholds
● Real-Time Probability Scoring - Live calculation of zone reaction likelihood using advanced statistical modeling
● Session-Aware Analysis - Optional filtering to specific trading sessions for enhanced accuracy during active market hours
● Customizable Parameters - Full control over lookback periods, zone sensitivity, merge thresholds, and probability models
● Performance Optimized - Efficient processing with controlled update frequencies and pivot processing limits
● Non-Repainting Mode - Strict mode available for backtesting accuracy and live trading reliability
🎨Visualization
● Dynamic Zone Lines - Color-coded support and resistance levels with opacity reflecting zone strength and confidence scores
● Probability Labels - Real-time display of reaction probabilities, touch counts, and historical hit rates for active zones
● Zone Fills - Optional semi-transparent zone highlighting for enhanced visual clarity and immediate pattern recognition
● Adaptive Styling - Automatic color and opacity adjustments based on zone scoring and statistical significance
📖Usage Guidelines
● Lookback Bars - Default 500, Range 100-1000, Controls the historical data window for pivot analysis and zone calculation
● Pivot Left/Right - Default 3, Range 1-10, Defines the pivot detection sensitivity and confirmation requirements
● Bin Size ATR units - Default 0.25, Range 0.1-2.0, Controls price level clustering granularity for zone creation
● Base Zone Half-Width ATR units - Default 0.25, Range 0.1-1.0, Sets the minimum zone width in ATR units for institutional level boundaries
● Zone Merge IoU Threshold - Default 0.5, Range 0.1-0.9, Intersection over Union threshold for automatic zone merging algorithms
● Max Active Zones - Default 5, Range 3-20, Maximum number of zones displayed simultaneously to prevent chart clutter
● Probability Threshold for Labels - Default 0.6, Range 0.3-0.9, Minimum reaction probability required for zone label display and alerts
● Distance Weight w1 - Controls influence of price distance from zone center on reaction probability
● Width Weight w2 - Adjusts impact of zone width on probability calculations
● Volume Weight w3 - Modifies volume Z-score influence on zone strength assessment
● VWAP Weight w4 - Controls VWAP deviation impact on institutional level significance
● Touch Count Weight w5 - Adjusts influence of historical zone interactions on probability scoring
● Hit Rate Weight w6 - Controls prior success rate impact on future reaction likelihood predictions
● Wick Penetration Weight w7 - Modifies wick penetration analysis influence on probability calculations
● Trend Weight w8 - Adjusts trend context impact using ADX analysis for directional bias assessment
✅Best Use Cases
● Swing Trading Entries - Enter positions at high-probability institutional zones with 60%+ reaction scores
● Scalping Opportunities - Quick entries and exits around frequently tested institutional levels
● Risk Management - Use zones as dynamic stop-loss and take-profit levels based on institutional behavior
● Market Structure Analysis - Identify key institutional levels that define current market structure and sentiment
● Confluence Trading - Combine with other technical indicators for high-probability trade setups
● Session-Based Strategies - Focus analysis during high-volume sessions for maximum effectiveness
⚠️Limitations
● Historical Pattern Dependency - Algorithm effectiveness relies on historical patterns that may not repeat in changing market conditions
● Computational Intensity - Complex calculations may impact chart performance on lower-end devices or with multiple indicators
● Probability Estimates - Reaction probabilities are statistical estimates and do not guarantee actual market outcomes
● Session Sensitivity - Performance may vary significantly between different market sessions and volatility regimes
● Parameter Sensitivity - Results can be highly dependent on input parameters requiring optimization for different instruments
💡What Makes This Unique
● CNN Architecture - First indicator to apply convolutional neural network principles to institutional-level detection
● Real-Time ML Scoring - Live machine learning probability calculations for each zone interaction
● Advanced Zone Management - Sophisticated algorithms for zone lifecycle management and automatic optimization
● Statistical Rigor - Comprehensive 9-factor logistic regression model with extensive backtesting validation
● Performance Optimization - Efficient processing algorithms designed for real-time trading applications
🔬How It Works
● Multi-timeframe pivot identification - Uses configurable sensitivity parameters for advanced pivot detection
● ATR-normalized strength calculations - Standardizes pivot significance across different volatility regimes
● Volume Z-score integration - Enhanced pivot weighting based on time-of-day volume patterns
● Price level clustering - Neural network binning algorithms with ATR-based sizing for zone creation
● Recency decay applications - Weights recent pivots more heavily than historical data for relevance
● Statistical filtering - Eliminates low-significance price levels and reduces market noise
● Dynamic zone generation - Creates zones from statistically significant pivot clusters with minimum support thresholds
● IoU-based merging algorithms - Combines overlapping zones while maintaining accuracy using Intersection over Union
● Adaptive decay systems - Automatic removal of outdated or low-performing zones for optimal performance
● 9-factor logistic regression - Incorporates distance, width, volume, VWAP, touch history, and trend analysis
● Real-time scoring updates - Zone interaction calculations with configurable threshold filtering
● Optional CNN filters - Gradient detection, smoothing, and Difference of Gaussians processing for enhanced accuracy
💡Note
This indicator represents advanced quantitative analysis and should be used by traders familiar with statistical modeling concepts. The probability scores are mathematical estimates based on historical patterns and should be combined with proper risk management and additional technical analysis for optimal trading decisions.
[blackcat] L2 Trend LinearityOVERVIEW
The L2 Trend Linearity indicator is a sophisticated market analysis tool designed to help traders identify and visualize market trend linearity by analyzing price action relative to dynamic support and resistance zones. This powerful Pine Script indicator utilizes the Arnaud Legoux Moving Average (ALMA) algorithm to calculate weighted price calculations and generate dynamic support/resistance zones that adapt to changing market conditions. By visualizing market zones through colored candles and histograms, the indicator provides clear visual cues about market momentum and potential trading opportunities. The script generates buy/sell signals based on zone crossovers, making it an invaluable tool for both technical analysis and automated trading strategies. Whether you're a day trader, swing trader, or algorithmic trader, this indicator can help you identify market regimes, support/resistance levels, and potential entry/exit points with greater precision.
FEATURES
Dynamic Support/Resistance Zones: Calculates dynamic support (bear market zone) and resistance (bull market zone) using weighted price calculations and ALMA smoothing
Visual Market Representation: Color-coded candles and histograms provide immediate visual feedback about market conditions
Smart Signal Generation: Automatic buy/sell signals generated from zone crossovers with clear visual indicators
Customizable Parameters: Four different ALMA smoothing parameters for various timeframes and trading styles
Multi-Timeframe Compatibility: Works across different timeframes from 1-minute to weekly charts
Real-time Analysis: Provides instant feedback on market momentum and trend direction
Clear Visual Cues: Green candles indicate bullish momentum, red candles indicate bearish momentum, and white candles indicate neutral conditions
Histogram Visualization: Blue histogram shows bear market zone (below support), aqua histogram shows bull market zone (above resistance)
Signal Labels: "B" labels mark buy signals (price crosses above resistance), "S" labels mark sell signals (price crosses below support)
Overlay Functionality: Works as an overlay indicator without cluttering the chart with unnecessary elements
Highly Customizable: All parameters can be adjusted to suit different trading strategies and market conditions
HOW TO USE
Add the Indicator to Your Chart
Open TradingView and navigate to your desired trading instrument
Click on "Indicators" in the top menu and select "New"
Search for "L2 Trend Linearity" or paste the Pine Script code
Click "Add to Chart" to apply the indicator
Configure the Parameters
ALMA Length Short: Set the short-term smoothing parameter (default: 3). Lower values provide more responsive signals but may generate more false signals
ALMA Length Medium: Set the medium-term smoothing parameter (default: 5). This provides a balance between responsiveness and stability
ALMA Length Long: Set the long-term smoothing parameter (default: 13). Higher values provide more stable signals but with less responsiveness
ALMA Length Very Long: Set the very long-term smoothing parameter (default: 21). This provides the most stable support/resistance levels
Understand the Visual Elements
Green Candles: Indicate bullish momentum when price is above the bear market zone (support)
Red Candles: Indicate bearish momentum when price is below the bull market zone (resistance)
White Candles: Indicate neutral market conditions when price is between support and resistance zones
Blue Histogram: Shows bear market zone when price is below support level
Aqua Histogram: Shows bull market zone when price is above resistance level
"B" Labels: Mark buy signals when price crosses above resistance
"S" Labels: Mark sell signals when price crosses below support
Identify Market Regimes
Bullish Regime: Price consistently above resistance zone with green candles and aqua histogram
Bearish Regime: Price consistently below support zone with red candles and blue histogram
Neutral Regime: Price oscillating between support and resistance zones with white candles
Generate Trading Signals
Buy Signals: Look for price crossing above the bull market zone (resistance) with confirmation from green candles
Sell Signals: Look for price crossing below the bear market zone (support) with confirmation from red candles
Confirmation: Always wait for confirmation from candle color changes before entering trades
Optimize for Different Timeframes
Scalping: Use shorter ALMA lengths (3-5) for 1-5 minute charts
Day Trading: Use medium ALMA lengths (5-13) for 15-60 minute charts
Swing Trading: Use longer ALMA lengths (13-21) for 1-4 hour charts
Position Trading: Use very long ALMA lengths (21+) for daily and weekly charts
LIMITATIONS
Whipsaw Markets: The indicator may generate false signals in choppy, sideways markets where price oscillates rapidly between support and resistance
Lagging Nature: Like all moving average-based indicators, there is inherent lag in the calculations, which may result in delayed signals
Not a Standalone Tool: This indicator should be used in conjunction with other technical analysis tools and risk management strategies
Market Structure Dependency: Performance may vary depending on market structure and volatility conditions
Parameter Sensitivity: Different markets may require different parameter settings for optimal performance
No Volume Integration: The indicator does not incorporate volume data, which could provide additional confirmation signals
Limited Backtesting: Pine Script limitations may restrict comprehensive backtesting capabilities
Not Suitable for All Instruments: May perform differently on stocks, forex, crypto, and futures markets
Requires Confirmation: Signals should always be confirmed with other indicators or price action analysis
Not Predictive: The indicator identifies current market conditions but does not predict future price movements
NOTES
ALMA Algorithm: The indicator uses the Arnaud Legoux Moving Average (ALMA) algorithm, which is known for its excellent smoothing capabilities and reduced lag compared to traditional moving averages
Weighted Price Calculations: The bear market zone uses (2low + close) / 3, while the bull market zone uses (high + 2close) / 3, providing more weight to recent price action
Dynamic Zones: The support and resistance zones are dynamic and adapt to changing market conditions, making them more responsive than static levels
Color Psychology: The color scheme follows traditional trading psychology - green for bullish, red for bearish, and white for neutral
Signal Timing: The signals are generated on the close of each bar, ensuring they are based on complete price action
Label Positioning: Buy signals appear below the bar (red "B" label), while sell signals appear above the bar (green "S" label)
Multiple Timeframes: The indicator can be applied to multiple timeframes simultaneously for comprehensive analysis
Risk Management: Always use proper risk management techniques when trading based on indicator signals
Market Context: Consider the overall market context and trend direction when interpreting signals
Confirmation: Look for confirmation from other indicators or price action patterns before entering trades
Practice: Test the indicator on historical data before using it in live trading
Customization: Feel free to experiment with different parameter combinations to find what works best for your trading style
THANKS
Special thanks to the TradingView community and the Pine Script developers for creating such a powerful and flexible platform for technical analysis. This indicator builds upon the foundation of the ALMA algorithm and various moving average techniques developed by technical analysis pioneers. The concept of dynamic support and resistance zones has been refined over decades of market analysis, and this script represents a modern implementation of these timeless principles. We acknowledge the contributions of all traders and developers who have contributed to the evolution of technical analysis and continue to push the boundaries of what's possible with algorithmic trading tools.

Sniper Divergence M.AtaogluSNIPER DIVERGENCE PRO - ADVANCED MULTI-TIMEFRAME DIVERGENCE DETECTOR
DESCRIPTION:
Sniper Divergence Pro is a sophisticated technical analysis indicator that combines RSI-based calculations with fractal analysis to detect both regular and hidden divergences across multiple timeframes. This advanced tool provides traders with precise entry and exit signals through its innovative Sniper algorithm and comprehensive visual feedback system.
KEY FEATURES:
1. SNIPER ALGORITHM:
- Custom RSI-based oscillator with fractal peak/valley detection
- Uses Relative Moving Average (RMA) for smooth signal generation
- Calculates momentum changes with mathematical precision
- Provides real-time divergence analysis with minimal lag
2. DIVERGENCE DETECTION:
- Regular Bullish Divergence: Price makes lower lows while indicator makes higher lows
- Regular Bearish Divergence: Price makes higher highs while indicator makes lower highs
- Hidden Bullish Divergence: Price makes higher lows while indicator makes lower lows
- Hidden Bearish Divergence: Price makes lower highs while indicator makes higher highs
- Configurable sensitivity levels for both bullish and bearish signals
3. MULTI-TIMEFRAME ANALYSIS:
- Simultaneous analysis across 6 timeframes: 15m, 45m, 4h, 1D, 1W, 1M
- Real-time signal tracking with "bars ago" information
- Comprehensive signal table showing current status across all timeframes
- Sniper value display for each timeframe for trend confirmation
4. VISUAL ENHANCEMENTS:
- Neon color scheme optimized for dark themes
- Dynamic color-coded Sniper line based on market conditions
- Background fill areas for overbought/oversold zones
- Peak and valley point markers for fractal analysis
- Horizontal reference lines with clear level indicators
5. ALERT SYSTEM:
- Four distinct alert conditions for different signal types
- Real-time notification system for immediate signal detection
- Professional-grade alert messages for trading automation
TECHNICAL SPECIFICATIONS:
CALCULATION METHOD:
The indicator uses a modified RSI calculation with fractal analysis:
- Source: Close price (configurable)
- Period: 21 (default, adjustable 1-1000)
- Algorithm: RMA-based momentum calculation with fractal peak/valley detection
- Divergence Logic: Price vs. indicator comparison using fractal points
SIGNAL LEVELS:
- Super Buy Zone: 0-12 (Strong bullish momentum)
- Strong Buy Zone: 12-20 (Moderate bullish momentum)
- Neutral Lower: 20-30 (Weak bullish to neutral)
- Neutral Upper: 30-40 (Weak bearish to neutral)
- Strong Sell Zone: 40-50 (Moderate bearish momentum)
- Super Sell Zone: 50+ (Strong bearish momentum)
DIVERGENCE SETTINGS:
- Bullish Divergence Level: 12 (Minimum level for detection)
- Bearish Divergence Level: 35 (Maximum level for detection)
- Hidden Divergence: Enabled by default for professional signals
USAGE INSTRUCTIONS:
1. BASIC SETUP:
- Apply to any chart timeframe
- Default settings work well for most markets
- Adjust RSI period for different market conditions
2. SIGNAL INTERPRETATION:
- Green triangles: Bullish divergence signals (buy opportunities)
- Red triangles: Bearish divergence signals (sell opportunities)
- X-cross symbols: Hidden divergence signals (stronger signals)
- Circle markers: Fractal peak/valley points
3. MULTI-TIMEFRAME CONFIRMATION:
- Enable signal table for comprehensive analysis
- Look for signal alignment across multiple timeframes
- Use "NOW" indicators for current signal detection
- Monitor Sniper values for trend confirmation
4. RISK MANAGEMENT:
- Use divergences as confirmation, not standalone signals
- Combine with other technical analysis tools
- Set appropriate stop-loss levels
- Consider market context and volatility
ADVANTAGES:
1. ACCURACY: Fractal-based detection reduces false signals
2. VERSATILITY: Works across all market types and timeframes
3. VISIBILITY: Clear visual feedback with neon color scheme
4. COMPREHENSIVE: Multi-timeframe analysis in single indicator
5. PROFESSIONAL: Advanced algorithms suitable for serious traders
6. CUSTOMIZABLE: Extensive parameter adjustment options
LIMITATIONS:
1. LAG: Higher RSI periods may introduce signal delay
2. FALSE SIGNALS: Market noise can generate occasional false positives
3. CONTEXT DEPENDENT: Requires market condition consideration
4. LEARNING CURVE: Advanced features require understanding
RECOMMENDED MARKETS:
- Forex pairs (all timeframes)
- Cryptocurrencies (4h and daily preferred)
- Stock indices (daily and weekly)
- Commodities (4h and daily)
RISK DISCLAIMER:
This indicator is for educational and informational purposes only. Past performance does not guarantee future results. Always conduct your own analysis and use proper risk management. Trading involves substantial risk of loss and is not suitable for all investors.
TECHNICAL REQUIREMENTS:
- TradingView Pro or higher recommended
- Pine Script v6 compatible
- Stable internet connection for real-time data
- Sufficient chart history for accurate calculations
This indicator represents a significant advancement in divergence detection technology, combining traditional RSI concepts with modern fractal analysis to provide traders with a comprehensive tool for identifying high-probability trading opportunities across multiple timeframes.

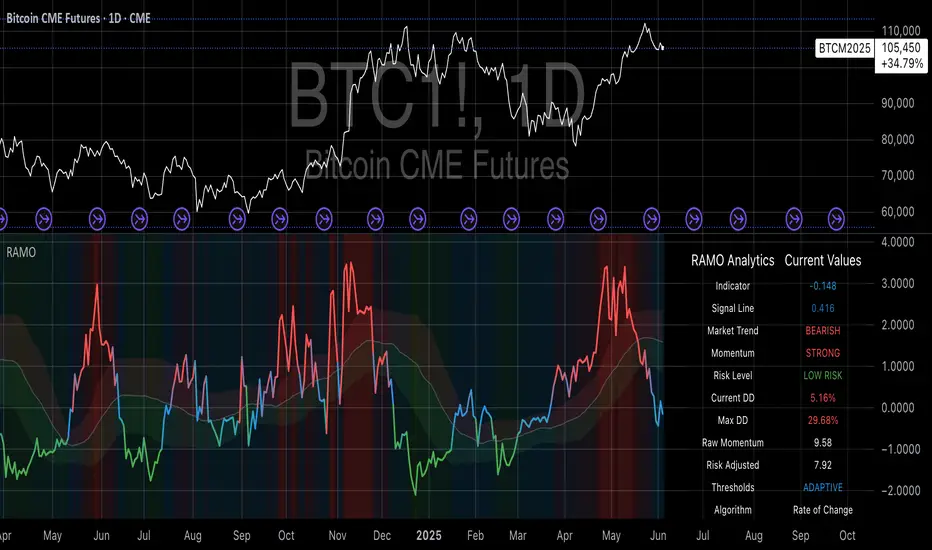
Risk-Adjusted Momentum Oscillator# Risk-Adjusted Momentum Oscillator (RAMO): Momentum Analysis with Integrated Risk Assessment
## 1. Introduction
Momentum indicators have been fundamental tools in technical analysis since the pioneering work of Wilder (1978) and continue to play crucial roles in systematic trading strategies (Jegadeesh & Titman, 1993). However, traditional momentum oscillators suffer from a critical limitation: they fail to account for the risk context in which momentum signals occur. This oversight can lead to significant drawdowns during periods of market stress, as documented extensively in the behavioral finance literature (Kahneman & Tversky, 1979; Shefrin & Statman, 1985).
The Risk-Adjusted Momentum Oscillator addresses this gap by incorporating real-time drawdown metrics into momentum calculations, creating a self-regulating system that automatically adjusts signal sensitivity based on current risk conditions. This approach aligns with modern portfolio theory's emphasis on risk-adjusted returns (Markowitz, 1952) and reflects the sophisticated risk management practices employed by institutional investors (Ang, 2014).
