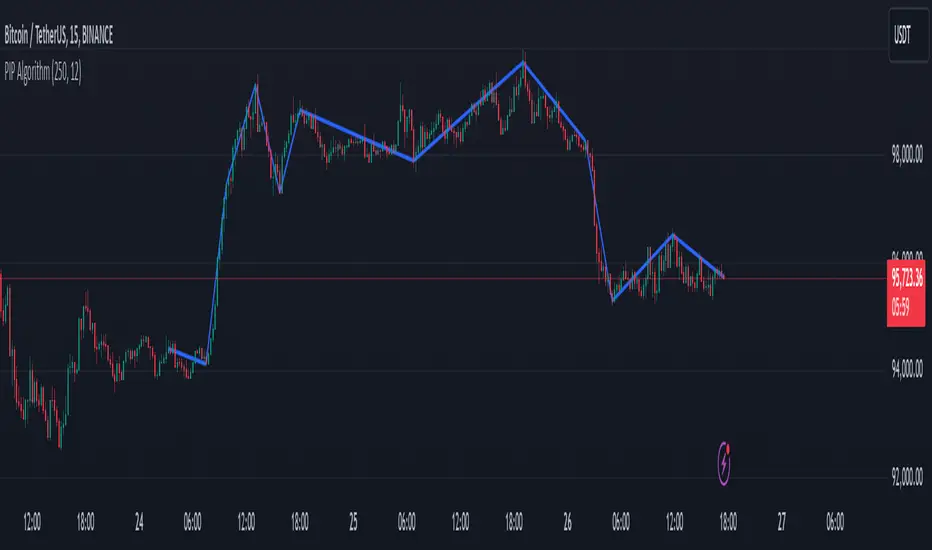
PIP Algorithm
# **Script Overview (For Non-Coders)**
1. **Purpose**
- The script tries to capture the essential “shape” of price movement by selecting a limited number of “key points” (anchors) from the latest bars.
- After selecting these anchors, it draws straight lines between them, effectively simplifying the price chart into a smaller set of points without losing major swings.
2. **How It Works, Step by Step**
1. We look back a certain number of bars (e.g., 50).
2. We start by drawing a straight line from the **oldest** bar in that range to the **newest** bar—just two points.
3. Next, we find the bar whose price is *farthest away* from that straight line. That becomes a new anchor point.
4. We “snap” (pin) the line to go exactly through that new anchor. Then we re-draw (re-interpolate) the entire line from the first anchor to the last, in segments.
5. We repeat the process (adding more anchors) until we reach the desired number of points. Each time, we choose the biggest gap between our line and the actual price, then re-draw the entire shape.
6. Finally, we connect these anchors on the chart with red lines, visually simplifying the price curve.
3. **Why It’s Useful**
- It highlights the most *important* bends or swings in the price over the chosen window.
- Instead of plotting every single bar, it condenses the information down to the “key turning points.”
4. **Key Takeaway**
- You’ll see a small number of red line segments connecting the **most significant** points in the price data.
- This is especially helpful if you want a simplified view of recent price action without minor fluctuations.
## **Detailed Logic Explanation**
# **Script Breakdown (For Coders)**
//@version=5
indicator(title="PIP Algorithm", overlay=true)
// 1. Inputs
length = input.int(50, title="Lookback Length")
num_points = input.int(5, title="Number of PIP Points (≥ 3)")
// 2. Helper Functions
// ---------------------------------------------------------------------
// reInterpSubrange(...):
// Given two “anchor” indices in `linesArr`, linearly interpolate
// the array values in between so that the subrange forms a straight line
// from linesArr to linesArr .
reInterpSubrange(linesArr, segmentLeft, segmentRight) =>
float leftVal = array.get(linesArr, segmentLeft)
float rightVal = array.get(linesArr, segmentRight)
int segmentLen = segmentRight - segmentLeft
if segmentLen > 1
for i = segmentLeft + 1 to segmentRight - 1
float ratio = (i - segmentLeft) / segmentLen
float interpVal = leftVal + (rightVal - leftVal) * ratio
array.set(linesArr, i, interpVal)
// reInterpolateAllSegments(...):
// For the entire “linesArr,” re-interpolate each subrange between
// consecutive breakpoints in `lineBreaksArr`.