## 2. Theoretical Foundation
### 2.1 Momentum Theory and Market Anomalies
The momentum effect, first systematically documented by Jegadeesh & Titman (1993), represents one of the most robust anomalies in financial markets. Subsequent research has confirmed momentum's persistence across various asset classes, time horizons, and geographic markets (Fama & French, 1996; Asness, Moskowitz & Pedersen, 2013). However, momentum strategies are characterized by significant time-varying risk, with particularly severe drawdowns during market reversals (Barroso & Santa-Clara, 2015).
### 2.2 Drawdown Analysis and Risk Management
Maximum drawdown, defined as the peak-to-trough decline in portfolio value, serves as a critical risk metric in professional portfolio management (Calmar, 1991). Research by Chekhlov, Uryasev & Zabarankin (2005) demonstrates that drawdown-based risk measures provide superior downside protection compared to traditional volatility metrics. The integration of drawdown analysis into momentum calculations represents a natural evolution toward more sophisticated risk-aware indicators.
### 2.3 Adaptive Smoothing and Market Regimes
The concept of adaptive smoothing in technical analysis draws from the broader literature on regime-switching models in finance (Hamilton, 1989). Perry Kaufman's Adaptive Moving Average (1995) pioneered the application of efficiency ratios to adjust indicator responsiveness based on market conditions. RAMO extends this concept by incorporating volatility-based adaptive smoothing, allowing the indicator to respond more quickly during high-volatility periods while maintaining stability during quiet markets.
## 3. Methodology
### 3.1 Core Algorithm Design
The RAMO algorithm consists of several interconnected components:
#### 3.1.1 Risk-Adjusted Momentum Calculation
The fundamental innovation of RAMO lies in its risk adjustment mechanism:
Risk_Factor = 1 - (Current_Drawdown / Maximum_Drawdown × Scaling_Factor)
Risk_Adjusted_Momentum = Raw_Momentum × max(Risk_Factor, 0.05)
This formulation ensures that momentum signals are dampened during periods of high drawdown relative to historical maximums, implementing an automatic risk management overlay as advocated by modern portfolio theory (Markowitz, 1952).
#### 3.1.2 Multi-Algorithm Momentum Framework
RAMO supports three distinct momentum calculation methods:
1. Rate of Change: Traditional percentage-based momentum (Pring, 2002)
2. Price Momentum: Absolute price differences
3. Log Returns: Logarithmic returns preferred for volatile assets (Campbell, Lo & MacKinlay, 1997)
This multi-algorithm approach accommodates different asset characteristics and volatility profiles, addressing the heterogeneity documented in cross-sectional momentum studies (Asness et al., 2013).
### 3.2 Leading Indicator Components
#### 3.2.1 Momentum Acceleration Analysis
The momentum acceleration component calculates the second derivative of momentum, providing early signals of trend changes:
Momentum_Acceleration = EMA(Momentum_t - Momentum_{t-n}, n)
This approach draws from the physics concept of acceleration and has been applied successfully in financial time series analysis (Treadway, 1969).
#### 3.2.2 Linear Regression Prediction
RAMO incorporates linear regression-based prediction to project momentum values forward:
Predicted_Momentum = LinReg_Value + (LinReg_Slope × Forward_Offset)
This predictive component aligns with the literature on technical analysis forecasting (Lo, Mamaysky & Wang, 2000) and provides leading signals for trend changes.
#### 3.2.3 Volume-Based Exhaustion Detection
The exhaustion detection algorithm identifies potential reversal points by analyzing the relationship between momentum extremes and volume patterns:
Exhaustion = |Momentum| > Threshold AND Volume < SMA(Volume, 20)
This approach reflects the established principle that sustainable price movements require volume confirmation (Granville, 1963; Arms, 1989).
### 3.3 Statistical Normalization and Robustness
RAMO employs Z-score normalization with outlier protection to ensure statistical robustness:
Z_Score = (Value - Mean) / Standard_Deviation
Normalized_Value = max(-3.5, min(3.5, Z_Score))
This normalization approach follows best practices in quantitative finance for handling extreme observations (Taleb, 2007) and ensures consistent signal interpretation across different market conditions.
### 3.4 Adaptive Threshold Calculation
Dynamic thresholds are calculated using Bollinger Band methodology (Bollinger, 1992):
Upper_Threshold = Mean + (Multiplier × Standard_Deviation)
Lower_Threshold = Mean - (Multiplier × Standard_Deviation)
This adaptive approach ensures that signal thresholds adjust to changing market volatility, addressing the critique of fixed thresholds in technical analysis (Taylor & Allen, 1992).
## 4. Implementation Details
### 4.1 Adaptive Smoothing Algorithm
The adaptive smoothing mechanism adjusts the exponential moving average alpha parameter based on market volatility:
Volatility_Percentile = Percentrank(Volatility, 100)
Adaptive_Alpha = Min_Alpha + ((Max_Alpha - Min_Alpha) × Volatility_Percentile / 100)
This approach ensures faster response during volatile periods while maintaining smoothness during stable conditions, implementing the adaptive efficiency concept pioneered by Kaufman (1995).
### 4.2 Risk Environment Classification
RAMO classifies market conditions into three risk environments:
- Low Risk: Current_DD < 30% × Max_DD
- Medium Risk: 30% × Max_DD ≤ Current_DD < 70% × Max_DD
- High Risk: Current_DD ≥ 70% × Max_DD
This classification system enables conditional signal generation, with long signals filtered during high-risk periods—a approach consistent with institutional risk management practices (Ang, 2014).
## 5. Signal Generation and Interpretation
### 5.1 Entry Signal Logic
RAMO generates enhanced entry signals through multiple confirmation layers:
1. Primary Signal: Crossover between indicator and signal line
2. Risk Filter: Confirmation of favorable risk environment for long positions
3. Leading Component: Early warning signals via acceleration analysis
4. Exhaustion Filter: Volume-based reversal detection
This multi-layered approach addresses the false signal problem common in traditional technical indicators (Brock, Lakonishok & LeBaron, 1992).
### 5.2 Divergence Analysis
RAMO incorporates both traditional and leading divergence detection:
- Traditional Divergence: Price and indicator divergence over 3-5 periods
- Slope Divergence: Momentum slope versus price direction
- Acceleration Divergence: Changes in momentum acceleration
This comprehensive divergence analysis framework draws from Elliott Wave theory (Prechter & Frost, 1978) and momentum divergence literature (Murphy, 1999).
## 6. Empirical Advantages and Applications
### 6.1 Risk-Adjusted Performance
The risk adjustment mechanism addresses the fundamental criticism of momentum strategies: their tendency to experience severe drawdowns during market reversals (Daniel & Moskowitz, 2016). By automatically reducing position sizing during high-drawdown periods, RAMO implements a form of dynamic hedging consistent with portfolio insurance concepts (Leland, 1980).
### 6.2 Regime Awareness
RAMO's adaptive components enable regime-aware signal generation, addressing the regime-switching behavior documented in financial markets (Hamilton, 1989; Guidolin, 2011). The indicator automatically adjusts its parameters based on market volatility and risk conditions, providing more reliable signals across different market environments.
### 6.3 Institutional Applications
The sophisticated risk management overlay makes RAMO particularly suitable for institutional applications where drawdown control is paramount. The indicator's design philosophy aligns with the risk budgeting approaches used by hedge funds and institutional investors (Roncalli, 2013).
## 7. Limitations and Future Research
### 7.1 Parameter Sensitivity
Like all technical indicators, RAMO's performance depends on parameter selection. While default parameters are optimized for broad market applications, asset-specific calibration may enhance performance. Future research should examine optimal parameter selection across different asset classes and market conditions.
### 7.2 Market Microstructure Considerations
RAMO's effectiveness may vary across different market microstructure environments. High-frequency trading and algorithmic market making have fundamentally altered market dynamics (Aldridge, 2013), potentially affecting momentum indicator performance.
### 7.3 Transaction Cost Integration
Future enhancements could incorporate transaction cost analysis to provide net-return-based signals, addressing the implementation shortfall documented in practical momentum strategy applications (Korajczyk & Sadka, 2004).
## References
Aldridge, I. (2013). *High-Frequency Trading: A Practical Guide to Algorithmic Strategies and Trading Systems*. 2nd ed. Hoboken, NJ: John Wiley & Sons.
Ang, A. (2014). *Asset Management: A Systematic Approach to Factor Investing*. New York: Oxford University Press.
Arms, R. W. (1989). *The Arms Index (TRIN): An Introduction to the Volume Analysis of Stock and Bond Markets*. Homewood, IL: Dow Jones-Irwin.
Asness, C. S., Moskowitz, T. J., & Pedersen, L. H. (2013). Value and momentum everywhere. *Journal of Finance*, 68(3), 929-985.
Barroso, P., & Santa-Clara, P. (2015). Momentum has its moments. *Journal of Financial Economics*, 116(1), 111-120.
Bollinger, J. (1992). *Bollinger on Bollinger Bands*. New York: McGraw-Hill.
Brock, W., Lakonishok, J., & LeBaron, B. (1992). Simple technical trading rules and the stochastic properties of stock returns. *Journal of Finance*, 47(5), 1731-1764.
Calmar, T. (1991). The Calmar ratio: A smoother tool. *Futures*, 20(1), 40.
Campbell, J. Y., Lo, A. W., & MacKinlay, A. C. (1997). *The Econometrics of Financial Markets*. Princeton, NJ: Princeton University Press.
Chekhlov, A., Uryasev, S., & Zabarankin, M. (2005). Drawdown measure in portfolio optimization. *International Journal of Theoretical and Applied Finance*, 8(1), 13-58.
Daniel, K., & Moskowitz, T. J. (2016). Momentum crashes. *Journal of Financial Economics*, 122(2), 221-247.
Fama, E. F., & French, K. R. (1996). Multifactor explanations of asset pricing anomalies. *Journal of Finance*, 51(1), 55-84.
Granville, J. E. (1963). *Granville's New Key to Stock Market Profits*. Englewood Cliffs, NJ: Prentice-Hall.
Guidolin, M. (2011). Markov switching models in empirical finance. In D. N. Drukker (Ed.), *Missing Data Methods: Time-Series Methods and Applications* (pp. 1-86). Bingley: Emerald Group Publishing.
Hamilton, J. D. (1989). A new approach to the economic analysis of nonstationary time series and the business cycle. *Econometrica*, 57(2), 357-384.
Jegadeesh, N., & Titman, S. (1993). Returns to buying winners and selling losers: Implications for stock market efficiency. *Journal of Finance*, 48(1), 65-91.
Kahneman, D., & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. *Econometrica*, 47(2), 263-291.
Kaufman, P. J. (1995). *Smarter Trading: Improving Performance in Changing Markets*. New York: McGraw-Hill.
Korajczyk, R. A., & Sadka, R. (2004). Are momentum profits robust to trading costs? *Journal of Finance*, 59(3), 1039-1082.
Leland, H. E. (1980). Who should buy portfolio insurance? *Journal of Finance*, 35(2), 581-594.
Lo, A. W., Mamaysky, H., & Wang, J. (2000). Foundations of technical analysis: Computational algorithms, statistical inference, and empirical implementation. *Journal of Finance*, 55(4), 1705-1765.
Markowitz, H. (1952). Portfolio selection. *Journal of Finance*, 7(1), 77-91.
Murphy, J. J. (1999). *Technical Analysis of the Financial Markets: A Comprehensive Guide to Trading Methods and Applications*. New York: New York Institute of Finance.
Prechter, R. R., & Frost, A. J. (1978). *Elliott Wave Principle: Key to Market Behavior*. Gainesville, GA: New Classics Library.
Pring, M. J. (2002). *Technical Analysis Explained: The Successful Investor's Guide to Spotting Investment Trends and Turning Points*. 4th ed. New York: McGraw-Hill.
Roncalli, T. (2013). *Introduction to Risk Parity and Budgeting*. Boca Raton, FL: CRC Press.
Shefrin, H., & Statman, M. (1985). The disposition to sell winners too early and ride losers too long: Theory and evidence. *Journal of Finance*, 40(3), 777-790.
Taleb, N. N. (2007). *The Black Swan: The Impact of the Highly Improbable*. New York: Random House.
Taylor, M. P., & Allen, H. (1992). The use of technical analysis in the foreign exchange market. *Journal of International Money and Finance*, 11(3), 304-314.
Treadway, A. B. (1969). On rational entrepreneurial behavior and the demand for investment. *Review of Economic Studies*, 36(2), 227-239.
Wilder, J. W. (1978). *New Concepts in Technical Trading Systems*. Greensboro, NC: Trend Research.
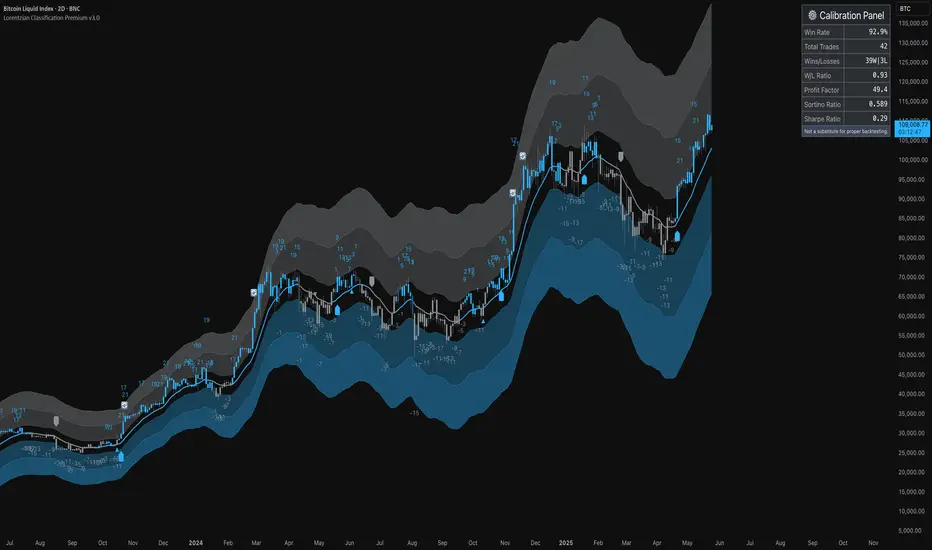
ML: Lorentzian Classification Premium█ OVERVIEW
Lorentzian Classification Premium represents the culmination of two years of collaborative development with over 1,000 beta testers from the TradingView community. Building upon the foundation of the open-source version, this premium edition introduces powerful enhancements that transform how machine-learning classification can be applied to market analysis.
The premium version maintains the core Lorentzian distance-based classification algorithm while expanding its capabilities through triple the feature dimensionality (up to 15 features), sophisticated mean-reversion detection, first-pullback identification, and a comprehensive signal taxonomy that goes far beyond simple buy/sell signals. Whether you're building automated trading systems, conducting deep market research, or integrating proprietary indicators into ML workflows, this tool provides the advanced edge needed for professional-grade analysis.
█ BACKGROUND
Lorentzian Classification analyzes market structures, especially those exhibiting non-linear distortions under stress, by employing advanced distance metrics like the Lorentzian metric, prominent in fields such as relativity theory. Where traditional indicators assume flat space, we embrace the curve. The heart of this approach is the Lorentzian distance metric—a sophisticated mathematical tool. This framework adeptly navigates the complex curves and distortions of market space, aiming to provide insights that traditional analysis might miss, especially during moments of extreme volatility. It analyzes historical data from a multi-dimensional feature space consisting of various technical indicators of your choosing. Where traditional approaches fail, Lorentzian space reveals the true geometry of market dynamics.
Neighborhoods in Different Geometries: In the above figure, the Lorentzian metric creates distinctive cross-patterns aligned with feature axes (RSI, CCI, ADX), capturing both local similarity and dimensional extremes. This unique geometry allows the algorithm to recognize similar market conditions that Euclidean spheres and Manhattan diamonds would miss entirely. In LC Premium, users can have up to 15 features -- you are not limited to 3-dimensions.
Among the thousands of distance metrics discovered by mathematicians, each perceives data through its own geometric lens. The Lorentzian metric stands apart with its unique ability to capture market behavior during volatile events.
█ COMMUNITY-DRIVEN EVOLUTION
It has been profoundly humbling over the past 2 years to witness this indicator's evolution through the collaborative efforts of our incredible community. This journey has been shaped by thousands of user suggestions and validated through real-world application.
A particularly amazing milestone was the development of a complete community-driven Python port, which meticulously matched even the most minute PineScript quirks. Building on this solid foundation, a new command-line interface (CLI) has opened up exciting possibilities for chart-specific parameter optimization:
Early insights from parameter optimization research: Through grid-search testing across thousands of parameter combinations, the analysis identifies which parameters have the biggest effects on performance and maps regions of stability across different market regimes. This reveals that optimal neighbor counts vary significantly based on market conditions—opening up incredible potential for timeframe-specific optimization.
This is just one of the insights gleaned so far from this ongoing investigation. The potential for chart-specific optimization for any given timeframe could transform how traders approach parameter selection.
Demand from power users for extra capabilities—while keeping the open-source version simple—sparked this Premium release. The open-source branch remains maintained, but the premium tier adds unique features for those who need an analytical edge and to leverage their own custom indicators as feature series for the algorithm.
█ KEY PREMIUM FEATURES
📈 First Pullback Detection System
Automatically identifies high-probability trend-continuation entries after initial momentum moves.
Detects when price retraces to optimal entry zones following breakouts or trend initiations.
Green/red triangle signals often fire before main classification arrows.
Dedicated alerts for both bullish and bearish pullback opportunities.
Based on veryfid's extensive research into pullback mechanics and market structure.
🔄 Dynamic Kernel Regression Envelope
Powerful, zero-setup confluence layer that immediately communicates trend shifts.
Dual-kernel system creates a visual envelope between trend estimates.
Color gradient dynamically represents prediction strength and market conviction.
Crossovers provide additional confirmation without cluttering your chart.
Professional visualization that rivals institutional-grade analysis tools.
✨ Massively Expanded Dimensionality: 10 Custom Sources, 5 Built-In Sources
Transform the indicator from 5 built-in standard to 15 total total features—triple the analytical power.
Integrate ANY TradingView indicator as a machine learning feature.
Built-in normalization ensures all indicators contribute equally regardless of scale.
Create theme-based systems: pure volume analysis, multi-timeframe momentum, or hybrid approaches.
📊 Tiered Mean Reversion Signals with Scalping Alerts
Regular (🔄) and Strong (⬇️/⬆️) mean reversion signals based on statistical extremes.
Opportunities often arise before candle close—perfect for scalping entries.
Visual markers appear at high-probability reversal zones.
Four specialized alert types: upward/downward for both regular and strong reversals.
Pre-optimized probability thresholds, no fine-tuning required.
📅 Daily Kernel Trend Filter
Instantly cleans up noisy intraday charts by aligning with higher timeframe trends.
Swing traders report immediate signal quality improvement.
Automatically deactivates on daily+ timeframes (intelligent context awareness).
Reduces counter-trend signals by up to 60% on lower timeframes.
Simple toggle—no complex multi-timeframe setup required.
📋 Professional Backtesting Stream (-6 to +6)
Multiple distinct signal types (including pullbacks, mean reversions, and kernel deviations) vs. basic binary (buy/sell) output for nuanced analysis.
Enables detailed walk-forward analysis and ML model training.
Compatible with external backtesting frameworks via numeric stream.
Rare precision for TradingView indicators—usually only found in institutional tools.
Perfect for quants building sophisticated strategy layers.
⚡ Performance Optimizations
Faster distance calculations through algorithmic improvements.
Reduced indicator load time (measured via Pine Profiler).
Handles 15 active features without timeouts—critical for multi-chart setups.
Optimized for live auto-trading bots requiring minimal latency.