// This ensures the line is globally correct after each new anchor insertion.
reInterpolateAllSegments(linesArr, lineBreaksArr) =>
array.sort(lineBreaksArr, order.asc)
for i = 0 to array.size(lineBreaksArr) - 2
int leftEdge = array.get(lineBreaksArr, i)
int rightEdge = array.get(lineBreaksArr, i + 1)
reInterpSubrange(linesArr, leftEdge, rightEdge)
// getMaxDistanceIndex(...):
// Return the index (bar) that is farthest from the current “linesArr.”
// We skip any indices already in `lineBreaksArr`.
getMaxDistanceIndex(linesArr, closeArr, lineBreaksArr) =>
float maxDist = -1.0
int maxIdx = -1
int sizeData = array.size(linesArr)
for i = 1 to sizeData - 2
bool isBreak = false
for b = 0 to array.size(lineBreaksArr) - 1
if i == array.get(lineBreaksArr, b)
isBreak := true
break
if not isBreak
float dist = math.abs(array.get(linesArr, i) - array.get(closeArr, i))
if dist > maxDist
maxDist := dist
maxIdx := i
maxIdx
// snapAndReinterpolate(...):
// "Snap" a chosen index to its actual close price, then re-interpolate the entire line again.
snapAndReinterpolate(linesArr, closeArr, lineBreaksArr, idxToSnap) =>
if idxToSnap >= 0
float snapVal = array.get(closeArr, idxToSnap)
array.set(linesArr, idxToSnap, snapVal)
reInterpolateAllSegments(linesArr, lineBreaksArr)
// 3. Global Arrays and Flags
// ---------------------------------------------------------------------
// We store final data globally, then use them outside the barstate.islast scope to draw lines.
var float finalCloseData = array.new_float()
var float finalLines = array.new_float()
var int finalLineBreaks = array.new_int()
var bool didCompute = false
var line pipLines = array.new_line()
// 4. Main Logic (Runs Once at the End of the Current Bar)
// ---------------------------------------------------------------------
if barstate.islast
// A) Prepare closeData in forward order (index 0 = oldest bar, index length-1 = newest)
float closeData = array.new_float()
for i = 0 to length - 1
array.push(closeData, close )
// B) Initialize linesArr with a simple linear interpolation from the first to the last point
float linesArr = array.new_float()
float firstClose = array.get(closeData, 0)
float lastClose = array.get(closeData, length - 1)
for i = 0 to length - 1
float ratio = (length > 1) ? (i / float(length - 1)) : 0.0
float val = firstClose + (lastClose - firstClose) * ratio
array.push(linesArr, val)
// C) Initialize lineBreaks with two anchors: 0 (oldest) and length-1 (newest)
int lineBreaks = array.new_int()
array.push(lineBreaks, 0)
array.push(lineBreaks, length - 1)
// D) Iteratively insert new breakpoints, always re-interpolating globally
int iterationsNeeded = math.max(num_points - 2, 0)
for _iteration = 1 to iterationsNeeded
// 1) Re-interpolate entire shape, so it's globally up to date
reInterpolateAllSegments(linesArr, lineBreaks)
// 2) Find the bar with the largest vertical distance to this line
int maxDistIdx = getMaxDistanceIndex(linesArr, closeData, lineBreaks)
if maxDistIdx == -1
break
// 3) Insert that bar index into lineBreaks and snap it
array.push(lineBreaks, maxDistIdx)
array.sort(lineBreaks, order.asc)
snapAndReinterpolate(linesArr, closeData, lineBreaks, maxDistIdx)
// E) Save results into global arrays for line drawing outside barstate.islast
array.clear(finalCloseData)
array.clear(finalLines)
array.clear(finalLineBreaks)
for i = 0 to array.size(closeData) - 1
array.push(finalCloseData, array.get(closeData, i))
array.push(finalLines, array.get(linesArr, i))
for b = 0 to array.size(lineBreaks) - 1
array.push(finalLineBreaks, array.get(lineBreaks, b))
didCompute := true
// 5. Drawing the Lines in Global Scope
// ---------------------------------------------------------------------
// We cannot create lines inside barstate.islast, so we do it outside.
array.clear(pipLines)
if didCompute
// Connect each pair of anchors with red lines
if array.size(finalLineBreaks) > 1
for i = 0 to array.size(finalLineBreaks) - 2
int idxLeft = array.get(finalLineBreaks, i)
int idxRight = array.get(finalLineBreaks, i + 1)
float x1 = bar_index - (length - 1) + idxLeft
float x2 = bar_index - (length - 1) + idxRight
float y1 = array.get(finalCloseData, idxLeft)
float y2 = array.get(finalCloseData, idxRight)
line ln = line.new(x1, y1, x2, y2, extend=extend.none)
line.set_color(ln, color.red)
line.set_width(ln, 2)
array.push(pipLines, ln)
1. **Data Collection**
- We collect the **most recent** `length` bars in `closeData`. Index 0 is the oldest bar in that window, index `length-1` is the newest bar.
2. **Initial Straight Line**
- We create an array called `linesArr` that starts as a simple linear interpolation from `closeData ` (the oldest bar’s close) to `closeData ` (the newest bar’s close).
3. **Line Breaks**
- We store “anchor points” in `lineBreaks`, initially ` `. These are the start and end of our segment.
4. **Global Re-Interpolation**
- Each time we want to add a new anchor, we **re-draw** (linear interpolation) for *every* subrange ` [lineBreaks , lineBreaks ]`, ensuring we have a globally consistent line.
- This avoids the “local subrange only” approach, which can cause clustering near existing anchors.
5. **Finding the Largest Distance**
- After re-drawing, we compute the vertical distance for each bar `i` that isn’t already a line break. The bar with the biggest distance from the line is chosen as the next anchor (`maxDistIdx`).
6. **Snapping and Re-Interpolate**
- We “snap” that bar’s line value to the actual close, i.e. `linesArr = closeData `. Then we globally re-draw all segments again.
7. **Repeat**
- We repeat these insertions until we have the desired number of points (`num_points`).
8. **Drawing**
- Finally, we connect each consecutive pair of anchor points (`lineBreaks`) with a `line.new(...)` call, coloring them red.
- We offset the line’s `x` coordinate so that the anchor at index 0 lines up with `bar_index - (length - 1)`, and the anchor at index `length-1` lines up with `bar_index` (the current bar).
**Result**:
You get a simplified representation of the price with a small set of line segments capturing the largest “jumps” or swings. By re-drawing the entire line after each insertion, the anchors tend to distribute more *evenly* across the data, mitigating the issue where anchors bunch up near each other.
Enjoy experimenting with different `length` and `num_points` to see how the simplified lines change!
Cerca negli script per "bar"
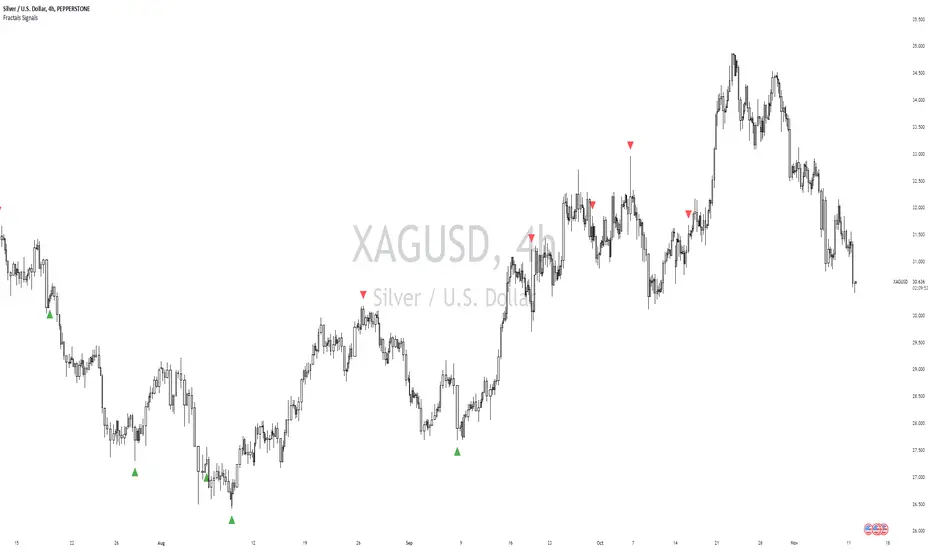
William Fractals + SignalsWilliams Fractals + Trading Signals
This indicator identifies Williams Fractals and generates trading signals based on price sweeps of these fractal levels.