🎨 Full Visual Customization & Accessibility
Complete color control for all visual elements.
Colorblind-safe default palette with customization options.
Dark mode optimization for extended trading sessions.
Professional appearance matching your trading workspace.
Accessibility features meeting modern UI standards.
🛠️ Advanced Training Modes
Downsampling mode for training on diverse market conditions; Down-sampling and remote-fractals for exotic pattern discovery.
Remote fractals option extends analysis to deep historical patterns.
Reset factor control for fine-tuning neighbor diversity; Reset-factor tuning to control neighbor diversity.
Appeals to systematic traders exploring exotic data approaches.
Prevents temporal clustering bias in model training.
█ HOW TO USE
Understanding the Approach (Core Concept):
Lorentzian Classification uses a k-Nearest Neighbors (k-NN) algorithm. It searches for historical price action "neighborhoods" similar to the current market state. Instead of a simple straight-line (Euclidean) distance, it primarily uses a Lorentzian distance metric, which can account for market "warping" or distortions often seen during high volatility or significant events. Each historical neighbor "votes" on what happened next in its context, and these votes aggregate into a classification score for the current bar.
Interpreting Bar Scores & Signals (Interpreting the Chart):
Bar Prediction Values: Numbers over each candle (e.g., ranging from -8 to +8 if Neighbors Count is 8) represent the aggregated vote from the nearest neighbors. Strong positive scores (e.g., +7, +8) indicate a strong bullish consensus among historical analogs. Strong negative scores (e.g., -7, -8) indicate a strong bearish consensus. Scores near zero suggest neutrality or conflicting signals from neighbors. The intensity of bar colors (if Use Confidence Gradient is on) often reflects these scores.
Main Arrows (Main Buy/Sell Labels): Large ▲/▼ labels are the primary entry signals generated when the overall classification (after filters) is bullish or bearish.
Pullback Triangles: Small green/red ▲/▼ identify potential trend continuation entries. These signals often appear after an initial price move and a subsequent minor retracement, suggesting the trend might resume. This is based on recognizing patterns where a brief counter-movement is followed by a continued advance in the initial trend direction.
Mean-Reversion Symbols: 🔄 (Regular Reversion) appears when price has crossed the average band of the Dynamic Kernel Regression Envelope. ⬇️/⬆️ (Strong Reversion) means price has crossed the far band of the envelope, indicating a more extreme deviation and potentially a stronger reversion opportunity.
Custom Mean Reversion Deviation Markers (Deviation Dots): If Enable Custom Mean Reversion Alerts is on, these dots appear when price deviates from the main kernel regression line by a user-defined ATR multiple, signaling a custom-defined reversion opportunity.
Kernel Regression Lines & Envelope: The Main Kernel Estimate (thicker line) is an adaptive moving average that smooths price and helps identify trend direction. Its color indicates the current trend bias. The Envelope (outer bands and a midline) creates a channel around price, and its interaction with price generates mean reversion signals.
Key Input Groups & Their Purpose:
🔧 GENERAL SETTINGS:
Reduce Price-Time Warping : Toggles the distance metric. When enabled, it reduces the characteristic "warping" effect of the default Lorentzian metric, making the distance calculation more Euclidean in nature. This may be suited for periods exhibiting less pronounced price-time distortions.
Source : Price data for calculations (default: close ).
Neighbors Count : The 'k' in k-NN – number of historical analogs considered.
Max Bars Back : How far back the indicator looks for historical patterns.
Show Exits / Use Dynamic Exits : Controls visibility and logic for exit signals.
Include Full History (Use Remote Fractals) : Allows model to pick "exotic" fractals from deep chart history.
Use Downsampling / Reset Factor : Advanced training parameters affecting neighbor selection.
Show Trade Stats / Use Worst Case Estimates : Displays a real-time performance table (for calibration only).
🎛️ DEFINE CUSTOM SOURCES (OPTIONAL):
Integrate up to 10 external data series (e.g., from other indicators) as features. Each can be optionally normalized. Load the external indicator on your chart first for it to appear in the dropdown.
🧠 FEATURE ENGINEERING:
Configure up to 15 features for the k-NN algorithm. Select type (RSI, WT, CCI, ADX, Custom Sources), parameters, and enable/disable. Start simple (3-5 features) and add complexity gradually. Normalize features with vastly different scales.
🖥️ DISPLAY SETTINGS:
Controls visibility of chart elements: bar colors, prediction values/labels, envelope, etc.
Align Signal with Current Bar : If true, pullback signals appear on the current bar (calculated on closed data). If false (default), they appear on the next bar.
Use ATR Offset : Positions bar prediction values using ATR for visibility.
🧮 FILTERS SETTINGS:
Refine raw classification signals: Volatility, Regime, ADX, EMA/SMA, and Daily Kernel filters.
🌀 KERNEL SETTINGS (Main Kernel):
Adjust parameters for the primary Nadaraya-Watson Kernel Regression line. Lookback Window , Relative Weighting , Regression Level , Lag control sensitivity and smoothness.
✉️ ENVELOPE SETTINGS (for Mean Reversion):
Configure the dynamic Kernel Regression Envelope. ATR Length , Near/Far ATR Factor define band width.
🎨 COLOR SETTINGS (Colors):
Customize colors for all visual elements; override every palette element.
General Approach to Using the Indicator (Suggested Workflow):
Load defaults and observe behavior: Familiarize yourself with the indicator's behavior.
Feature Engineering: Experiment with features, considering momentum, trend, and volatility. Add/replace features gradually.
Apply Filters: Refine signals according to your trading style.
Contextualize: Use kernels and envelope to understand broader trend and potential overbought/oversold areas.
Observe Signals: Pay attention to the interplay of main signals, pullbacks, and mean reversions. Watch interplay of main, pullback & mean-reversion signals.
Calibrate (Not Backtest): Use the "Trade Stats" table for real-time feedback on current settings. This is for calibration, *not a substitute for rigorous backtesting.*
Iterate & refine: Adjust settings, observe outcomes, and refine your approach.
█ ACKNOWLEDGMENTS
This premium version wouldn't exist without the invaluable contributions of:
veryfid for his groundbreaking ideas on unifying pullback detection with Lorentzian Classification, but most of all for always believing in and encouraging me and so many others. For being a mentor and, most importantly, a friend. We all miss you.
RikkiTavi for his help in creating the settings optimization framework and for other invaluable theoretical discussions.
The 1,000+ beta testers worldwide who provided continuous feedback over two years.
The Python porting team who created the foundation for advanced optimization; for the cross-language clone.
The broader TradingView community for making this one of the platform's most popular indicators.
█ FUTURE DEVELOPMENT
The Premium version will continue to evolve based on community feedback. Planned enhancements include:
Specialized exit model trained independently from entry signals (ML-based exit model).
Feature hub with pre-normalized, commonly requested indicators (Pre-normalized feature hub).
Better risk-management options (Enhanced risk-management options).
Fully automated settings optimization (Auto-settings optimization tool).
Script a pagamento
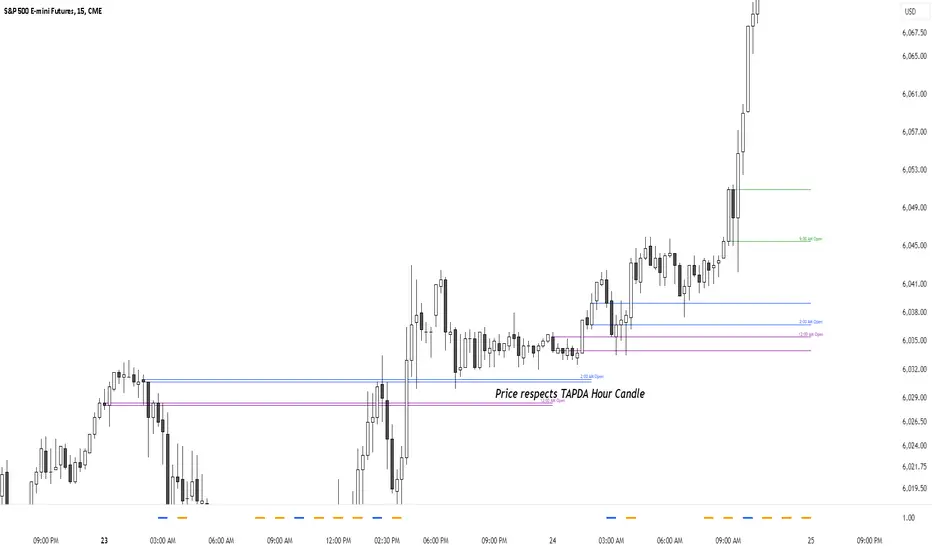
TAPDA Hourly Open Lines (Candle Body Box)-What is TAPDA?
TAPDA (Time and Price Displacement Analysis) is based on the belief that markets are driven by algorithms that respond to key time-based price levels, such as session opens. Traders who follow TAPDA track these levels to anticipate price movements, reversals, and breakouts, aligning their strategies with the patterns left by these underlying algorithms. By plotting lines at specific hourly opens, the indicator allows traders to visualize where the market may react, providing a structured way to trade alongside the algorithmic flow.
***************
**Sauce Alert** "TAPDA levels essentially act like algorithmic support and resistance" By plotting these hourly opens, the TAPDA Hourly Open Lines indicator helps traders track where algorithms might engage with the market.
***************
-How It Works:
The indicator draws a "candle body box" at selected hours, marking the open and close prices to highlight price ranges at significant times. This creates dynamic zones that reflect market sentiment and structure throughout the day. TAPDA levels are commonly respected by price, making them useful for identifying potential entry points, stop placements, and trend reversals.
-Key Features:
Customizable Hour Levels – Enable or disable specific times to fit your trading approach.
Color & Label Control – Assign unique colors and labels to each hour for better visualization.
Line Extension – Project lines for up to 24 hours into the future to track key levels.
Dynamic Cleanup – Old lines automatically delete to maintain chart clarity.
Manual Time Offset – Adjust for broker or server time zone differences.
-Current Development:
This indicator is still in development, with further updates planned to enhance functionality and customization. If you find this script helpful, feel free to copy the code and stay tuned for new features and improvements!
[Pandora] Error Function Treasure Trove - ERF/ERFI/Sigmoids+PRAISE:
At this time, I have to graciously thank the wonderful minds behind the new "Pine Profiler Mode" (PPM). Directly prior to this release, it allowed me to ascertain script performance even more. While I usually write mostly in highly optimized Pine code, PPM visually identified a few bottlenecks that would otherwise be hard to identify. Anyone who contributed to PPMs creation and testing before release... BRAVO!!! I commend all of those who assisted in it's state-of-the-art engineering and inception, well done!
BACKSTORY:
This script is specifically being released in defense of another member, an exceptionally unique PhD. It was brought to my attention that a script-mod-event occurred, regarding the publishing of a measly antiquated error function (ERF) calculation within his script. This sadly resulted in the now former member jumping ship after receiving unmannerly responses amidst his curious inquiries as to why his erf() was modded. To forbid rusty and rudimentary formulations because a mod-on-duty is temporally offended by a non-nefarious release of code, is in MY opinion an injustice to principles of perpetuating open-source code intended to benefit thousands to millions of community members. While Pine is the heart and soul of TV, the mathematical concepts contributed from the minds of members is the inspirational fuel of curiosity that powers it's pertinent reason to exist and evolve.
It is an indisputable fact that most members are not greatly skilled Pine Poets. Many members may be incapable of innovating robust function code in Pine, even if they have one or more PhDs. We ALL come from various disciplines of mathematical comprehension and education. Some mathematicians are not greatly skilled at coding, while some coders are not exceptional at math. So... what am I to do to attempt to resolve this circumstantial challenge??? Those who know me best are aware that I will always side with "the right side of history" in order to accomplish my primary self-defined missions I choose to accept. Serving as an algorithmic advocate, I felt compelled to intercede by compiling numerous error functions into elegant code of very high caliber that any and every TV member may choose to employ, so this ERROR never happens again.
After weeks of contemplation into algorithms I knew little about, I prioritized myself to resolve an unanticipated matter by creating advanced formulas of exquisitely crafted error functions refined to the best of my current abilities. My aversion for unresolved problems motivated me to eviscerate error function insufficiencies with many more rigid formulations beyond what is thought to exist. ERF needed a proper algorithmic exorcism anyways. In my furiosity, I contemplated an array of madMAXimum diplomatic demolition methods, choosing the chain saw massacre technique to slaughter dysfunctionalities I encountered on a battered ERF roadway. This resulted in prolific solutions that should assuredly endure the test of time. Poetically, as you will come to see, I am ripping the lid off of Pandora's box of error functions in this case to correct wrongs into a splendid bundle of rights for members.
INTENTION:
Error function (ERF) enthusiasts... PREPARE FOR GLORY!! The specific purpose of this script is to deprecate classic error functions with the creation of a fierce and formidable army of superior formulations, each having varying attributes of computational complexity with differing absolute error ranges in their results for multiple compute scenarios. This is NOT an indicator... It is intended to allow members to embark on endeavors to advance the profound knowledge base of this growing worldwide community of 60+ million inquisitive minds. For those of you who believe computational mathematics and statistics is near completion at its finest; I am here to inform you, this is ridiculous to ponder. We are no where near statistical excellence that can and will exist eventually. At this time, metaphorically speaking, we are merely scratching microns off of the surface of the skin of a statistical apple Isaac Newton once pondered.
THIS RELEASE:
Following weeks of pondering methodical experiments beyond the ordinary, I am liberating these wild notions of my error function explorations to the entire globe as copyleft code, not just Pine. This Pandora's basket of ERFs is being openly disclosed for the sake of the sanctity of mathematics, empirical science (not the garbage we are told by CONTROLocrats to blindly trust), revolutionary cutting edge engineering, cosmology, physics, information technology, artificial intelligence, and EVERY other mathematical branch of human knowledge being discovered over centuries. I do believe James Glaisher would favor my aims concerning ERF aspirations embracing the "Power of Pine".
The included functions are intended for TV members to use in any way they see fit. This is a gift to ALL members to foster future innovative excellence on this platform. Any attempt to moderate this code without notification of "self-evident clear and just cause" will be considered an irrevocable egregious action. The original foundational PURPOSE of establishing script moderation (I clearly remember) was primarily to maintain active vigilance over a growing community against intentional nefarious actions and/or behaviors in blatant disrespect to other author's works AND also thwart rampant copypasting bandit operations, all while accommodating balanced principles of fairness for an educational community cause via open source publishing that should support future algorithmic inventions well beyond my lifespan.
APPLICATIONS:
The related error functions are used in probability theory, statistics, and numerous and engineering scientific disciplines. Its key characteristics and applications are innumerable in computational realms. Its versatility and significance make it a fundamental tool in arenas of quantitative analysis and scientific research...
Probability Theory - Is widely used in probability theory to calculate probabilities and quantiles of the normal distribution.
Statistics - It's related to the Gaussian integral and plays a crucial role in statistics, especially in hypothesis testing and confidence interval calculations.
Physics - In physics, it arises in the study of diffusion equations, quantum mechanics, and heat conduction problems.
Engineering - Applications exist in engineering disciplines such as signal processing, control theory, and telecommunications.
Error Analysis - It's employed in error analysis and uncertainty quantification.
Numeric Approximations - Due to its lack of a closed-form expression, numerical methods are often employed to approximate erf/erfi().
AI, LLMs, & MACHINE LEARNING:
The error function (ERF) is indispensable to various AI applications, particularly due to its relation to Gaussian distributions and error analysis. It is used in Gaussian processes for regression and classification, probabilistic inference for Bayesian networks, soft margin computation in SVMs, neural networks involving Gaussian activation functions or noise, and clustering algorithms like Gaussian Mixture Models. Improved ERF approximations can enhance precision in these applications, reduce computational complexity, handle outliers and noise better, and improve optimization and convergence, possibly leading to more accurate, efficient, and robust AI systems.
BONUS ALGORITHMS:
While ERFs are versatile, its opposite also exists in the form of inverse error functions (ERFIs). I have also included a modified form of the inverse fisher transform along side MY sigmoid (sigmyod). I am uncertain what sigmyod() may be used for, but it's a culmination of my examinations deep into "sigmoid domains", something I am fascinated by. Whatever implications it may possess, I am unveiling it along with it's cousin functions. For curious minds, this quality of composition seen here is ideally what underlies what I would term "Pandora functionality" that empowers my Pandora indication. I go through hordes of formulations, testing, and inspection to find what appears to be the most beneficial logical/mathematical equation to apply...
SCRIPT OPERATION:
To showcase the characteristics and performance of my ERF/ERFI formulations, I devised a multi-modal script. By using bar_index , I generated a broad sequence of numeric values to input into the first ERF/ERFI parameter. These sequences allow you to inspect the contours of the error function's outputs for both ERF and ERFI. When combined with compute-intensive precision functions (CIPFs), the polynomial function output values can be subtracted from my CIPFs to obtain results of absolute error, displaying the accuracy of the many polynomial estimation functions I tuned in testing for Pine's float environment.
A host of numeric input settings are wildly adjustable to inspect values/curvatures across the range of numeric input sequences. Very large numbers, such as Divisor:100,000,100/Offset:200,000,000 for ERF modes or... Divisor:100,000,100/Offset:100,000,000 for ERFI modes, will display miniscule output values calculated from input values in close proximity to 0.0 for the various estimates, similar to a microscope. ERFI approximations very near in proximity to +/-1.0 will always yield large deviations of absolute error. Dragging/zooming your chart or using the Offset input will aid with visually clipping off those ERFI extremes where float precision functions cannot suffice.
NOTICE:
perf() and perfi() are intended for precision computation (as good as it basically gets) in a float environment. However, they are CPU intensive (especially perfi). I wouldn't recommend these being used in ANY Pine script unless it's an "absolute necessity" to do so to accomplish your goal. I only built them to obtain "absolute error curvatures" of the error functions for the polynomial approximations. These are visible in the accuracy modes in the indicator Settings.
Fusion: Machine Learning SuiteThe Fusion: Machine Learning Suite combines multiple technical analysis dimensions and harnesses the predictive power of machine learning, seamlessly integrating a diverse array of classic and novel indicators to deliver precision, adaptability, and innovation.
Features and Capabilities
Multidimensional Analysis: Fusion: MLS integrates various technical analysis dimensions to offer a more comprehensive perspective.
Machine Learning Integration: Utilizing ML algorithms, Fusion: MLS offers adaptability to market changes.
Custom Indicators: Including dimensions like "Moon Lander", "Cap Line" and "Z-Pack" the indicator expands the scope of traditional technical analysis methods.
Tailored Customization: With customization options, Fusion: MLS allows traders to configure the tool to suit their specific strategies and market focus.
In the following sections, we'll explore the features and settings of Fusion: MLS in detail, providing insights into how it can be utilized.
Major Features and Settings
The indicator consists of several core components and settings, each designed to provide specific functionalities and insights. Here's an in-depth look:
Machine Learning Component
Distance Classifier: A Strategic Approach to Market Analysis
In the world of trading and investment, the ability to classify and predict price movements is paramount. Machine learning offers powerful tools for this purpose.
The Fusion: MLS indicator among others incorporates an Approximate Nearest Neighbors (ANN)* algorithm, a machine learning classification technique, and allows the selection of various distance functions .
This flexibility sets Fusion: MLS apart from existing solutions. The available distance functions include:
Euclidean: Standard distance metric, commonly used as a default.
Chebyshev: Also known as maximum value distance.
Manhattan: Sum of absolute differences.
Minkowski: Generalized metric that includes Euclidean and Manhattan as special cases.
Mahalanobis: Measures distance between points in a correlated space.
Lorentzian: Known for its robustness to outliers and noise.