Williams Fractals are specific candlestick patterns that identify potential market turning points. Each fractal requires a minimum of 5 bars (2 before, 1 center, 2 after), though this indicator allows you to customize the number of bars checked.
Up Fractal (High Point) forms when you have a center bar whose HIGH is higher than the highs of 'n' bars before and after it. For example, with n=2, you'd see a pattern where the center bar's high is higher than 2 bars before and 2 bars after it. The indicator also recognizes patterns where up to 4 bars after the center can have equal highs before requiring a lower high.
Down Fractal (Low Point) forms when you have a center bar whose LOW is lower than the lows of 'n' bars before and after it. For example, with n=2, you'd see a pattern where the center bar's low is lower than 2 bars before and 2 bars after it. The indicator also recognizes patterns where up to 4 bars after the center can have equal lows before requiring a higher low.
Trading Signals:
The indicator generates signals when price "sweeps" these fractal levels:
Buy Signal (Green Triangle) triggers when price sweeps a down fractal. This requires price to go BELOW the down fractal's low level and then CLOSE ABOVE it . This pattern often indicates a failed breakdown and potential reversal upward.
Sell Signal (Red Triangle) triggers when price sweeps an up fractal. This requires price to go ABOVE the up fractal's high level and then CLOSE BELOW it. This pattern often indicates a failed breakout and potential reversal downward.
Customizable Settings:
1. Periods (default: 10) - How many bars to check before and after the center bar (minimum value: 2)
2. Maximum Stored Fractals (default: 1) - How many fractal levels to keep in memory. Older levels are removed when this limit is reached to prevent excessive signals and maintain indicator performance.
Important Notes:
• The indicator checks the actual HIGH and LOW prices of each bar, not just closing prices
• Fractal levels are automatically removed after generating a signal to prevent repeated triggers
• Signals are only generated on bar close to avoid false triggers
• Alerts include the ticker symbol and the exact price level where the sweep occurred
Common Use Cases:
• Identifying potential reversal points
• Finding stop-hunt levels where price might reverse
• Setting stop-loss levels above up fractals or below down fractals
• Trading failed breakouts/breakdowns at fractal levels
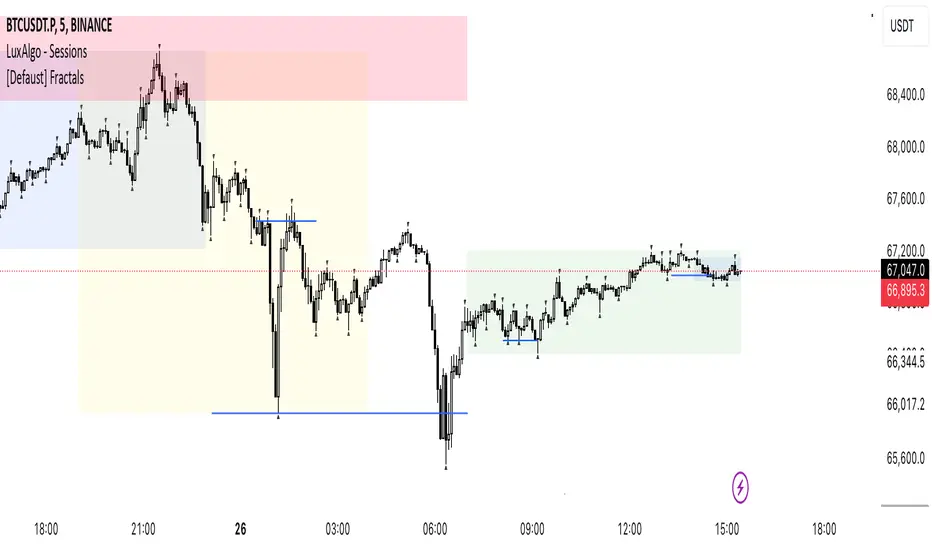
[Defaust] Fractals Fractals Indicator
Overview
The Fractals Indicator is a technical analysis tool designed to help traders identify potential reversal points in the market by detecting fractal patterns. This indicator is a fork of the original fractals indicator, with adjustments made to the plotting for enhanced visual clarity and usability.