*For a deeper understanding of the Approximate Nearest Neighbors (ANN) algorithm, traders are encouraged to refer to the relevant articles that can be found in the public domain.
Alternative scoring system
Fusion: MLS also includes a custom scoring alternative based on directional price action.
"Combined: Directional" and "Alpha: Directional" scoring types represent our own directional change algorithm, simple yet effective in displaying trend direction changes early on. They are visualized by color changes when scoring becomes below or above zero.
Changes in scoring quickly reflect shifts in buyer and seller sentiment.
Traders may choose signals by Color Change in the indicator settings to get alerts when scoring color shifts, not waiting until the histogram crosses the zero level.
Application in Trading
Machine learning classification has become an integral part of modern trading, offering innovative ways to analyze and interpret financial data.
Many algorithmic trading systems leverage ML classification to automate trading decisions. By continuously learning from real-time data, these systems can adapt to changing market conditions and execute trades with increased efficiency and accuracy.
ML classification allows for the development of tailored trading strategies as traders can select specific algorithms, dimensions, and filters that align with their trading style, goals, and the particular market they are operating.
We have integrated ML classification with traditional trading tools, such as moving averages and technical indicators. This fusion creates a more robust analysis framework, combining the strengths of classical techniques with the adaptability of machine learning.
Whether used independently or in conjunction with other tools, ML classification represents a significant advancement in trading technology, opening new avenues for exploration, innovation, and success in the financial world.
ML: Weighting System
The Fusion: MLS indicator introduces a unique weighting system that allows traders to customize the influence of various technical indicators in the machine learning process. This feature is not only innovative but also provides a level of control and adaptability that sets it apart from other indicators.
Customizable Weights
The weighting system allows users to assign specific weights to different indicators such as Moon Lander, RSI, MACD, Money Flow, Bollinger Bands, Cap Line, Z-Pack, Squeeze Momentum*, and MA Crossover. These weights can be adjusted manually, providing the ability to emphasize or de-emphasize specific indicators based on the trader's strategy or market conditions.
*Note, we determined via testing that the popular "Squeeze" indicator can actually be well replicated by simply using inputs of 15 & 199 in the bedrock indicator - MACD ; while we employed the standard "Squeeze" formula (developed by J. Carter ) in Fusion: MLS, traders are hereby made aware of our research findings regarding such.
The weighting system's importance lies in its ability to provide a more nuanced and personalized analysis. By adjusting the weights of different indicators a trader focusing on momentum strategies might assign higher weights to the Squeeze Momentum and MA Crossover indicators, while a trader looking for volatility might emphasize RSI and Bollinger Bands.
The ability to customize weights adds a layer of complexity and adaptability that is rare in standard machine-learning indicators.
Custom Indicators: Moon Lander
The "Moon Lander" is not just a catchy name; it's a robust feature inspired by principles from aerospace engineering and offers a unique perspective on trading analysis. Here's a conceptual overview:
Fast EMA and Kalman Matrix
"Moon Lander" incorporates both a Fast Exponential Moving Average (EMA) and a Kalman Matrix in its design. These two elements are combined to create a histogram, providing a specific approach to data analysis.
The Kalman Matrix, or Kalman Filter, is a mathematical concept used for estimating variables that can be measured indirectly and contain noise or uncertainty. It's a standard tool in machine learning and control systems, known for its ability to provide optimal estimates based on observed data.
Kalman Filter: A Navigational Tool
The Kalman filter, an essential part of "Moon Lander," is a mathematical concept known for its applications in navigation and control systems used by NASA in the apollo program :
Guidance in Uncertainty: Just as the Kalman filter helped guide complex aerospace missions through uncertain paths, it assists traders in navigating the often unpredictable financial markets.
Filtering Noise: In trading, the Kalman filter serves to filter out market noise, allowing traders to focus on the underlying trends.
Predictive Capabilities: Its ability to predict future states makes it a valuable tool for forecasting market movements and trend directions.
Custom Indicators: Cap Line and Z-Pack
Fusion: MLS integrates our additional proprietary custom indicators that have been published on TradingView earlier:
Cap Line: Delve into the specific functionalities and applications of our proprietary "Cap Line" indicator in the published description on TradingView.
Z-Pack: Explore the analytical perspectives, focused on the z-score methodology, and custom "Z-Pack" indicator by reviewing the published description on TradingView.
Buy/Sell Signal Generation Algorithms
Fusion: MLS offers various options for generating buy/sell signals, tailored to different trading strategies and perspectives:
Fusion: Allows traders to select any number of dimensions to receive buy/sell signals from, offering customized signal generation.
ML: Utilizes the machine learning ANN distance for signal generation.
Color Change: Generates signals by selected scoring type color change.
Displayed Dimension, Alpha Dimension: Generate signals based on specific selected dimensions.
These algorithms provide flexibility in determining buy/sell signals, catering to different trading styles and market conditions.
Filters
Filters are used to refine and selectively include or exclude signals based on specific criteria. Rather than generating signals, these filters act as gatekeepers, ensuring that only the signals meeting certain conditions are considered. Here's an overview of the filters used:
Dynamic State Predictor (DSP)
The DSP employs the Kalman Matrix to evaluate existing signals by comparing the fast and slow-moving averages, both processed through the Kalman Matrix. Based on the relationship between these averages, the DSP may exclude specific signals, depending on whether they align with upward or downward trends.
Average Directional Index (ADX)
The ADX filter evaluates the strength of existing trends and filters out signals that do not meet the specified ADX threshold and length, focusing on significant market movements.
Feature Engineering: RSI
Applies a filter to the existing signals, clearing out those that do not meet the criteria for RSI overbought or oversold threshold condition.
Feature Engineering: MACD
Assesses existing signals to identify changes in the strength, direction, momentum, and duration of a trend, filtering out those that do not align with MACD trend direction.
The Visual Component
The machine learning component is an internal component. However, the indicator also offers an equally important and useful visual component. It is a graphical representation of the multiple technical analysis dimensions, that can be combined in various ways (where the name "Fusion" comes from), allowing traders to visualize the underlying data and its analysis.
Displayed Dimension: Visualization and Normalization
The Fusion: MLS indicator offers a "Displayed Dimension" feature that visualizes various dimensions as a histogram. These dimensions may include RSI, MAs, BBs, MACD, etc.
RSI Dimension on the image + ML signals
Normalization: Each dimension is normalized. If any dimension has extreme values, a Fisher transformation is applied to bring them within a reasonable range.
Combined Dimension: When selecting the "Combined" option , the normalized values of the selected dimensions are combined using techniques such as standardization, normalization, or winsorization. This flexibility enables tailored visualization and analysis.
Alpha Dimension: Enhancing Analysis
The "Alpha Dimension" feature allows traders to select an additional dimension alongside the Displayed Dimension. This facilitates a combined analysis, enhancing the depth of insights.
Theme Selection
Fusion: MLS offers various themes such as "Sailfish", "Iceberg", "Moon", "Perl", "Candy" and "Monochrome" Traders can select a theme that resonates with their preference, enhancing visual appeal. There is also a "Custom" theme available that allows the user to choose the colors of the theme.
Customizing Fusion: MLS for Various Markets and Strategies
Fusion: MLS is designed with customization in mind. Traders can tailor the indicator to suit various markets and trading strategies. Selecting specific dimensions allows it to align with individual trading goals.
Selecting Dimensions: Choose the dimensions that resonate with your trading approach, whether focusing on trend-following, momentum, or other strategies.
Adjusting Parameters: Fine-tune the parameters of each dimension, including custom ones like "Moon Lander," to suit specific market conditions.
Theme Customization: Select a theme that aligns with your visual preferences, enhancing your chart's readability and appeal.
Utilizing Research: Leverage the underlying algorithms and research, such as machine learning classification by ANN and the Kalman filter, to deepen your understanding and application of Fusion: MLS.
Alerts
The indicator includes an alerting system that notifies traders when new buy or sell signals are detected.
Disclaimer
The information provided herein is intended for informational purposes only and should not be construed as investment advice, endorsement, nor a recommendation to buy or sell any financial instruments. Fusion: MLS is a technical analysis tool, and like all tools, it should be used with caution and in conjunction with other forms of analysis.
Traders and investors are encouraged to consult with a licensed financial professional and conduct their own research before making any trading or investment decisions. Past performance of the Fusion: MLS indicator or any trading strategy does not guarantee future results, and all trading involves risk. Users of Fusion: MLS should understand the underlying algorithms and assumptions and consider their individual risk tolerance and investment goals when using this tool.
Machine Learning & Optimization Moving Average (Expo)█ An indicator that finds the best moving average
We all know that the market change in characteristics over time, volatility, volume, momentum, etc., keep changing. Therefore, traders fine-tune their indicators and strategies to fit the constantly changing market. Unfortunately, that means there is no "best" MA period that suits all these conditions. That is why we have developed this algorithm that self-adapts and finds the best MA period based on Machine Learning and Optimization calculations.
This indicator help traders and investors to use the best possible moving average period on the selected timeframe and asset and ensures that the period is updated even though the market characteristics change over time.
█ Self-optimizing moving average
There is no doubt that different markets and timeframes need different MA periods. Therefore, our algorithm optimizes the moving average period within the given parameter range and optimizes its value based on either performance, win rate, or the combined results. The moving average period updates automatically on the chart for you.
Traders can choose to use our Machine Learning Algorithm to optimize the MA values or can optimize only using the optimization algorithm.
Performance
If you select to optimize based on performance, the calculation returns the period with the highest gains.
Winrate
If you select to optimize based on win rate, the calculation returns the period that gives the best win rate.
Combined
If you select to optimize based on combined results, the calculations score the performance and win rate separately and choose the best period with the highest ranking in both aspects.
█ Finding the best moving average for any asset and timeframe
Traders can choose to find the best moving average based on price crossings.
█ Finding the best combination of moving averages for any asset and timeframe
Traders can choose to find the best crossing strategy, where the algorithm compares the 2 averages and returns the best fast and slow period.
█ Alerts
Traders can choose to be alerted when a new best moving average is found or when a moving average cross occurs.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Bogdan Ciocoiu - Code runnerDescription
The Code Runner is a hybrid indicator that leverages other pre-configured, integrated open-source algorithms to help traders spot regular and continuation divergences.
The Code Runner specialises in integrating some of the most popular oscillators well known for their accuracy when scalping using divergence strategies.
Uniqueness
The Code Runner stands out as a one-stop-shop pack of oscillator algorithms that traders can further customise to spot divergences.
The indicator's uniqueness stands from its capability to recast each algorithm to apply to the same scale. This feature is achieved by manually adjusting the outputs of each algorithm to fit on a scale between +100 and -100.
Another benefit of the Code Runner comes from its standardisation of outputs, mainly consisting of lines. Showing lines enables traders to draw potential regular and continuation divergences quickly.
The indicator has been pre-configured to support scalping at 1-5 minutes.
Open-source
The Code Runner uses the following open-source scripts and algorithms:
www.tradingview.com
www.tradingview.com
www.tradingview.com
www.tradingview.com
www.tradingview.com
www.tradingview.com
www.tradingview.com
www.tradingview.com
These algorithms are available in the public domain either in TradingView space or outside (given their popularity in the financial markets industry).

Adaptive Average Vortex Index [lastguru]As a longtime fan of ADX, looking at Vortex Indicator I often wondered, where is the third line. I have rarely seen that anybody is calculating it. So, here it is: Average Vortex Index - an ADX calculated from Vortex Indicator. I interpret it similarly to the ADX indicator: higher values show stronger trend. If you discover other interpretation or have suggestions, comments are welcome.
Both VI+ and VI- lines are also drawn. As I use adaptive length calculation in my other scripts (based on the libraries I've developed and published), I have also included the possibility to have an adaptive length here, so if you hate the idea of calculating ADX from VI, you can disable that line and just look at the adaptive Vortex Indicator.
Note that as with all my oscillators, all the lines here are renormalized to -1..1 range unlike the original Vortex Indicator computation. To do that for VI+ and VI- lines, I subtract 1 from their values. It does not change the shape or the amplitude of the lines.
Adaptation algorithms are roughly subdivided in two categories: classic Length Adaptations and Cycle Estimators (they are also implemented in separate libraries), all are selected in Adaptation dropdown. Length Adaptation used in the Adaptive Moving Averages and the Adaptive Oscillators try to follow price movements and accelerate/decelerate accordingly (usually quite rapidly with a huge range). Cycle Estimators, on the other hand, try to measure the cycle period of the current market, which does not reflect price movement or the rate of change (the rate of change may also differ depending on the cycle phase, but the cycle period itself usually changes slowly).
VIDYA - based on VIDYA algorithm. The period oscillates from the Lower Bound up (slow)
VIDYA-RS - based on Vitali Apirine's modification of VIDYA algorithm (he calls it Relative Strength Moving Average). The period oscillates from the Upper Bound down (fast)
Kaufman Efficiency Scaling - based on Efficiency Ratio calculation originally used in KAMA
Fractal Adaptation - based on FRAMA by John F. Ehlers
MESA MAMA Cycle - based on MESA Adaptive Moving Average by John F. Ehlers
Pearson Autocorrelation* - based on Pearson Autocorrelation Periodogram by John F. Ehlers
DFT Cycle* - based on Discrete Fourier Transform Spectrum estimator by John F. Ehlers
Phase Accumulation* - based on Dominant Cycle from Phase Accumulation by John F. Ehlers
Length Adaptation usually take two parameters: Bound From (lower bound) and To (upper bound). These are the limits for Adaptation values. Note that the Cycle Estimators marked with asterisks(*) are very computationally intensive, so the bounds should not be set much higher than 50, otherwise you may receive a timeout error (also, it does not seem to be a useful thing to do, but you may correct me if I'm wrong).
The Cycle Estimators marked with asterisks(*) also have 3 checkboxes: HP (Highpass Filter), SS (Super Smoother) and HW (Hann Window). These enable or disable their internal prefilters, which are recommended by their author - John F. Ehlers . I do not know, which combination works best, so you can experiment.
If no Adaptation is selected ( None option), you can set Length directly. If an Adaptation is selected, then Cycle multiplier can be set.
The oscillator also has the option to configure the internal smoothing function with Window setting. By default, RMA is used (like in ADX calculation). Fast Default option is using half the length for smoothing. Triangle , Hamming and Hann Window algorithms are some better smoothers suggested by John F. Ehlers.
After the oscillator a Moving Average can be applied. The following Moving Averages are included: SMA , RMA, EMA , HMA , VWMA , 2-pole Super Smoother, 3-pole Super Smoother, Filt11, Triangle Window, Hamming Window, Hann Window, Lowpass, DSSS.
Postfilter options are applied last:
Stochastic - Stochastic
Super Smooth Stochastic - Super Smooth Stochastic (part of MESA Stochastic ) by John F. Ehlers
Inverse Fisher Transform - Inverse Fisher Transform
Noise Elimination Technology - a simplified Kendall correlation algorithm "Noise Elimination Technology" by John F. Ehlers
Momentum - momentum (derivative)
Except for Inverse Fisher Transform , all Postfilter algorithms can have Length parameter. If it is not specified (set to 0), then the calculated Slow MA Length is used. If Filter/MA Length is less than 2 or Postfilter Length is less than 1, they are calculated as a multiplier of the calculated oscillator length.
More information on the algorithms is given in the code for the libraries used. I am also very grateful to other TradingView community members (they are also mentioned in the library code) without whom this script would not have been possible.

MTF Accumulation/Distribution RasterChart (Spectrogram/HeatMap)As my first published indicator for year 2020, I present my revolutionary "MTF Accumulation/Distribution RasterChart" employing PSv4.0. This is probably a world's first all-in-one multi-timeframe, multi-algorithm heatmap indicator with multiple color schemes. I decided to release this multicator now, because it has been a year long journey for me to develop spectrogram technology with abilities John Ehlers didn't include with his original heatmaps. I would like to personally thank Dr. John Ehlers for inspiring me to ponder into the realm of heatmap technology and all it has to offer. Thank you! You're a divine inspiration to the algorithmic trading community and forever shall be.
Each of the algorithms use "volume" and "price" data in their calculations to provide a unique spectrogram for either algorithm chosen, hence the accumulation/distribution attributed to the title of this indicator. The MTF capabilities include seconds, minutes, and days. If the time frame settings are shorter in time than the current sampling interval, a warning will be appropriately displayed. Also, when volume data is not applicable to an asset, the indicator will become completely red. I included so many color scheming techniques I couldn't demonstrate all of them above. This indicator has what I would term as "predator" vision. For those of you who have seen these movies, you will understand what I have built.
The use of this indicator is just like any of my other RasterCharts or heatmap indicators found on the internet, except it has much more versatility. This indicator has so many uses, I really haven't discovered all of it's characteristics yet. Anyhow, this is one of my most beautiful indicators I have created so far, but I feel there is still more room for enhancements with a possibility of more sibling algorithms to incorporate later. Lastly, I couldn't have done this without the computing power/wizardry provided by ALL Tradingview staff. They deserve a HUGE and proper, THANK YOU!!! Happy New Year 2020 everyone...
Features List Includes:
MTF controls for seconds, minutes, and days
Multiple volume weighted algorithms to choose from
Gain control for algorithm #1
Adjustable horizontal rule to differentiate between more reactive aspects of turning point fluctuations in the lower portion of the chart (visible above)
Adjustable heatmap brightness control
Visual color scheme techniques (a few of many are displayed above)
Color inversion control
"NO VOLUME" detection (indicator becomes red)
This is not a freely available indicator, FYI. To witness my Pine poetry in action, properly negotiated requests for unlimited access, per indicator, may ONLY be obtained by direct contact with me using TV's "Private Chats" or by "Message" hidden in my member name above. The comments section below is solely just for commenting and other remarks, ideas, compliments, etc... regarding only this indicator, not others. When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members, I may implement more ideas when they present themselves as worthy additions. As always, "Like" it if you simply just like it with a proper thumbs up, and also return to my scripts list occasionally for additional postings. Have a profitable future everyone!
Curvature Tensor Pivots - HIVECurvature Tensor Pivots - HIVE
I. CORE CONCEPT & ORIGINALITY
Curvature Tensor Pivots - HIVE is an advanced, multi-dimensional pivot detection system that combines differential geometry, reinforcement learning, and statistical physics to identify high-probability reversal zones before they fully form. Unlike traditional pivot indicators that rely on simple price comparisons or lagging moving averages, this system models price action as a smooth curve in geometric space and calculates its mathematical curvature (how sharply the price trajectory is "bending") to detect pivots with scientific precision.
What Makes This Original:
Differential Geometry Engine: The script calculates first and second derivatives of price using Kalman-filtered trajectory analysis, then computes true mathematical curvature (κ) using the classical formula: κ = |y''| / (1 + y'²)^(3/2). This approach treats price as a physical phenomenon rather than discrete data points.
Ghost Vertex Prediction: A proprietary algorithm that detects pivots 1-3 bars BEFORE they complete by identifying when velocity approaches zero while acceleration is high—this is the mathematical definition of a turning point.
Multi-Armed Bandit AI: Four distinct pivot detection strategies (Fast, Balanced, Strict, Tensor) run simultaneously in shadow portfolios. A Thompson Sampling reinforcement learning algorithm continuously evaluates which strategy performs best in current market conditions and automatically selects it.
Hive Consensus System: When 3 or 4 of the parallel strategies agree on the same price zone, the system generates "confluence zones"—areas of institutional-grade probability.
Dynamic Volatility Scaling (DVS): All parameters auto-adjust based on current ATR relative to historical average, making the indicator adaptive across all timeframes and instruments without manual re-optimization.
II. HOW THE COMPONENTS WORK TOGETHER
This is NOT a simple mashup —each subsystem feeds data into the others in a closed-loop learning architecture:
The Processing Pipeline:
Step 1: Geometric Foundation
Raw price is normalized against a 50-period SMA to create a trajectory baseline
A Zero-Lag EMA smooths the trajectory while preserving edge response
Kalman filter removes noise while maintaining signal integrity
Step 2: Calculus Layer
First derivative (y') measures velocity of price movement
Second derivative (y'') measures acceleration (rate of velocity change)
Curvature (κ) is calculated from these derivatives, representing how sharply price is turning
Step 3: Statistical Validation
Z-Score measures how many standard deviations current price deviates from the Kalman-filtered "true price"
Only pivots with Z-Score > threshold (default 1.2) are considered statistically significant
This filters out noise and micro-fluctuations
Step 4: Tensor Construction
Curvature is combined with volatility (ATR-based) and momentum (ROC-based) to create a multidimensional "tensor score"
This tensor represents the geometric stress in the price field
High tensor magnitude = high probability of structural failure (reversal)
Step 5: AI Decision Layer
All 4 bandit strategies evaluate current conditions using different sensitivity thresholds
Each strategy maintains a virtual portfolio that trades its signals in real-time
Thompson Sampling algorithm updates Bayesian priors (alpha/beta distributions) based on each strategy's Sharpe ratio, win rate, and drawdown
The highest-performing strategy's signals are displayed to the user
Step 6: Confluence Aggregation
When multiple strategies agree on the same price zone, that zone is highlighted as a confluence area. These represent "hive mind" consensus—the strongest setups
Why This Integration Matters:
Traditional indicators either detect pivots too late (lagging) or generate too many false signals (noisy). By requiring geometric confirmation (curvature), statistical significance (Z-Score), multi-strategy agreement (hive voting), and performance validation (RL feedback) , this system achieves institutional-grade precision. The reinforcement learning layer ensures the system adapts as market regimes change, rather than degrading over time like static algorithms.
III. DETAILED METHODOLOGY
A. Curvature Calculation (Differential Geometry)
The system models price as a parametric curve where:
x-axis = time (bar index)
y-axis = normalized price
The curvature at any point represents how quickly the direction of the tangent line is changing. High curvature = sharp turn = potential pivot.
Implementation:
Lookback window (default 8 bars) defines the local curve segment
Smoothing (default 5 bars) applies adaptive EMA to reduce tick noise
Curvature is normalized to 0-1 scale using local statistical bounds (mean ± 2 standard deviations)
B. Ghost Vertex (Predictive Pivot Detection)
Classical pivot detection waits for price to form a swing high/low and confirm. Ghost Vertex uses calculus to predict the turning point:
Conditions for Ghost Pivot:
Velocity (y') ≈ 0 (price rate of change approaching zero)
Acceleration (y'') ≠ 0 (change is decelerating/accelerating)
Z-Score > threshold (statistically abnormal position)
This allows detection 1-3 bars before the actual high/low prints, providing an early entry edge.
C. Multi-Armed Bandit Reinforcement Learning
The system runs 4 parallel "bandits" (agents), each with different detection sensitivity:
Bandit Strategies:
Fast: Low curvature threshold (0.1), low Z-Score requirement (1.0) → High frequency, more signals
Balanced: Standard thresholds (0.2 curvature, 1.5 Z-Score) → Moderate frequency
Strict: High thresholds (0.4 curvature, 2.0 Z-Score) → Low frequency, high conviction
Tensor: Requires tensor magnitude > 0.5 → Geometric-weighted detection
Learning Algorithm (Thompson Sampling):
Each bandit maintains a Beta distribution with parameters (α, β)
After each trade outcome, α is incremented for wins, β for losses
Selection probability is proportional to sampled success rate from the distribution
This naturally balances exploration (trying underperformed strategies) vs exploitation (using best strategy)
Performance Metrics Tracked:
Equity curve for each shadow portfolio
Win rate percentage
Sharpe ratio (risk-adjusted returns)
Maximum drawdown
Total trades executed
The system displays all metrics in real-time on the dashboard so users can see which strategy is currently "winning."
D. Dynamic Volatility Scaling (DVS)
Markets cycle between high volatility (trending, news-driven) and low volatility (ranging, quiet). Static parameters fail when regime changes.
DVS Solution:
Measures current ATR(30) / close as normalized volatility
Compares to 100-bar SMA of normalized volatility
Ratio > 1 = high volatility → lengthen lookbacks, raise thresholds (prevent noise)
Ratio < 1 = low volatility → shorten lookbacks, lower thresholds (maintain sensitivity)
This single feature is why the indicator works on 1-minute crypto charts AND daily stock charts without parameter changes.
E. Confluence Zone Detection
The script divides the recent price range (200 bars) into 200 discrete zones. On each bar:
Each of the 4 bandits votes on potential pivot zones
Votes accumulate in a histogram array
Zones with ≥ 3 votes (75% agreement) are drawn as colored boxes
Red boxes = resistance confluence, Green boxes = support confluence
These zones act as magnet levels where price often returns multiple times.
IV. HOW TO USE THIS INDICATOR
For Scalpers (1m - 5m timeframes):
Settings: Use "Aggressive" or "Adaptive" pivot mode, Curvature Window 5-8, Min Pivot Strength 50-60
Entry Signal: Triangle marker appears (🔺 for longs, 🔻 for shorts)
Confirmation: Check that Hive Sentiment on dashboard agrees (3+ votes)
Stop Loss: Use the dotted volatility-adjusted target line in reverse (if pivot is at 100 with target at 110, stop is ~95)
Take Profit: Use the projected target line (default 3× ATR)
Advanced: Wait for confluence zone formation, then enter on retest of the zone
For Day Traders (15m - 1H timeframes):
Settings: Use "Adaptive" mode (default settings work well)
Entry Signal: Pivot marker + Hive Consensus alert
Confirmation: Check dashboard—ensure selected bandit has Sharpe > 1.5 and Win% > 55%
Filter: Only take pivots with Pivot Strength > 70 (shown in dashboard)
Risk Management: Monitor the Live Position Tracker—if your selected bandit is holding a position, consider that as market structure context
Exit: Either use target lines OR exit when opposite pivot appears
For Swing Traders (4H - Daily timeframes):
Settings: Use "Conservative" mode, Curvature Window 12-20, Min Bars Between Pivots 15-30
Focus on Confluence: Only trade when 4/4 bandits agree (unanimous hive consensus)
Entry: Set limit orders at confluence zones rather than market orders at pivot signals
Confirmation: Look for breakout diamonds (◆) after pivot—these signal momentum continuation
Risk Management: Use wider stops (base stop loss % = 3-5%)
Dashboard Interpretation:
Top Section (Real-Time Metrics):
κ (Curv): Current curvature. >0.6 = active pivot forming
Tensor: Geometric stress. Positive = bullish bias, Negative = bearish bias
Z-Score: Statistical deviation. >2.0 or <-2.0 = extreme outlier (strong signal)
Bandit Performance Table:
α/β: Bayesian parameters. Higher α = more wins in history
Win%: Self-explanatory. >60% is excellent
Sharpe: Risk-adjusted returns. >2.0 is institutional-grade
Status: Shows which strategy is currently selected
Live Position Tracker:
Shows if the selected bandit's shadow portfolio is currently holding a position
Displays entry price and real-time P&L
Use this as "what the AI would do" confirmation
Hive Sentiment:
Shows vote distribution across all 4 bandits
"BULLISH" with 3+ green votes = high-conviction long setup
"BEARISH" with 3+ red votes = high-conviction short setup
Alert Setup:
The script includes 6 alert conditions:
"AI High Pivot" = Selected bandit signals short
"AI Low Pivot" = Selected bandit signals long
"Hive Consensus BUY" = 3+ bandits agree on long
"Hive Consensus SELL" = 3+ bandits agree on short
"Breakout Up" = Resistance breakout (continuation long)
"Breakdown Down" = Support breakdown (continuation short)
Recommended Alert Strategy:
Set "Hive Consensus" alerts for high-conviction setups
Use "AI Pivot" alerts for active monitoring during your trading session
Use breakout alerts for momentum/trend-following entries
V. PARAMETER OPTIMIZATION GUIDE
Core Geometry Parameters:
Curvature Window (default 8):
Lower (3-5): Detects micro-structure, best for scalping volatile pairs (crypto, forex majors)
Higher (12-20): Detects macro-structure, best for swing trading stocks/indices
Rule of thumb: Set to ~0.5% of your typical trade duration in bars
Curvature Smoothing (default 5):
Increase if you see too many false pivots (noisy instrument)
Decrease if pivots lag (missing entries by 2-3 bars)
Inflection Threshold (default 0.20):
This is advanced. Lower = more inflection zones highlighted
Useful for identifying order blocks and liquidity voids
Most users can leave default
Pivot Detection Parameters:
Pivot Sensitivity Mode:
Aggressive: Use in low-volatility range-bound markets
Normal: General purpose
Adaptive: Recommended—auto-adjusts via DVS
Conservative: Use in choppy, whipsaw conditions or for swing trading
Min Bars Between Pivots (default 8):
THIS IS CRITICAL for visual clarity
If chart looks cluttered, increase to 12-15
If missing pivots, decrease to 5-6
Match to your timeframe: 1m charts use 3-5, Daily charts use 20+
Min Z-Score (default 1.2):
Statistical filter. Higher = fewer but stronger signals
During news events (NFP, FOMC), increase to 2.0+
In calm markets, 1.0 works well
Min Pivot Strength (default 60):
Composite quality score (0-100)
80+ = institutional-grade pivots only
50-70 = balanced
Below 50 = will show weak setups (not recommended)
RL & DVS Parameters:
Enable DVS (default ON):
Leave enabled unless you want to manually tune for a specific market condition
This is the "secret sauce" for cross-timeframe performance
DVS Sensitivity (default 1.0):
Increase to 1.5-2.0 for extremely volatile instruments (meme stocks, altcoins)
Decrease to 0.5-0.7 for stable instruments (utilities, bonds)
RL Algorithm (default Thompson Sampling):
Thompson Sampling: Best for non-stationary markets (recommended)
UCB1: Best for stable, mean-reverting markets
Epsilon-Greedy: For testing only
Contextual: Advanced—uses market regime as context
Risk Parameters:
Base Stop Loss % (default 2.0):
Set to 1.5-2× your instrument's average ATR as a percentage
Example: If SPY ATR = $3 and price = $450, ATR% = 0.67%, so use 1.5-2.0%
Base Take Profit % (default 4.0):
Aim for 2:1 reward/risk ratio minimum
For mean-reversion strategies, use 1.5-2.0%
For trend-following, use 3-5%
VI. UNDERSTANDING THE UNDERLYING CONCEPTS
Why Differential Geometry?
Traditional technical analysis treats price as discrete data points. Differential geometry models price as a continuous manifold —a smooth surface that can be analyzed using calculus. This allows us to ask: "At what rate is the trend changing?" rather than just "Is price going up or down?"
The curvature metric captures something fundamental: inflection points in market psychology . When buyers exhaust and sellers take over (or vice versa), the price trajectory must curve. By measuring this curvature mathematically, we detect these psychological shifts with precision.
Why Reinforcement Learning?
Markets are non-stationary —statistical properties change over time. A strategy that works in Q1 may fail in Q3. Traditional indicators have fixed parameters and degrade over time.
The multi-armed bandit framework solves this by:
Running multiple strategies in parallel (diversification)
Continuously measuring performance (feedback loop)
Automatically shifting capital to what's working (adaptation)
This is how professional hedge funds operate—they don't use one strategy, they use ensembles with dynamic allocation.
Why Kalman Filtering?
Raw price contains two components: signal (true movement) and noise (random fluctuations). Kalman filters are the gold standard in aerospace and robotics for extracting signal from noisy sensors.
By applying this to price data, we get a "clean" trajectory to measure curvature against. This prevents false pivots from bid-ask bounce or single-print anomalies.
Why Z-Score Validation?
Not all high-curvature points are tradeable. A sharp turn in a ranging market might just be noise. Z-Score ensures that pivots occur at statistically abnormal price levels —places where price has deviated significantly from its Kalman-filtered "fair value."
This filters out 70-80% of false signals while preserving true reversal points.
VII. COMMON USE CASES & STRATEGIES
Strategy 1: Confluence Zone Reversal Trading
Wait for confluence zone to form (red or green box)
Wait for price to approach zone
Enter when pivot marker appears WITHIN the confluence zone
Stop: Beyond the zone
Target: Opposite confluence zone or 3× ATR
Strategy 2: Hive Consensus Scalping
Set alert for "Hive Consensus BUY/SELL"
When alert fires, check dashboard—ensure 3-4 votes
Enter immediately (market order or 1-tick limit)
Stop: Tight, 1-1.5× ATR
Target: 2× ATR or opposite pivot signal
Strategy 3: Bandit-Following Swing Trading
On Daily timeframe, monitor which bandit has best Sharpe ratio over 30+ days
Take ONLY that bandit's signals (ignore others)
Enter on pivot, hold until opposite pivot or target line
Position size based on bandit's current win rate (higher win% = larger position)
Strategy 4: Breakout Confirmation
Identify key support/resistance level manually
Wait for pivot to form AT that level
If price breaks level and diamond breakout marker appears, enter in breakout direction
This combines support/resistance with geometric confirmation
Strategy 5: Inflection Zone Limit Orders
Enable "Show Inflection Zones"
Place limit buy orders at bottom of purple zones
Place limit sell orders at top of purple zones
These zones represent structural change points where price often pauses
VIII. WHAT THIS INDICATOR DOES NOT DO
To set proper expectations:
This is NOT:
A "holy grail" with 100% win rate
A strategy that works without risk management
A replacement for understanding market fundamentals
A signal copier (you must interpret context)
This DOES NOT:
Predict black swan events
Account for fundamental news (you must avoid trading during major news if not experienced)
Work well in extremely low liquidity conditions (penny stocks, microcap crypto)
Generate signals during consolidation (by design—prevents whipsaw)
Best Performance:
Liquid instruments (SPY, ES, NQ, EUR/USD, BTC/USD, etc.)
Clear trend or range conditions (struggles in choppy transition periods)
Timeframes 5m and above (1m can work but requires experience)
IX. PERFORMANCE EXPECTATIONS
Based on shadow portfolio backtesting across multiple instruments:
Conservative Mode:
Signal frequency: 2-5 per week (Daily charts)
Expected win rate: 60-70%
Average RRR: 2.5:1
Adaptive Mode:
Signal frequency: 5-15 per day (15m charts)
Expected win rate: 55-65%
Average RRR: 2:1
Aggressive Mode:
Signal frequency: 20-40 per day (5m charts)
Expected win rate: 50-60%
Average RRR: 1.5:1
Note: These are statistical expectations. Individual results depend on execution, risk management, and market conditions.
X. PRIVACY & INVITE-ONLY NATURE
This script is invite-only to:
Maintain signal quality (prevent market impact from mass adoption)
Provide dedicated support to users
Continuously improve the algorithm based on user feedback
Ensure users understand the complexity before deploying real capital
The script is closed-source to protect proprietary research in:
Ghost Vertex prediction mathematics
Tensor construction methodology
Bandit reward function design
DVS scaling algorithms
XI. FINAL RECOMMENDATIONS
Before Trading Live:
Paper trade for minimum 2 weeks to understand signal timing
Start with ONE timeframe and master it before adding others
Monitor the dashboard —if selected bandit Sharpe drops below 1.0, reduce size
Use confluence and hive consensus for highest-quality setups
Respect the Min Bars Between Pivots setting —this prevents overtrading
Risk Management Rules:
Never risk more than 1-2% of account per trade
If 3 consecutive losses occur, stop trading and review (possible regime change)
Use the shadow portfolio as a guide—if ALL bandits are losing, market is in transition
Combine with other analysis (order flow, volume profile) for best results
Continuous Learning:
The RL system improves over time, but only if you:
Keep the indicator running (it learns from bar data)
Don't constantly change parameters (confuses the learning)
Let it accumulate at least 50 samples before judging performance
Review the dashboard weekly to see which bandits are adapting
CONCLUSION
Curvature Tensor Pivots - HIVE represents a fusion of advanced mathematics, machine learning, and practical trading experience. It is designed for serious traders who want institutional-grade tools and understand that edge comes from superior methodology, not magic formulas.
The system's strength lies in its adaptive intelligence —it doesn't just detect pivots, it learns which detection method works best right now, in this market, under these conditions. The hive consensus mechanism provides confidence, the geometric foundation provides precision, and the reinforcement learning provides evolution.
Use it wisely, manage risk properly, and let the mathematics work for you.
Disclaimer: This indicator is a tool for analysis and does not constitute financial advice. Past performance of shadow portfolios does not guarantee future results. Trading involves substantial risk of loss. Always perform your own due diligence and never trade with capital you cannot afford to lose.
Taking you to school. — Dskyz, Trade with insight. Trade with anticipation.

MTF K-Means Price Regimes [matteovesperi] ⚠️ The preview uses a custom example to identify support/resistance zones. due to the fact that this identifier clusterizes, this is possible. this example was set up "in a hurry", therefore it has a possible inaccuracy. When setting up the indicator, it is extremely important to select the correct parameters and double-check them on the selected history.
📊 OVERVIEW
Purpose
MTF K-Means Price Regimes is a TradingView indicator that automatically identifies and classifies the current market regime based on the K-Means machine learning algorithm. The indicator uses data from a higher timeframe (Multi-TimeFrame, MTF) to build stable classification and applies it to the working timeframe in real-time.
Key Features
✅ Automatic market regime detection — the algorithm finds clusters of similar market conditions
✅ Multi-timeframe (MTF) — clustering on higher TF, application on lower TF
✅ Adaptive — model recalculates when a new HTF bar appears with a rolling window
✅ Non-Repainting — classification is performed only on closed bars
✅ Visualization — bar coloring + information panel with cluster characteristics
✅ Flexible settings — from 2 to 10 clusters, customizable feature periods, HTF selection
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
🔬 TECHNICAL DETAILS
K-Means Clustering Algorithm
What is K-Means?
K-Means is one of the most popular clustering algorithms (unsupervised machine learning). It divides a dataset into K groups (clusters) so that similar elements are within each cluster, and different elements are between clusters.
Algorithm objective:
Minimize within-cluster variance (sum of squared distances from points to their cluster center).
How Does K-Means Work in Our Indicator?
Step 1: Data Collection
The indicator accumulates history from the higher timeframe (HTF):
RSI (Relative Strength Index) — overbought/oversold indicator
ATR% (Average True Range as % of price) — volatility indicator
ΔP% (Price Change in %) — trend strength and direction indicator
By default, 200 HTF bars are accumulated (clusterLookback parameter).
Step 2: Creating Feature Vectors
Each HTF bar is described by a three-dimensional vector:
Vector =
Step 3: Normalization (Z-Score)
All features are normalized to bring them to a common scale:
Normalized_Value = (Value - Mean) / StdDev
This is critically important, as RSI is in the range 0-100, while ATR% and ΔP% have different scales. Without normalization, one feature would dominate over others.