What Are Fractals?
In trading, a fractal is a pattern consisting of five consecutive bars (candlesticks) that meet specific conditions:
Up Fractal (Potential Sell Signal): Occurs when a high point is surrounded by two lower highs on each side.
Down Fractal (Potential Buy Signal): Occurs when a low point is surrounded by two higher lows on each side.
Fractals help traders identify potential tops and bottoms in the market, signaling possible entry or exit points.
Features of the Indicator
Customizable Periods (n): Allows you to define the number of periods to consider when detecting fractals, offering flexibility to adapt to different trading strategies and timeframes.
Enhanced Plotting Adjustments: This fork introduces adjustments to the plotting of fractal signals for better visual representation on the chart.
Visual Signals: Plots up and down triangles on the chart to signify down fractals (potential bullish signals) and up fractals (potential bearish signals), respectively.
Overlay on Chart: The fractal signals are overlaid directly on the price chart for immediate visualization.
Adjustable Precision: You can set the precision of the plotted values according to your needs.
Pine Script Code Explanation
Below is the Pine Script code for the Fractals Indicator:
//@version=5 indicator(" Fractals", shorttitle=" Fractals", format=format.price, precision=0, overlay=true)
// User input for the number of periods to consider for fractal detection n = input.int(title="Periods", defval=2, minval=2)
// Initialize flags for up fractal detection bool upflagDownFrontier = true bool upflagUpFrontier0 = true bool upflagUpFrontier1 = true bool upflagUpFrontier2 = true bool upflagUpFrontier3 = true bool upflagUpFrontier4 = true
// Loop through previous and future bars to check conditions for up fractals for i = 1 to n // Check if the highs of previous bars are less than the current bar's high upflagDownFrontier := upflagDownFrontier and (high < high ) // Check various conditions for future bars upflagUpFrontier0 := upflagUpFrontier0 and (high < high ) upflagUpFrontier1 := upflagUpFrontier1 and (high <= high and high < high ) upflagUpFrontier2 := upflagUpFrontier2 and (high <= high and high <= high and high < high ) upflagUpFrontier3 := upflagUpFrontier3 and (high <= high and high <= high and high <= high and high < high ) upflagUpFrontier4 := upflagUpFrontier4 and (high <= high and high <= high and high <= high and high <= high and high < high )
// Combine the flags to determine if an up fractal exists flagUpFrontier = upflagUpFrontier0 or upflagUpFrontier1 or upflagUpFrontier2 or upflagUpFrontier3 or upflagUpFrontier4 upFractal = (upflagDownFrontier and flagUpFrontier)
// Initialize flags for down fractal detection bool downflagDownFrontier = true bool downflagUpFrontier0 = true bool downflagUpFrontier1 = true bool downflagUpFrontier2 = true bool downflagUpFrontier3 = true bool downflagUpFrontier4 = true
// Loop through previous and future bars to check conditions for down fractals for i = 1 to n // Check if the lows of previous bars are greater than the current bar's low downflagDownFrontier := downflagDownFrontier and (low > low ) // Check various conditions for future bars downflagUpFrontier0 := downflagUpFrontier0 and (low > low ) downflagUpFrontier1 := downflagUpFrontier1 and (low >= low and low > low ) downflagUpFrontier2 := downflagUpFrontier2 and (low >= low and low >= low and low > low ) downflagUpFrontier3 := downflagUpFrontier3 and (low >= low and low >= low and low >= low and low > low ) downflagUpFrontier4 := downflagUpFrontier4 and (low >= low and low >= low and low >= low and low >= low and low > low )
// Combine the flags to determine if a down fractal exists flagDownFrontier = downflagUpFrontier0 or downflagUpFrontier1 or downflagUpFrontier2 or downflagUpFrontier3 or downflagUpFrontier4 downFractal = (downflagDownFrontier and flagDownFrontier)
// Plot the fractal symbols on the chart with adjusted plotting plotshape(downFractal, style=shape.triangleup, location=location.belowbar, offset=-n, color=color.gray, size=size.auto) plotshape(upFractal, style=shape.triangledown, location=location.abovebar, offset=-n, color=color.gray, size=size.auto)
Explanation:
Input Parameter (n): Sets the number of periods for fractal detection. The default value is 2, and it must be at least 2 to ensure valid fractal patterns.