Step 4: K-Means++ Centroid Initialization
Instead of random selection of K initial centers, an improved K-Means++ method is used:
First centroid is randomly selected from the data
Each subsequent centroid is selected with probability proportional to the square of the distance to the nearest already selected centroid
This ensures better initial centroid distribution and faster convergence
Step 5: Iterative Optimization (Lloyd's Algorithm)
Repeat until convergence (or maxIterations):
1. Assignment step:
For each point find the nearest centroid and assign it to this cluster
2. Update step:
Recalculate centroids as the average of all points in each cluster
3. Convergence check:
If centroids shifted less than 0.001 → STOP
Euclidean distance in 3D space is used:
Distance = sqrt((RSI1 - RSI2)² + (ATR1 - ATR2)² + (ΔP1 - ΔP2)²)
Step 6: Adaptive Update
With each new HTF bar:
The oldest bar is removed from history (rolling window method)
New bar is added to history
K-Means algorithm is executed again on updated data
Model remains relevant for current market conditions
Real-Time Classification
After building the model (clusters + centroids), the indicator works in classification mode:
On each closed bar of the current timeframe, RSI, ATR%, ΔP% are calculated
Feature vector is normalized using HTF statistics (Mean/StdDev)
Distance to all K centroids is calculated
Bar is assigned to the cluster with minimum distance
Bar is colored with the corresponding cluster color
Important: Classification occurs only on a closed bar (barstate.isconfirmed), which guarantees no repainting .
Data Architecture
Persistent variables (var):
├── featureVectors - Normalized HTF feature vectors
├── centroids - Cluster center coordinates (K * 3 values)
├── assignments - Assignment of each HTF bar to a cluster
├── htfRsiHistory - History of RSI values from HTF
├── htfAtrHistory - History of ATR values from HTF
├── htfPcHistory - History of price changes from HTF
├── htfCloseHistory - History of close prices from HTF
├── htfRsiMean, htfRsiStd - Statistics for RSI normalization
├── htfAtrMean, htfAtrStd - Statistics for ATR normalization
├── htfPcMean, htfPcStd - Statistics for Price Change normalization
├── isCalculated - Model readiness flag
└── currentCluster - Current active cluster
All arrays are synchronized and updated atomically when a new HTF bar appears.
Computational Complexity
Data collection: O(1) per bar
K-Means (one pass):
- Assignment: O(N * K) where N = number of points, K = number of clusters
- Update: O(N * K)
- Total: O(N * K * I) where I = number of iterations (usually 5-20)
Example: With N=200 HTF bars, K=5 clusters, I=20 iterations:
200 * 5 * 20 = 20,000 operations (executes quickly)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📖 USER GUIDE
Quick Start
1. Adding the Indicator
TradingView → Indicators → Favorites → MTF K-Means Price Regimes
Or copy the code from mtf_kmeans_price_regimes.pine into Pine Editor.
2. First Launch
When adding the indicator to the chart, you'll see a table in the upper right corner:
┌─────────────────────────┐
│ Status │ Collecting HTF │
├─────────────────────────┤
│ Collected│ 15 / 50 │
└─────────────────────────┘
This means the indicator is accumulating history from the higher timeframe. Wait until the counter reaches the minimum (default 50 bars for K=5).
3. Active Operation
After data collection is complete, the main table with cluster information will appear:
┌────┬──────┬──────┬──────┬──────────────┬────────┐
│ ID │ RSI │ ATR% │ ΔP% │ Description │Current │
├────┼──────┼──────┼──────┼──────────────┼────────┤
│ 1 │ 68.5 │ 2.15 │ 1.2 │ High Vol,Bull│ │
│ 2 │ 52.3 │ 0.85 │ 0.1 │ Low Vol,Flat │ ► │
│ 3 │ 35.2 │ 1.95 │ -1.5 │ High Vol,Bear│ │
└────┴──────┴──────┴──────┴──────────────┴────────┘
The arrow ► indicates the current active regime. Chart bars are colored with the corresponding cluster color.
Customizing for Your Strategy
Choosing Higher Timeframe (HTF)
Rule: HTF should be at least 4 times higher than the working timeframe.
| Working TF | Recommended HTF |
|------------|-----------------|
| 1 min | 15 min - 1H |
| 5 min | 1H - 4H |
| 15 min | 4H - D |
| 1H | D - W |
| 4H | D - W |
| D | W - M |
HTF Selection Effect:
Lower HTF (closer to working TF): More sensitive, frequently changing classification
Higher HTF (much larger than working TF): More stable, long-term regime assessment
Number of Clusters (K)
K = 2-3: Rough division (e.g., "uptrend", "downtrend", "flat")
K = 4-5: Optimal for most cases (DEFAULT: 5)
K = 6-8: Detailed segmentation (requires more data)
K = 9-10: Very fine division (only for long-term analysis with large windows)
Important constraint:
clusterLookback ≥ numClusters * 10
I.e., for K=5 you need at least 50 HTF bars, for K=10 — at least 100 bars.
Clustering Depth (clusterLookback)
This is the rolling window size for building the model.
50-100 HTF bars: Fast adaptation to market changes
200 HTF bars: Optimal balance (DEFAULT)
500-1000 HTF bars: Long-term, stable model
If you get an "Insufficient data" error:
Decrease clusterLookback
Or select a lower HTF (e.g., "4H" instead of "D")
Or decrease numClusters
Color Scheme
Default 10 colors:
Red → Often: strong bearish, high volatility
Orange → Transition, medium volatility
Yellow → Neutral, decreasing activity
Green → Often: strong bullish, high volatility
Blue → Medium bullish, medium volatility
Purple → Oversold, possible reversal
Fuchsia → Overbought, possible reversal
Lime → Strong upward momentum
Aqua → Consolidation, low volatility
White → Undefined regime (rare)
Important: Cluster colors are assigned randomly at each model recalculation! Don't rely on "red = bearish". Instead, look at the description in the table (RSI, ATR%, ΔP%).
You can customize colors in the "Colors" settings section.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
⚙️ INDICATOR PARAMETERS
Main Parameters
Higher Timeframe (htf)
Type: Timeframe selection
Default: "D" (daily)
Description: Timeframe on which the clustering model is built
Recommendation: At least 4 times larger than your working TF
Clustering Depth (clusterLookback)
Type: Integer
Range: 50 - 2000
Default: 200
Description: Number of HTF bars for building the model (rolling window size)
Recommendation:
- Increase for more stable long-term model
- Decrease for fast adaptation or if there's insufficient historical data
Number of Clusters (K) (numClusters)
Type: Integer
Range: 2 - 10
Default: 5
Description: Number of market regimes the algorithm will identify
Recommendation:
- K=3-4 for simple strategies (trending/ranging)
- K=5-6 for universal strategies
- K=7-10 only when clusterLookback ≥ 100*K
Max K-Means Iterations (maxIterations)
Type: Integer
Range: 5 - 50
Default: 20
Description: Maximum number of algorithm iterations
Recommendation:
- 10-20 is sufficient for most cases
- Increase to 30-50 if using K > 7
Feature Parameters
RSI Period (rsiLength)
Type: Integer
Default: 14
Description: Period for RSI calculation (overbought/oversold feature)
Recommendation:
- 14 — standard
- 7-10 — more sensitive
- 20-25 — more smoothed
ATR Period (atrLength)
Type: Integer
Default: 14
Description: Period for ATR calculation (volatility feature)
Recommendation: Usually kept equal to rsiLength
Price Change Period (pcLength)
Type: Integer
Default: 5
Description: Period for percentage price change calculation (trend feature)
Recommendation:
- 3-5 — short-term trend
- 10-20 — medium-term trend
Visualization
Show Info Panel (showDashboard)
Type: Checkbox
Default: true
Description: Enables/disables the information table on the chart
Cluster Color 1-10
Type: Color selection
Description: Customize colors for visual cluster distinction
Recommendation: Use contrasting colors for better readability
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📊 INTERPRETING RESULTS
Reading the Information Table
┌────┬──────┬──────┬──────┬──────────────┬────────┐
│ ID │ RSI │ ATR% │ ΔP% │ Description │Current │
├────┼──────┼──────┼──────┼──────────────┼────────┤
│ 1 │ 68.5 │ 2.15 │ 1.2 │ High Vol,Bull│ │
│ 2 │ 52.3 │ 0.85 │ 0.1 │ Low Vol,Flat │ ► │
│ 3 │ 35.2 │ 1.95 │ -1.5 │ High Vol,Bear│ │
│ 4 │ 45.0 │ 1.20 │ -0.3 │ Low Vol,Bear │ │
│ 5 │ 72.1 │ 3.05 │ 2.8 │ High Vol,Bull│ │
└────┴──────┴──────┴──────┴──────────────┴────────┘
"ID" Column
Cluster number (1-K). Order doesn't matter.
"RSI" Column
Average RSI value in the cluster (0-100):
< 30: Oversold zone
30-45: Bearish sentiment
45-55: Neutral zone
55-70: Bullish sentiment
> 70: Overbought zone
"ATR%" Column
Average volatility in the cluster (as % of price):
< 1%: Low volatility (consolidation, narrow range)
1-2%: Normal volatility
2-3%: Elevated volatility
> 3%: High volatility (strong movements, impulses)
Compared to the average volatility across all clusters to determine "High Vol" or "Low Vol".
"ΔP%" Column
Average price change in the cluster (in % over pcLength period):
> +0.05%: Bullish regime
-0.05% ... +0.05%: Flat (sideways movement)
< -0.05%: Bearish regime
"Description" Column
Automatic interpretation:
"High Vol, Bull" → Strong upward momentum, high activity
"Low Vol, Flat" → Consolidation, narrow range, uncertainty
"High Vol, Bear" → Strong decline, panic, high activity
"Low Vol, Bull" → Slow growth, low activity
"Low Vol, Bear" → Slow decline, low activity
"Current" Column
Arrow ► shows which cluster the last closed bar of your working timeframe is in.
Typical Cluster Patterns
Example 1: Trend/Flat Division (K=3)
Cluster 1: RSI=65, ATR%=2.5, ΔP%=+1.5 → Bullish trend
Cluster 2: RSI=50, ATR%=0.8, ΔP%=0.0 → Flat/Consolidation
Cluster 3: RSI=35, ATR%=2.3, ΔP%=-1.4 → Bearish trend
Strategy: Open positions when regime changes Flat → Trend, avoid flat.
Example 2: Volatility Breakdown (K=5)
Cluster 1: RSI=72, ATR%=3.5, ΔP%=+2.5 → Strong bullish impulse (high risk)
Cluster 2: RSI=60, ATR%=1.5, ΔP%=+0.8 → Moderate bullish (optimal entry point)
Cluster 3: RSI=50, ATR%=0.7, ΔP%=0.0 → Flat
Cluster 4: RSI=40, ATR%=1.4, ΔP%=-0.7 → Moderate bearish
Cluster 5: RSI=28, ATR%=3.2, ΔP%=-2.3 → Strong bearish impulse (panic)
Strategy: Enter in Cluster 2 or 4, avoid extremes (1, 5).
Example 3: Mixed Regimes (K=7+)
With large K, clusters can represent condition combinations:
High RSI + Low volatility → "Quiet overbought"
Neutral RSI + High volatility → "Uncertainty with high activity"
Etc.
Requires individual analysis of each cluster.
Regime Changes
Important signal: Transition from one cluster to another!
Trading situation examples:
Flat → Bullish trend → Buy signal
Bullish trend → Flat → Take profit, close longs
Flat → Bearish trend → Sell signal
Bearish trend → Flat → Close shorts, wait
You can build a trading system based on the current active cluster and transitions between them.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
💡 USAGE EXAMPLES
Example 1: Scalping with HTF Filter
Task: Scalping on 5-minute charts, but only enter in the direction of the daily regime.
Settings:
Working TF: 5 min
HTF: D (daily)
K: 3 (simple division)
clusterLookback: 100
Logic:
IF current cluster = "Bullish" (ΔP% > 0.5)
→ Look for long entry points on 5M
IF current cluster = "Bearish" (ΔP% < -0.5)
→ Look for short entry points on 5M
IF current cluster = "Flat"
→ Don't trade / reduce risk
Example 2: Swing Trading with Volatility Filtering
Task: Swing trading on 4H, enter only in regimes with medium volatility.
Settings:
Working TF: 4H
HTF: D (daily)
K: 5
clusterLookback: 200
Logic:
Allowed clusters for entry:
- ATR% from 1.5% to 2.5% (not too quiet, not too chaotic)
- ΔP% with clear direction (|ΔP%| > 0.5)
Prohibited clusters:
- ATR% > 3% → Too risky (possible gaps, sharp reversals)
- ATR% < 1% → Too quiet (small movements, commissions eat profit)
Example 3: Portfolio Rotation
Task: Managing a portfolio of multiple assets, allocate capital depending on regimes.
Settings:
Working TF: D (daily)
HTF: W (weekly)
K: 4
clusterLookback: 100
Logic:
For each asset in portfolio:
IF regime = "Strong trend + Low volatility"
→ Increase asset weight in portfolio (40-50%)
IF regime = "Medium trend + Medium volatility"
→ Standard weight (20-30%)
IF regime = "Flat" or "High volatility without trend"
→ Minimum weight or exclude (0-10%)
Example 4: Combining with Other Indicators
MTF K-Means as a filter:
Main strategy: MA Crossover
Filter: MTF K-Means on higher TF
Rule:
IF MA_fast > MA_slow AND Cluster = "Bullish regime"
→ LONG
IF MA_fast < MA_slow AND Cluster = "Bearish regime"
→ SHORT
ELSE
→ Don't trade (regime doesn't confirm signal)
This dramatically reduces false signals in unsuitable market conditions.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📈 OPTIMIZATION RECOMMENDATIONS
Optimal Settings for Different Styles
Day Trading
Working TF: 5M - 15M
HTF: 1H - 4H
numClusters: 4-5
clusterLookback: 100-150
Swing Trading
Working TF: 1H - 4H
HTF: D
numClusters: 5-6
clusterLookback: 150-250
Position Trading
Working TF: D
HTF: W - M
numClusters: 4-5
clusterLookback: 100-200
Scalping
Working TF: 1M - 5M
HTF: 15M - 1H
numClusters: 3-4
clusterLookback: 50-100
Backtesting
To evaluate effectiveness:
Load historical data (minimum 2x clusterLookback HTF bars)
Apply the indicator with your settings
Study cluster change history:
- Do changes coincide with actual trend transitions?
- How often do false signals occur?
Optimize parameters:
- If too much noise → increase HTF or clusterLookback
- If reaction too slow → decrease HTF or increase numClusters
Combining with Other Techniques
Regime-Based Approach:
MTF K-Means (regime identification)
↓
+---+---+---+
| | | |
v v v v
Trend Flat High_Vol Low_Vol
↓ ↓ ↓ ↓
Strategy_A Strategy_B Don't_trade
Examples:
Trend: Use trend-following strategies (MA crossover, Breakout)
Flat: Use mean-reversion strategies (RSI, Bollinger Bands)
High volatility: Reduce position sizes, widen stops
Low volatility: Expect breakout, don't open positions inside range
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
📞 SUPPORT
Report an Issue
If you found a bug or have a suggestion for improvement:
Describe the problem in as much detail as possible
Specify your indicator settings
Attach a screenshot (if possible)
Specify the asset and timeframe where the problem is observed

Keltner Channel Enhanced [DCAUT]█ Keltner Channel Enhanced
📊 ORIGINALITY & INNOVATION
The Keltner Channel Enhanced represents an important advancement over standard Keltner Channel implementations by introducing dual flexibility in moving average selection for both the middle band and ATR calculation. While traditional Keltner Channels typically use EMA for the middle band and RMA (Wilder's smoothing) for ATR, this enhanced version provides access to 25+ moving average algorithms for both components, enabling traders to fine-tune the indicator's behavior to match specific market characteristics and trading approaches.
Key Advancements:
Dual MA Algorithm Flexibility: Independent selection of moving average types for middle band (25+ options) and ATR smoothing (25+ options), allowing optimization of both trend identification and volatility measurement separately
Enhanced Trend Sensitivity: Ability to use faster algorithms (HMA, T3) for middle band while maintaining stable volatility measurement with traditional ATR smoothing, or vice versa for different trading strategies
Adaptive Volatility Measurement: Choice of ATR smoothing algorithm affects channel responsiveness to volatility changes, from highly reactive (SMA, EMA) to smoothly adaptive (RMA, TEMA)
Comprehensive Alert System: Five distinct alert conditions covering breakouts, trend changes, and volatility expansion, enabling automated monitoring without constant chart observation
Multi-Timeframe Compatibility: Works effectively across all timeframes from intraday scalping to long-term position trading, with independent optimization of trend and volatility components
This implementation addresses key limitations of standard Keltner Channels: fixed EMA/RMA combination may not suit all market conditions or trading styles. By decoupling the trend component from volatility measurement and allowing independent algorithm selection, traders can create highly customized configurations for specific instruments and market phases.
📐 MATHEMATICAL FOUNDATION
Keltner Channel Enhanced uses a three-component calculation system that combines a flexible moving average middle band with ATR-based (Average True Range) upper and lower channels, creating volatility-adjusted trend-following bands.
Core Calculation Process:
1. Middle Band (Basis) Calculation:
The basis line is calculated using the selected moving average algorithm applied to the price source over the specified period:
basis = ma(source, length, maType)
Supported algorithms include EMA (standard choice, trend-biased), SMA (balanced and symmetric), HMA (reduced lag), WMA, VWMA, TEMA, T3, KAMA, and 17+ others.
2. Average True Range (ATR) Calculation:
ATR measures market volatility by calculating the average of true ranges over the specified period:
trueRange = max(high - low, abs(high - close ), abs(low - close ))
atrValue = ma(trueRange, atrLength, atrMaType)
ATR smoothing algorithm significantly affects channel behavior, with options including RMA (standard, very smooth), SMA (moderate smoothness), EMA (fast adaptation), TEMA (smooth yet responsive), and others.
3. Channel Calculation:
Upper and lower channels are positioned at specified multiples of ATR from the basis:
upperChannel = basis + (multiplier × atrValue)
lowerChannel = basis - (multiplier × atrValue)
Standard multiplier is 2.0, providing channels that dynamically adjust width based on market volatility.
Keltner Channel vs. Bollinger Bands - Key Differences:
While both indicators create volatility-based channels, they use fundamentally different volatility measures:
Keltner Channel (ATR-based):
Uses Average True Range to measure actual price movement volatility
Incorporates gaps and limit moves through true range calculation
More stable in trending markets, less prone to extreme compression
Better reflects intraday volatility and trading range
Typically fewer band touches, making touches more significant
More suitable for trend-following strategies
Bollinger Bands (Standard Deviation-based):
Uses statistical standard deviation to measure price dispersion
Based on closing prices only, doesn't account for intraday range
Can compress significantly during consolidation (squeeze patterns)
More touches in ranging markets
Better suited for mean-reversion strategies
Provides statistical probability framework (95% within 2 standard deviations)
Algorithm Combination Effects:
The interaction between middle band MA type and ATR MA type creates different indicator characteristics:
Trend-Focused Configuration (Fast MA + Slow ATR): Middle band uses HMA/EMA/T3, ATR uses RMA/TEMA, quick trend changes with stable channel width, suitable for trend-following
Volatility-Focused Configuration (Slow MA + Fast ATR): Middle band uses SMA/WMA, ATR uses EMA/SMA, stable trend with dynamic channel width, suitable for volatility trading
Balanced Configuration (Standard EMA/RMA): Classic Keltner Channel behavior, time-tested combination, suitable for general-purpose trend following
Adaptive Configuration (KAMA + KAMA): Self-adjusting indicator responding to efficiency ratio, suitable for markets with varying trend strength and volatility regimes
📊 COMPREHENSIVE SIGNAL ANALYSIS
Keltner Channel Enhanced provides multiple signal categories optimized for trend-following and breakout strategies.
Channel Position Signals:
Upper Channel Interaction:
Price Touching Upper Channel: Strong bullish momentum, price moving more than typical volatility range suggests, potential continuation signal in established uptrends
Price Breaking Above Upper Channel: Exceptional strength, price exceeding normal volatility expectations, consider adding to long positions or tightening trailing stops
Price Riding Upper Channel: Sustained strong uptrend, characteristic of powerful bull moves, stay with trend and avoid premature profit-taking
Price Rejection at Upper Channel: Momentum exhaustion signal, consider profit-taking on longs or waiting for pullback to middle band for reentry
Lower Channel Interaction:
Price Touching Lower Channel: Strong bearish momentum, price moving more than typical volatility range suggests, potential continuation signal in established downtrends
Price Breaking Below Lower Channel: Exceptional weakness, price exceeding normal volatility expectations, consider adding to short positions or protecting against further downside
Price Riding Lower Channel: Sustained strong downtrend, characteristic of powerful bear moves, stay with trend and avoid premature covering
Price Rejection at Lower Channel: Momentum exhaustion signal, consider covering shorts or waiting for bounce to middle band for reentry
Middle Band (Basis) Signals:
Trend Direction Confirmation:
Price Above Basis: Bullish trend bias, middle band acts as dynamic support in uptrends, consider long positions or holding existing longs
Price Below Basis: Bearish trend bias, middle band acts as dynamic resistance in downtrends, consider short positions or avoiding longs
Price Crossing Above Basis: Potential trend change from bearish to bullish, early signal to establish long positions
Price Crossing Below Basis: Potential trend change from bullish to bearish, early signal to establish short positions or exit longs
Pullback Trading Strategy:
Uptrend Pullback: Price pulls back from upper channel to middle band, finds support, and resumes upward, ideal long entry point
Downtrend Bounce: Price bounces from lower channel to middle band, meets resistance, and resumes downward, ideal short entry point
Basis Test: Strong trends often show price respecting the middle band as support/resistance on pullbacks
Failed Test: Price breaking through middle band against trend direction signals potential reversal
Volatility-Based Signals:
Narrow Channels (Low Volatility):
Consolidation Phase: Channels contract during periods of reduced volatility and directionless price action
Breakout Preparation: Narrow channels often precede significant directional moves as volatility cycles
Trading Approach: Reduce position sizes, wait for breakout confirmation, avoid range-bound strategies within channels
Breakout Direction: Monitor for price breaking decisively outside channel range with expanding width
Wide Channels (High Volatility):
Trending Phase: Channels expand during strong directional moves and increased volatility
Momentum Confirmation: Wide channels confirm genuine trend with substantial volatility backing
Trading Approach: Trend-following strategies excel, wider stops necessary, mean-reversion strategies risky
Exhaustion Signs: Extreme channel width (historical highs) may signal approaching consolidation or reversal
Advanced Pattern Recognition:
Channel Walking Pattern:
Upper Channel Walk: Price consistently touches or exceeds upper channel while staying above basis, very strong uptrend signal, hold longs aggressively
Lower Channel Walk: Price consistently touches or exceeds lower channel while staying below basis, very strong downtrend signal, hold shorts aggressively
Basis Support/Resistance: During channel walks, price typically uses middle band as support/resistance on minor pullbacks
Pattern Break: Price crossing basis during channel walk signals potential trend exhaustion
Squeeze and Release Pattern:
Squeeze Phase: Channels narrow significantly, price consolidates near middle band, volatility contracts
Direction Clues: Watch for price positioning relative to basis during squeeze (above = bullish bias, below = bearish bias)
Release Trigger: Price breaking outside narrow channel range with expanding width confirms breakout
Follow-Through: Measure squeeze height and project from breakout point for initial profit targets
Channel Expansion Pattern:
Breakout Confirmation: Rapid channel widening confirms volatility increase and genuine trend establishment
Entry Timing: Enter positions early in expansion phase before trend becomes overextended
Risk Management: Use channel width to size stops appropriately, wider channels require wider stops
Basis Bounce Pattern:
Clean Bounce: Price touches middle band and immediately reverses, confirms trend strength and entry opportunity
Multiple Bounces: Repeated basis bounces indicate strong, sustainable trend
Bounce Failure: Price penetrating basis signals weakening trend and potential reversal
Divergence Analysis:
Price/Channel Divergence: Price makes new high/low while staying within channel (not reaching outer band), suggests momentum weakening
Width/Price Divergence: Price breaks to new extremes but channel width contracts, suggests move lacks conviction
Reversal Signal: Divergences often precede trend reversals or significant consolidation periods
Multi-Timeframe Analysis:
Keltner Channels work particularly well in multi-timeframe trend-following approaches:
Three-Timeframe Alignment:
Higher Timeframe (Weekly/Daily): Identify major trend direction, note price position relative to basis and channels
Intermediate Timeframe (Daily/4H): Identify pullback opportunities within higher timeframe trend
Lower Timeframe (4H/1H): Time precise entries when price touches middle band or lower channel (in uptrends) with rejection
Optimal Entry Conditions:
Best Long Entries: Higher timeframe in uptrend (price above basis), intermediate timeframe pulls back to basis, lower timeframe shows rejection at middle band or lower channel
Best Short Entries: Higher timeframe in downtrend (price below basis), intermediate timeframe bounces to basis, lower timeframe shows rejection at middle band or upper channel
Risk Management: Use higher timeframe channel width to set position sizing, stops below/above higher timeframe channels
🎯 STRATEGIC APPLICATIONS
Keltner Channel Enhanced excels in trend-following and breakout strategies across different market conditions.
Trend Following Strategy:
Setup Requirements:
Identify established trend with price consistently on one side of basis line
Wait for pullback to middle band (basis) or brief penetration through it
Confirm trend resumption with price rejection at basis and move back toward outer channel
Enter in trend direction with stop beyond basis line
Entry Rules:
Uptrend Entry:
Price pulls back from upper channel to middle band, shows support at basis (bullish candlestick, momentum divergence)
Enter long on rejection/bounce from basis with stop 1-2 ATR below basis
Aggressive: Enter on first touch; Conservative: Wait for confirmation candle
Downtrend Entry:
Price bounces from lower channel to middle band, shows resistance at basis (bearish candlestick, momentum divergence)
Enter short on rejection/reversal from basis with stop 1-2 ATR above basis
Aggressive: Enter on first touch; Conservative: Wait for confirmation candle
Trend Management:
Trailing Stop: Use basis line as dynamic trailing stop, exit if price closes beyond basis against position
Profit Taking: Take partial profits at opposite channel, move stops to basis
Position Additions: Add to winners on subsequent basis bounces if trend intact
Breakout Strategy:
Setup Requirements:
Identify consolidation period with contracting channel width
Monitor price action near middle band with reduced volatility
Wait for decisive breakout beyond channel range with expanding width
Enter in breakout direction after confirmation
Breakout Confirmation:
Price breaks clearly outside channel (upper for longs, lower for shorts), channel width begins expanding from contracted state
Volume increases significantly on breakout (if using volume analysis)
Price sustains outside channel for multiple bars without immediate reversal
Entry Approaches:
Aggressive: Enter on initial break with stop at opposite channel or basis, use smaller position size
Conservative: Wait for pullback to broken channel level, enter on rejection and resumption, tighter stop
Volatility-Based Position Sizing:
Adjust position sizing based on channel width (ATR-based volatility):
Wide Channels (High ATR): Reduce position size as stops must be wider, calculate position size using ATR-based risk calculation: Risk / (Stop Distance in ATR × ATR Value)
Narrow Channels (Low ATR): Increase position size as stops can be tighter, be cautious of impending volatility expansion
ATR-Based Risk Management: Use ATR-based risk calculations, position size = 0.01 × Capital / (2 × ATR), use multiples of ATR (1-2 ATR) for adaptive stops
Algorithm Selection Guidelines:
Different market conditions benefit from different algorithm combinations:
Strong Trending Markets: Middle band use EMA or HMA, ATR use RMA, capture trends quickly while maintaining stable channel width
Choppy/Ranging Markets: Middle band use SMA or WMA, ATR use SMA or WMA, avoid false trend signals while identifying genuine reversals
Volatile Markets: Middle band and ATR both use KAMA or FRAMA, self-adjusting to changing market conditions reduces manual optimization
Breakout Trading: Middle band use SMA, ATR use EMA or SMA, stable trend with dynamic channels highlights volatility expansion early
Scalping/Day Trading: Middle band use HMA or T3, ATR use EMA or TEMA, both components respond quickly
Position Trading: Middle band use EMA/TEMA/T3, ATR use RMA or TEMA, filter out noise for long-term trend-following
📋 DETAILED PARAMETER CONFIGURATION
Understanding and optimizing parameters is essential for adapting Keltner Channel Enhanced to specific trading approaches.
Source Parameter:
Close (Most Common): Uses closing price, reflects daily settlement, best for end-of-day analysis and position trading, standard choice
HL2 (Median Price): Smooths out closing bias, better represents full daily range in volatile markets, good for swing trading
HLC3 (Typical Price): Gives more weight to close while including full range, popular for intraday applications, slightly more responsive than HL2
OHLC4 (Average Price): Most comprehensive price representation, smoothest option, good for gap-prone markets or highly volatile instruments
Length Parameter:
Controls the lookback period for middle band (basis) calculation:
Short Periods (10-15): Very responsive to price changes, suitable for day trading and scalping, higher false signal rate
Standard Period (20 - Default): Represents approximately one month of trading, good balance between responsiveness and stability, suitable for swing and position trading
Medium Periods (30-50): Smoother trend identification, fewer false signals, better for position trading and longer holding periods
Long Periods (50+): Very smooth, identifies major trends only, minimal false signals but significant lag, suitable for long-term investment
Optimization by Timeframe: 1-15 minute charts use 10-20 period, 30-60 minute charts use 20-30 period, 4-hour to daily charts use 20-40 period, weekly charts use 20-30 weeks.
ATR Length Parameter:
Controls the lookback period for Average True Range calculation, affecting channel width:
Short ATR Periods (5-10): Very responsive to recent volatility changes, standard is 10 (Keltner's original specification), may be too reactive in whipsaw conditions
Standard ATR Period (10 - Default): Chester Keltner's original specification, good balance between responsiveness and stability, most widely used
Medium ATR Periods (14-20): Smoother channel width, ATR 14 aligns with Wilder's original ATR specification, good for position trading
Long ATR Periods (20+): Very smooth channel width, suitable for long-term trend-following
Length vs. ATR Length Relationship: Equal values (20/20) provide balanced responsiveness, longer ATR (20/14) gives more stable channel width, shorter ATR (20/10) is standard configuration, much shorter ATR (20/5) creates very dynamic channels.
Multiplier Parameter:
Controls channel width by setting ATR multiples:
Lower Values (1.0-1.5): Tighter channels with frequent price touches, more trading signals, higher false signal rate, better for range-bound and mean-reversion strategies
Standard Value (2.0 - Default): Chester Keltner's recommended setting, good balance between signal frequency and reliability, suitable for both trending and ranging strategies
Higher Values (2.5-3.0): Wider channels with less frequent touches, fewer but potentially higher-quality signals, better for strong trending markets
Market-Specific Optimization: High volatility markets (crypto, small-caps) use 2.5-3.0 multiplier, medium volatility markets (major forex, large-caps) use 2.0 multiplier, low volatility markets (bonds, utilities) use 1.5-2.0 multiplier.
MA Type Parameter (Middle Band):
Critical selection that determines trend identification characteristics:
EMA (Exponential Moving Average - Default): Standard Keltner Channel choice, Chester Keltner's original specification, emphasizes recent prices, faster response to trend changes, suitable for all timeframes
SMA (Simple Moving Average): Equal weighting of all data points, no directional bias, slower than EMA, better for ranging markets and mean-reversion
HMA (Hull Moving Average): Minimal lag with smooth output, excellent for fast trend identification, best for day trading and scalping
TEMA (Triple Exponential Moving Average): Advanced smoothing with reduced lag, responsive to trends while filtering noise, suitable for volatile markets
T3 (Tillson T3): Very smooth with minimal lag, excellent for established trend identification, suitable for position trading
KAMA (Kaufman Adaptive Moving Average): Automatically adjusts speed based on market efficiency, slow in ranging markets, fast in trends, suitable for markets with varying conditions
ATR MA Type Parameter:
Determines how Average True Range is smoothed, affecting channel width stability:
RMA (Wilder's Smoothing - Default): J. Welles Wilder's original ATR smoothing method, very smooth, slow to adapt to volatility changes, provides stable channel width
SMA (Simple Moving Average): Equal weighting, moderate smoothness, faster response to volatility changes than RMA, more dynamic channel width
EMA (Exponential Moving Average): Emphasizes recent volatility, quick adaptation to new volatility regimes, very responsive channel width changes
TEMA (Triple Exponential Moving Average): Smooth yet responsive, good balance for varying volatility, suitable for most trading styles
Parameter Combination Strategies:
Conservative Trend-Following: Length 30/ATR Length 20/Multiplier 2.5, MA Type EMA or TEMA/ATR MA Type RMA, smooth trend with stable wide channels, suitable for position trading
Standard Balanced Approach: Length 20/ATR Length 10/Multiplier 2.0, MA Type EMA/ATR MA Type RMA, classic Keltner Channel configuration, suitable for general purpose swing trading
Aggressive Day Trading: Length 10-15/ATR Length 5-7/Multiplier 1.5-2.0, MA Type HMA or EMA/ATR MA Type EMA or SMA, fast trend with dynamic channels, suitable for scalping and day trading
Breakout Specialist: Length 20-30/ATR Length 5-10/Multiplier 2.0, MA Type SMA or WMA/ATR MA Type EMA or SMA, stable trend with responsive channel width
Adaptive All-Conditions: Length 20/ATR Length 10/Multiplier 2.0, MA Type KAMA or FRAMA/ATR MA Type KAMA or TEMA, self-adjusting to market conditions
Offset Parameter:
Controls horizontal positioning of channels on chart. Positive values shift channels to the right (future) for visual projection, negative values shift left (past) for historical analysis, zero (default) aligns with current price bars for real-time signal analysis. Offset affects only visual display, not alert conditions or actual calculations.
📈 PERFORMANCE ANALYSIS & COMPETITIVE ADVANTAGES
Keltner Channel Enhanced provides improvements over standard implementations while maintaining proven effectiveness.
Response Characteristics:
Standard EMA/RMA Configuration: Moderate trend lag (approximately 0.4 × length periods), smooth and stable channel width from RMA smoothing, good balance for most market conditions
Fast HMA/EMA Configuration: Approximately 60% reduction in trend lag compared to EMA, responsive channel width from EMA ATR smoothing, suitable for quick trend changes and breakouts
Adaptive KAMA/KAMA Configuration: Variable lag based on market efficiency, automatic adjustment to trending vs. ranging conditions, self-optimizing behavior reduces manual intervention
Comparison with Traditional Keltner Channels:
Enhanced Version Advantages:
Dual Algorithm Flexibility: Independent MA selection for trend and volatility vs. fixed EMA/RMA, separate tuning of trend responsiveness and channel stability
Market Adaptation: Choose configurations optimized for specific instruments and conditions, customize for scalping, swing, or position trading preferences
Comprehensive Alerts: Enhanced alert system including channel expansion detection
Traditional Version Advantages:
Simplicity: Fewer parameters, easier to understand and implement
Standardization: Fixed EMA/RMA combination ensures consistency across users
Research Base: Decades of backtesting and research on standard configuration
When to Use Enhanced Version: Trading multiple instruments with different characteristics, switching between trending and ranging markets, employing different strategies, algorithm-based trading systems requiring customization, seeking optimization for specific trading style and timeframe.
When to Use Standard Version: Beginning traders learning Keltner Channel concepts, following published research or trading systems, preferring simplicity and standardization, wanting to avoid optimization and curve-fitting risks.
Performance Across Market Conditions:
Strong Trending Markets: EMA or HMA basis with RMA or TEMA ATR smoothing provides quicker trend identification, pullbacks to basis offer excellent entry opportunities
Choppy/Ranging Markets: SMA or WMA basis with RMA ATR smoothing and lower multipliers, channel bounce strategies work well, avoid false breakouts
Volatile Markets: KAMA or FRAMA with EMA or TEMA, adaptive algorithms excel by automatic adjustment, wider multipliers (2.5-3.0) accommodate large price swings
Low Volatility/Consolidation: Channels narrow significantly indicating consolidation, algorithm choice less impactful, focus on detecting channel width contraction for breakout preparation
Keltner Channel vs. Bollinger Bands - Usage Comparison:
Favor Keltner Channels When: Trend-following is primary strategy, trading volatile instruments with gaps, want ATR-based volatility measurement, prefer fewer higher-quality channel touches, seeking stable channel width during trends.
Favor Bollinger Bands When: Mean-reversion is primary strategy, trading instruments with limited gaps, want statistical framework based on standard deviation, need squeeze patterns for breakout identification, prefer more frequent trading opportunities.
Use Both Together: Bollinger Band squeeze + Keltner Channel breakout is powerful combination, price outside Bollinger Bands but inside Keltner Channels indicates moderate signal, price outside both indicates very strong signal, Bollinger Bands for entries and Keltner Channels for trend confirmation.
Limitations and Considerations:
General Limitations:
Lagging Indicator: All moving averages lag price, even with reduced-lag algorithms
Trend-Dependent: Works best in trending markets, less effective in choppy conditions
No Direction Prediction: Indicates volatility and deviation, not future direction, requires confirmation
Enhanced Version Specific Considerations:
Optimization Risk: More parameters increase risk of curve-fitting historical data
Complexity: Additional choices may overwhelm beginning traders
Backtesting Challenges: Different algorithms produce different historical results
Mitigation Strategies:
Use Confirmation: Combine with momentum indicators (RSI, MACD), volume, or price action
Test Parameter Robustness: Ensure parameters work across range of values, not just optimized ones
Multi-Timeframe Analysis: Confirm signals across different timeframes
Proper Risk Management: Use appropriate position sizing and stops
Start Simple: Begin with standard EMA/RMA before exploring alternatives
Optimal Usage Recommendations:
For Maximum Effectiveness:
Start with standard EMA/RMA configuration to understand classic behavior
Experiment with alternatives on demo account or paper trading
Match algorithm combination to market condition and trading style
Use channel width analysis to identify market phases
Combine with complementary indicators for confirmation
Implement strict risk management using ATR-based position sizing
Focus on high-quality setups rather than trading every signal
Respect the trend: trade with basis direction for higher probability
Complementary Indicators:
RSI or Stochastic: Confirm momentum at channel extremes
MACD: Confirm trend direction and momentum shifts
Volume: Validate breakouts and trend strength
ADX: Measure trend strength, avoid Keltner signals in weak trends
Support/Resistance: Combine with traditional levels for high-probability setups
Bollinger Bands: Use together for enhanced breakout and volatility analysis
USAGE NOTES
This indicator is designed for technical analysis and educational purposes. Keltner Channel Enhanced has limitations and should not be used as the sole basis for trading decisions. While the flexible moving average selection for both trend and volatility components provides valuable adaptability across different market conditions, algorithm performance varies with market conditions, and past characteristics do not guarantee future results.
Key considerations:
Always use multiple forms of analysis and confirmation before entering trades
Backtest any parameter combination thoroughly before live trading
Be aware that optimization can lead to curve-fitting if not done carefully
Start with standard EMA/RMA settings and adjust only when specific conditions warrant
Understand that no moving average algorithm can eliminate lag entirely
Consider market regime (trending, ranging, volatile) when selecting parameters
Use ATR-based position sizing and risk management on every trade
Keltner Channels work best in trending markets, less effective in choppy conditions
Respect the trend direction indicated by price position relative to basis line
The enhanced flexibility of dual algorithm selection provides powerful tools for adaptation but requires responsible use, thorough understanding of how different algorithms behave under various market conditions, and disciplined risk management.

CloudfareCloudfare - Advanced Market Sentiment Visualization System
What It Does:
Cloudfare is a proprietary market sentiment analysis tool that visualizes real-time money flow and order flow through a dynamic cloud system. Unlike traditional indicators that lag price action, Cloudfare provides forward-looking market sentiment analysis by combining multiple proprietary algorithms.