Flag Initialization: Boolean variables are used to store intermediate conditions during fractal detection.
Loops: Iterate through the specified number of periods to evaluate the conditions for fractal formation.
Conditions:
Up Fractals: Checks if the current high is greater than previous highs and if future highs are lower or equal to the current high.
Down Fractals: Checks if the current low is lower than previous lows and if future lows are higher or equal to the current low.
Flag Combination: Logical and and or operations are used to combine the flags and determine if a fractal exists.
Adjusted Plotting:
The plotting of fractal symbols has been adjusted for better alignment and visual clarity.
The offset parameter is set to -n to align the plotted symbols with the correct bars.
The color and size have been fine-tuned for better visibility.
How to Use the Indicator
Adding the Indicator to Your Chart
Open TradingView:
Go to TradingView.
Access the Chart:
Click on "Chart" to open the main charting interface.
Add the Indicator:
Click on the "Indicators" button at the top.
Search for " Fractals".
Select the indicator from the list to add it to your chart.
Configuring the Indicator
Periods (n):
Default value is 2.
Adjust this parameter based on your preferred timeframe and sensitivity.
A higher value of n considers more bars for fractal detection, potentially reducing the number of signals but increasing their significance.
Interpreting the Signals
– Up Fractal (Downward Triangle): Indicates a potential price reversal to the downside. May be used as a signal to consider exiting long positions or tightening stop-loss orders.
– Down Fractal (Upward Triangle): Indicates a potential price reversal to the upside. May be used as a signal to consider entering long positions or setting stop-loss orders for short positions.
Trading Strategy Suggestions
Up Fractal Detection:
The high of the current bar (n) is higher than the highs of the previous two bars (n - 1, n - 2).
The highs of the next bars meet certain conditions to confirm the fractal pattern.
An up fractal symbol (downward triangle) is plotted above the bar at position n - n (due to the offset).
Down Fractal Detection:
The low of the current bar (n) is lower than the lows of the previous two bars (n - 1, n - 2).
The lows of the next bars meet certain conditions to confirm the fractal pattern.
A down fractal symbol (upward triangle) is plotted below the bar at position n - n.
Benefits of Using the Fractals Indicator
Early Signals: Helps in identifying potential reversal points in price movements.
Customizable Sensitivity: Adjusting the n parameter allows you to fine-tune the indicator based on different market conditions.
Enhanced Visuals: Adjustments to plotting improve the clarity and readability of fractal signals on the chart.
Limitations and Considerations
Lagging Indicator: Fractals require future bars to confirm the pattern, which may introduce a delay in the signals.
False Signals: In volatile or ranging markets, fractals may produce false signals. It's advisable to use them in conjunction with other analysis tools.
Not a Standalone Tool: Fractals should be part of a broader trading strategy that includes other indicators and fundamental analysis.
Best Practices for Using This Indicator
Combine with Other Indicators: Use in combination with trend indicators, oscillators, or volume analysis to confirm signals.
Backtesting: Before applying the indicator in live trading, backtest it on historical data to understand its performance.
Adjust Periods Accordingly: Experiment with different values of n to find the optimal setting for the specific asset and timeframe you are trading.
Disclaimer
The Fractals Indicator is intended for educational and informational purposes only. Trading involves significant risk, and you should be aware of the risks involved before proceeding. Past performance is not indicative of future results. Always conduct your own analysis and consult with a professional financial advisor before making any investment decisions.