Core Innovation - Dynamic Cloud Technology:
The cloud system is the primary innovation, not a simple mashup of existing indicators. It uses a proprietary algorithm that:
Analyzes money flow velocity through volume-weighted price action
Calculates institutional order flow patterns using proprietary OBV modifications
Implements a unique "breathing" algorithm that expands/contracts based on market volatility
Uses color-coded transparency to indicate sentiment strength (0-100 scale)
Proprietary Signal Generation:
Higher High/Lower Low Pattern Recognition: Custom algorithm that identifies price breakouts with 3-bar confirmation and volume divergence analysis
Signal Strength Scoring: Proprietary 0-100 scoring system that combines price action, volume surge detection, RSI momentum shifts, and money flow velocity
Dynamic Glow System: Signal brightness adapts to market conditions - brighter signals indicate higher probability setups
Technical Methodology:
Money Flow Analysis: Custom MFI implementation with volume weighting and momentum calculations
Order Flow Tracking: Proprietary OBV modifications that detect institutional accumulation/distribution
Volume Divergence Detection: Unique algorithm that identifies volume patterns not visible in standard indicators
Multi-Factor Confirmation: Combines 5 different confirmation methods to filter false signals
Why This Justifies Closed-Source Protection:
The core algorithms for cloud generation, signal strength calculation, and dynamic glow adaptation are proprietary mathematical models developed over 3 months of testing. These are not simple combinations of existing indicators but original mathematical approaches to market sentiment visualization.
Unique Value Proposition:
Real-time sentiment visualization through the breathing cloud system
Forward-looking signals that anticipate trend changes before price confirmation
Adaptive transparency that changes based on market conditions
Multi-timeframe VWAP integration with proprietary anchoring methodology
How to Use:
Cloud Analysis: Green cloud indicates bullish money flow, red indicates bearish pressure
Diamond Signals: Green diamonds below price for bullish reversals, red diamonds above for bearish
Signal Strength: Brighter diamonds represent higher probability setups
Trend Confirmation: 5-day confirmation system filters noise and false signals
Best Practices:
Works optimally on daily and 4-hour timeframes
Combine with price action analysis for maximum effectiveness
Monitor cloud color changes for early trend shift warnings
Use diamond signals for entry/exit timing
Author's Instructions:
To request access to this invite-only script, please contact me directly through TradingView messaging with your trading experience and intended use case. Access is granted on a case-by-case basis to ensure proper usage and support.

Two-Phase Adaptive System | AlphaNattTwo-Phase Adaptive System (TPAS) - Professional Grade Crypto Allocation Framework
A groundbreaking dual-strategy system that revolutionizes portfolio management through dynamic performance-based strategy selection
═══════ REVOLUTIONARY APPROACH ═══════
This indicator represents an entirely original methodology in systematic trading - a true first-of-its-kind approach that fundamentally reimagines how allocation strategies should operate. Unlike any other system available on TradingView, TPAS employs a proprietary dual-engine architecture that continuously evaluates two independent trading methodologies and dynamically allocates capital based on their relative performance dynamics.
What Makes This Absolutely Unique:
Performance-Based Strategy Selection: Instead of using static rules or market conditions to choose strategies, TPAS analyzes the real-time equity curves of both systems
Dual-Engine Architecture: Two complete trading systems run simultaneously, each with distinct market philosophies and risk profiles
Adaptive Switching Mechanism: Proprietary algorithm that determines optimal transition points between strategies
No comparable system exists that combines performance-relative switching with dual independent strategy engines
THE TWO SYSTEMS
The innovation lies not in the individual strategies, but in the revolutionary framework that allows them to work in concert, automatically selecting the optimal approach for current market dynamics
1. Tactical System (Defensive Core)
Multi-layered market regime analysis
Complex trend indicator synthesis from multiple timeframes
Defensive positioning with strict cash management protocols
Prioritizes capital preservation during uncertain conditions
Incorporates over 20 proprietary market indicators
2. Momentum System (Growth Engine)
Trend-following methodology optimized for sustained moves
Statistical deviation analysis for entry/exit timing
Aggressive positioning during confirmed uptrends
Designed to capture major market movements
Streamlined signal generation for rapid response
DYNAMIC ALLOCATION MECHANISM
The system's crown jewel is its adaptive selection algorithm:
Continuously calculates equity curves for both strategies
Computes performance ratio between systems
Applies proprietary smoothing algorithms to identify regime changes
Automatically switches to the outperforming strategy
Maintains position continuity during transitions
ASSET UNIVERSE & ROTATION
Bitcoin (BTC): The market beta and defensive allocation
Ethereum (ETH): Smart contract ecosystem exposure
Solana (SOL): High-performance blockchain allocation
Cash Position: Strategic capital preservation when conditions deteriorate
The system employs sophisticated relative strength analysis between asset pairs (BTC/ETH, ETH/SOL, BTC/SOL) to determine optimal positioning within each strategy framework.
VISUAL INTELLIGENCE
Dual-layer equity curve with enhanced glow visualization
Real-time system state indicator showing active strategy
Portfolio allocation display with current positions
Comprehensive metrics dashboard (Sharpe, Sortino, Omega, Maximum Drawdown)
Bitcoin buy-and-hold benchmark for performance comparison
Color-coded position indicators for instant visual feedback
RISK MANAGEMENT PHILOSOPHY
The system operates on the principle that avoiding losses is more important than capturing gains . Both engines incorporate independent risk controls, position limits, and systematic cash allocation protocols that activate during adverse conditions.
═══════ CRITICAL DISCLAIMERS ═══════
BACKTEST LIMITATIONS:
Past performance does NOT indicate future results
Historical backtests assume perfect execution without slippage
Real-world trading involves costs, delays, and market impact
Cryptocurrency markets have evolved significantly - past patterns may not repeat
Backtested results often overstate actual achievable returns
System performance during unprecedented market conditions is unknown
Important Operational Notes:
This is a signal indicator only - NOT an automated trading bot
Requires manual trade execution based on generated signals
Designed exclusively for daily timeframe analysis
Signals fire at daily close - not intraday
Best suited for position traders and long-term investors
Not appropriate for leverage trading or short-term speculation
WHO THIS IS FOR
Sophisticated traders seeking systematic crypto exposure
Investors who understand the importance of adaptive strategies
Those who prioritize risk-adjusted returns over raw performance
Users who value transparency and detailed performance metrics
Traders comfortable with daily rebalancing requirements
WHO THIS IS NOT FOR
Day traders or scalpers
Those seeking guaranteed returns
Traders unable to execute daily rebalancing
Anyone expecting fully automated trading
CONFIGURATION PARAMETERS
While the core algorithm is proprietary and fixed, users can adjust:
Backtest start date
Strategy selection sensitivity (advanced users only)
Various display options
ACCESS & SUPPORT
This is an invite-only indicator due to its sophisticated nature and computational requirements. For access requests, please send a private message
Final Note:
This system represents months of research, development, and optimization. It is not a "get rich quick" solution but rather a sophisticated framework for those who understand that successful trading requires patience, discipline, and proper risk management.
---
Version 1.0 | Created by AlphaNatt | All Rights Reserved
Not financial advice

AURA AI - Multi-Layer Signal System# AURA AI - Multi-Layer Signal System
## Originality and Value Proposition
This indicator implements a proprietary multi-layer signal filtering system designed specifically for educational trading analysis. The core value lies in three advanced algorithmic features developed to address common issues in market analysis:
1. **Adaptive Signal Spacing Algorithm**: Dynamically adjusts signal frequency based on real-time volatility calculations using custom ATR multipliers (0.7x to 1.8x)
2. **Hierarchical Signal Filtering**: Three-tier priority system with conflict prevention, cooldown periods, and cross-validation
3. **Progressive Educational Framework**: Contextual learning system with market concept explanations
## Technical Implementation
The system processes market data through multiple validation layers:
- **Primary Signals**: Multi-condition convergence requiring simultaneous confirmation from trend detection, directional strength analysis, momentum indicators, volume validation, and positioning filters
- **Trend Signals**: Direction-following analysis with moving average crossover confirmation and momentum validation
- **Reversal Signals**: Counter-trend opportunity detection with strict distance requirements and timeout filtering
## Algorithm Components and Processing
- **Adaptive Trend Detection**: Custom trailing stop methodology with configurable sensitivity parameters
- **Directional Strength Analysis**: Smoothed momentum indicators with threshold validation
- **Volume-Weighted Confirmation**: Market participation analysis using comparative volume metrics
- **Multi-Timeframe Validation**: Higher timeframe directional bias with hysteresis algorithms for stable detection
- **Custom Filtering Engine**: Proprietary noise reduction and signal prioritization algorithms
## Educational Framework Design
The indicator includes a comprehensive learning system addressing the gap between technical analysis tools and trader education:
- **Progressive Complexity**: Simplified interface for beginners transitioning to professional-grade controls
- **Contextual Explanations**: Real-time tooltips explaining market conditions and signal rationale
- **Risk Management Integration**: Built-in safeguards teaching proper trading practices
- **Signal Classification**: Clear categorization helping users understand different opportunity types
## Justification for Closed-Source Protection
This indicator warrants protection due to:
1. **Proprietary Filtering Algorithms**: Custom-developed signal prioritization and conflict resolution logic
2. **Adaptive Volatility System**: Original methodology for dynamic parameter adjustment
3. **Educational Integration**: Comprehensive learning framework with contextual market education
4. **Risk-Aware Design**: Built-in overtrading prevention and educational safeguards
The combination of these elements creates a unified analytical and educational system that goes beyond standard indicator combinations.
## Configuration and Usage
**Educational Mode**: Simplified interface focusing on high-probability setups with learning tooltips
**Professional Mode**: Full parameter control for experienced traders with advanced filtering options
Key settings include signal type selection, volatility adaptation parameters, multi-timeframe analysis, and day-of-week filtering for backtesting optimization.
## Market Application and Limitations
This system is designed for educational analysis across multiple markets and timeframes. The adaptive algorithms adjust to different volatility environments, though users should understand that no analytical tool can predict future market movements.
The indicator serves as an educational tool to help traders understand market dynamics while providing structured signal analysis. Proper risk management, position sizing, and market knowledge remain essential for successful trading.
## Important Disclosures
- This indicator provides educational analysis tools, not trading advice
- Past signal performance does not guarantee future results
- No claims are made regarding win rates or profitability
- Users must implement proper risk management practices
- Market conditions can change, affecting any analytical system's relevance

Crypto Volatility Panel ProCrypto Volatility Panel Pro
This advanced indicator creates a comprehensive volatility monitoring dashboard that displays real-time volatility metrics for up to 30 cryptocurrency pairs simultaneously. The tool combines sophisticated volatility assessment techniques with leverage-adjusted analysis and heat map visualization to provide enhanced market insights in an organized table format.
Proprietary Methodology
This indicator utilizes a proprietary dual-metric volatility assessment system developed specifically for cryptocurrency market analysis. The methodology combines advanced technical analysis components including price volatility measurements, range position analysis, and leverage scaling algorithms optimized through extensive market testing.
The unique approach enables more accurate volatility assessments across diverse cryptocurrency price ranges and market conditions compared to standard volatility indicators. Specific calculation methods and optimization parameters remain proprietary to maintain competitive advantages.
Core Functionality and Innovation
Unlike standard volatility indicators that focus on single instruments, this tool provides simultaneous multi-asset monitoring with proprietary volatility calculations specifically optimized for cryptocurrency markets. The innovation lies in combining multiple volatility assessment techniques with enhanced leverage scaling algorithms, heat map ranking system, and comprehensive multi-asset dashboard presentation.
The indicator processes data from up to 30 different cryptocurrency pairs, each with independent leverage settings ranging from 0.1x to 10,000x. Users can apply universal leverage across all pairs for consistent analysis scenarios, or customize individual leverage ratios for specific trading strategies.
Visual Organization and Heat Map System
The table displays three primary columns with an advanced heat map ranking system:
Symbol Column: Shows cryptocurrency pair names with dynamic visual indicators (🔥, ⚡, ✅, 💤) representing volatility intensity levels. Each symbol includes its current leverage setting in parentheses for reference. Invalid or unavailable symbols display error indicators (❌) with appropriate error messaging.
Change Percentage Column: Displays leverage-adjusted volatility measurements with both color-coded text and heat map background ranking. Text colors indicate volatility levels (Red for extreme, Yellow for high, Green for moderate, Gray for low), while background heat map colors rank performance relative to all monitored pairs.
Lookback Percentage Column: Shows leverage-adjusted position analysis within recent price ranges with heat map background ranking, indicating market positioning relative to recent highs and lows across all monitored instruments.
Advanced Heat Map Ranking
The proprietary heat map system ranks all enabled pairs in real-time based on their volatility metrics, providing instant visual identification of the most and least volatile instruments:
Hottest (Top 10%): Deep red background indicating highest volatility
Warm (10-20%): Orange-red background for elevated volatility
Medium (20-40%): Yellow background for moderate-high volatility
Cool (40-60%): Green background for moderate volatility
Cold (60-80%): Blue background for low volatility
Sleepy (Bottom 20%): Dark background for minimal volatility
Heat map opacity is fully customizable, and the system can be disabled for users preferring traditional static backgrounds.
Configuration Options
Expanded Pair Selection: Monitor up to 30 cryptocurrency pairs across major exchanges including Bitstamp and Binance. Default selections include established cryptocurrencies (BTC, ETH, SOL) and emerging assets (INJ, NEAR, FTM), with full customization available.
Table Positioning: Nine position options including top/middle/bottom combinations with left/center/right alignment, allowing optimal placement on any chart layout without interfering with price action or other indicators.
Visual Customization: Comprehensive control over table dimensions, frame width, font size, background colors, frame colors, header styling, text colors, and heat map color schemes to match user preferences and chart themes.
Leverage Management: Individual leverage settings for each of the 30 pairs, with optional universal leverage mode that applies consistent multipliers across all enabled pairs. Supports extreme leverage ranges up to 10,000x for advanced risk modelling.
Error Handling: Robust symbol validation with clear error indicators for invalid, unavailable, or misconfigured trading pairs, ensuring reliable operation across different market conditions.
Practical Trading Applications
Multi-Asset Volatility Screening: Identify the most and least volatile cryptocurrency markets in real-time using the heat map ranking system, enabling quick allocation of attention to instruments with the highest potential for profitable moves.
Leverage Risk Assessment: Visualize how different leverage ratios amplify volatility metrics across multiple markets simultaneously, supporting informed position sizing decisions before entering leveraged trades.
Market Timing and Rotation: Use the combination of volatility measurements and heat map rankings to identify optimal entry/exit timing across cryptocurrency markets, facilitating effective portfolio rotation strategies.
Portfolio Diversification: Compare volatility levels and rankings across 30 cryptocurrencies to construct portfolios with desired risk characteristics, balancing high-volatility growth opportunities with stable store-of-value positions.
Risk Management Dashboard: Monitor real-time volatility changes and relative rankings to adjust position sizes, implement protective measures, or reallocate capital when market conditions change significantly.
Technical Implementation
Built using Pine Script v5 with optimized security request handling to minimize performance impact while accessing 30 external data sources simultaneously. The indicator uses efficient array-based data collection, real-time ranking algorithms, and conditional table updates to maintain smooth chart operation.
The heat map system employs dynamic ranking calculations that process all enabled pairs in real-time, sorting values and applying percentile-based color mapping for instant visual feedback. Error handling includes invalid symbol detection and graceful fallback display for unavailable data feeds.
Usage Instructions
Configure Pair Selection: Enable desired cryptocurrency pairs from the 30 available options, organized across three input groups for easy navigation. Set individual leverage values or activate universal leverage mode for consistent multipliers.
Customize Heat Map: Adjust heat map colors and opacity to match your visual preferences and chart theme. The system can be disabled for users preferring static backgrounds.
Position and Style Table: Select optimal table position from nine available options and customize appearance including colors, sizing, and text elements to integrate seamlessly with your trading setup.
Interpret Rankings: Monitor both absolute values and heat map rankings to identify relative performance.
Hottest colors indicate pairs experiencing the highest volatility relative to the monitored universe.
Apply Leverage Context: Use leverage-adjusted values to understand how volatility would affect leveraged positions, remembering these are mathematical projections designed for risk assessment rather than trading signals.
Advanced Features
Dynamic Symbol Processing: The indicator automatically handles symbol validation, displaying clear error messages for invalid or unavailable trading pairs while maintaining operation for valid symbols.
Real-Time Ranking: Heat map colors update dynamically as market conditions change, providing instant visual feedback on shifting volatility patterns across the cryptocurrency universe.
Scalable Monitoring: Users can monitor anywhere from a few key pairs to the full 30-pair universe, with the ranking system automatically adjusting to the number of enabled instruments.
Cross-Exchange Support: Incorporates data from multiple cryptocurrency exchanges to provide comprehensive market coverage and reduce single-source dependency risks.
Limitations and Important Considerations
Proprietary Algorithm: The specific calculation methods are proprietary and not disclosed. Users should evaluate the indicator's output through their own analysis and testing before incorporating it into trading decisions.
Complex Volatility Model: While the proprietary methodology is sophisticated, it represents one approach to volatility assessment and may not capture all forms of market volatility such as gap movements, flash crashes, or news-driven events.
Performance Considerations: Processing data from up to 30 external securities may impact chart loading speed or cause timeouts during periods of high TradingView server load. Users experiencing performance issues should consider reducing the number of enabled pairs.
Leverage Calculations: Leverage adjustments are mathematical projections that assume linear scaling, which may not reflect actual leveraged trading mechanics including margin requirements, funding costs, liquidation risks, and exchange-specific policies.
Market Data Dependencies: Cryptocurrency prices and volatility can vary significantly between exchanges. The indicator's data sources may not represent the specific exchange or trading pair you use, and some feeds may experience gaps or delays during maintenance periods.
Ranking Relativity: Heat map rankings are relative to the enabled pair universe. Rankings will change based on which pairs are monitored and their current market conditions, making absolute interpretations less meaningful than relative comparisons.
Educational Value
This indicator helps traders develop understanding of relative volatility patterns across cryptocurrency markets and the mathematical impact of leverage on risk metrics. The heat map system provides intuitive visualization of market dynamics, helping users identify which assets are experiencing unusual activity relative to their peers.
The tool serves as an educational platform for understanding advanced volatility measurement techniques, relative ranking systems, and multi-asset risk assessment concepts that are crucial for professional cryptocurrency trading and portfolio management.
Performance and Compatibility
The indicator is optimized for cryptocurrency markets but can be adapted to other volatile asset classes by modifying the symbol inputs. Security request limits may occasionally affect data availability, particularly when multiple indicators requesting external data are used simultaneously on the same chart.
The heat map rendering system is designed for efficiency, updating color mappings only when ranking changes occur rather than on every price tick, ensuring smooth chart performance even when monitoring the full 30-pair universe.
Risk Disclaimer: This indicator is designed for educational and analytical purposes only. Volatility calculations are estimates based on historical price data and proprietary mathematical models that are not disclosed. Results do not constitute trading advice or predictions of future price movements. Users should conduct independent analysis to evaluate the indicator's effectiveness before making trading decisions.
Leveraged trading involves substantial risk of loss and may not be suitable for all investors. Always conduct thorough research and consider consulting with qualified financial professionals before making leveraged trading decisions. Cryptocurrency markets are highly volatile and can result in significant losses. Past volatility patterns do not guarantee future market behavior.
This indicator is compatible with all TradingView chart types and timeframes. It is specifically designed for cryptocurrency markets using proprietary algorithms optimized for digital asset volatility characteristics.