Credits
This indicator is a fork of the original fractals indicator, with adjustments made to the plotting for improved visual representation. It is based on standard fractal patterns commonly used in technical analysis and has been developed to provide traders with an effective tool for detecting potential reversal points in the market.
WaveTrend With Divs & RSI(STOCH) Divs by WeloTradesWaveTrend with Divergences & RSI(STOCH) Divergences by WeloTrades
Overview
The "WaveTrend With Divergences & RSI(STOCH) Divergences" is an advanced Pine Script™ indicator designed for TradingView, offering a multi-dimensional analysis of market conditions. This script integrates several technical indicators—WaveTrend, Money Flow Index (MFI), RSI, and Stochastic RSI—into a cohesive tool that identifies both regular and hidden divergences across these indicators. These divergences can indicate potential market reversals and provide critical trading opportunities.
This indicator is not just a simple combination of popular tools; it offers extensive customization options, organized data presentation, and valuable trading signals that are easy to interpret. Whether you're a day trader or a long-term investor, this script enhances your ability to make informed decisions.
Originality and Usefulness
The originality of this script lies in its integration and the synergy it creates among the indicators used. Rather than merely combining multiple indicators, this script allows them to work together, enhancing each other's strengths. For example, by identifying divergences across WaveTrend, RSI, and Stochastic RSI simultaneously, the script provides multiple layers of confirmation, which reduces the likelihood of false signals and increases the reliability of trading signals.
The usefulness of this script is apparent in its ability to offer a consolidated view of market dynamics. It not only simplifies the analytical process by combining different indicators but also provides deeper insights through its divergence detection features. This comprehensive approach is designed to help traders identify potential market reversals, confirm trends, and ultimately make more informed trading decisions.
How the Components Work Together
1. Cross-Validation of Signals
WaveTrend: This indicator is primarily used to identify overbought and oversold conditions, as well as potential buy and sell signals. WaveTrend's ability to smooth price data and reduce noise makes it a reliable tool for identifying trend reversals.
RSI & Stochastic RSI: These momentum oscillators are used to measure the speed and change of price movements. While RSI identifies general overbought and oversold conditions, Stochastic RSI offers a more granular view by tracking the RSI’s level relative to its high-low range over a period of time. When these indicators align with WaveTrend signals, it adds a layer of confirmation that enhances the reliability of the signals.
Money Flow Index (MFI): This volume-weighted indicator assesses the inflow and outflow of money in an asset, giving insights into buying and selling pressure. By analyzing the MFI alongside WaveTrend and RSI indicators, the script can cross-validate signals, ensuring that buy or sell signals are supported by actual market volume.
Example Bullish scenario:
When a bullish divergence is detected on the RSI and confirmed by a corresponding bullish signal on the WaveTrend, along with an increasing Money Flow Index, the probability of a successful trade setup increases. This cross-validation minimizes the risk of acting on false signals, which might occur when relying on a single indicator.
Example Bearish scenario:
When a bearish divergence is detected on the RSI and confirmed by a corresponding bearish signal on the WaveTrend, along with an decreasing Money Flow Index, the probability of a successful trade setup increases. This cross-validation minimizes the risk of acting on false signals, which might occur when relying on a single indicator.
2. Divergence Detection and Market Reversals
Regular Divergences: Occur when the price action and an indicator (like RSI or WaveTrend) move in opposite directions. Regular bullish divergence signals a potential upward reversal when the price makes a lower low while the indicator makes a higher low. Conversely, regular bearish divergence suggests a downward reversal when the price makes a higher high, but the indicator makes a lower high.
Hidden Divergences: These occur when the price action and indicator move in the same direction, but with different momentum. Hidden bullish divergence suggests the continuation of an uptrend, while hidden bearish divergence suggests the continuation of a downtrend. By detecting these divergences across multiple indicators, the script identifies potential trend reversals or continuations with greater accuracy.
Example: The script might detect a regular bullish divergence on the WaveTrend while simultaneously identifying a hidden bullish divergence on the RSI. This combination suggests that while a trend reversal is possible, the overall market sentiment remains bullish, providing a nuanced view of the market.
A Regular Bullish Divergence Example:
A Hidden Bullish Divergence Example:
A Regular Bearish Divergence Example:
A Hidden Bearish Divergence Example:
3. Trend Strength and Sentiment Analysis
WaveTrend: Measures the strength and direction of the trend. By identifying the extremes of market sentiment (overbought and oversold levels), WaveTrend provides early signals for potential reversals.
Money Flow Index (MFI): Assesses the underlying sentiment by analyzing the flow of money. A rising MFI during an uptrend confirms strong buying pressure, while a falling MFI during a downtrend confirms selling pressure. This helps traders assess whether a trend is likely to continue or reverse.
RSI & Stochastic RSI: Offer a momentum-based perspective on the trend’s strength. High RSI or Stochastic RSI values indicate that the asset may be overbought, suggesting a potential reversal. Conversely, low values indicate oversold conditions, signaling a possible upward reversal.
Example:
During a strong uptrend, the WaveTrend & RSI's might signal overbought conditions, suggesting caution. If the MFI also shows decreasing buying pressure and the RSI reaches extreme levels, these indicators together suggest that the trend might be weakening, and a reversal could be imminent.
Example:
During a strong downtrend, the WaveTrend & RSI's might signal oversold conditions, suggesting caution. If the MFI also shows increasing buying pressure and the RSI reaches extreme levels, these indicators together suggest that the trend might be weakening, and a reversal could be imminent.
Conclusion
The "WaveTrend With Divergences & RSI(STOCH) Divergences" script offers a powerful, integrated approach to technical analysis by combining trend, momentum, and sentiment indicators into a single tool. Its unique value lies in the cross-validation of signals, the ability to detect divergences, and the comprehensive view it provides of market conditions. By offering traders multiple layers of analysis and customization options, this script is designed to enhance trading decisions, reduce false signals, and provide clearer insights into market dynamics.
WAVETREND
Display of WaveTrend:
Display of WaveTrend Setting:
WaveTrend Indicator Explanation
The WaveTrend indicator helps identify overbought and oversold conditions, as well as potential buy and sell signals. Its flexibility allows traders to adapt it to various strategies, making it a versatile tool in technical analysis.
WaveTrend Input Settings:
WT MA Source: Default: HLC3
What it is: The data source used for calculating the WaveTrend Moving Average.
What it does: Determines the input data to smooth price action and filter noise.
Example: Using HLC3 (average of High, Low, Close) provides a smoother data representation compared to using just the closing price.
Length (WT MA Length): Default: 3
What it is: The period used to calculate the Moving Average.
What it does: Adjusts the sensitivity of the WaveTrend indicator, where shorter lengths respond more quickly to price changes.
Example: A length of 3 is ideal for short-term analysis, providing quick reactions to price movements.
WT Channel Length & Average: Default: WT Channel Length = 9, Average = 12
What it is: Lengths used to calculate the WaveTrend channel and its average.
What it does: Smooths out the WaveTrend further, reducing false signals by averaging over a set period.
Example: Higher values reduce noise and help in identifying more reliable trends.
Channel: Style, Width, and Color:
What it is: Customization options for the WaveTrend channel's appearance.
What it does: Adjusts how the channel is displayed, including line style, width, and color.
Example: Choosing an area style with a distinct color can make the WaveTrend indicator clearly visible on the chart.
WT Buy & Sell Signals:
What it is: Settings to enable and customize buy and sell signals based on WaveTrend.
What it does: Allows for the display of buy/sell signals and customization of their shapes and colors.
When it gives a Buy Signal: Generated when the WaveTrend line crosses below an oversold level and then rises back, indicating a potential upward price movement.
When it gives a Sell Signal: Triggered when the WaveTrend line crosses above an overbought level and then declines, suggesting a possible downward trend.
Example: The script identifies these signals based on mean reversion principles, where prices tend to revert to the mean after reaching extremes. Traders can use these signals to time their entries and exits effectively.
WAVETREND OVERBOUGTH AND OVERSOLD LEVELS
Display of WaveTrend with Overbought & Oversold Levels:
Display of WaveTrend Overbought & Oversold Levels Settings:
WaveTrend Overbought & Oversold Levels Explanation
WT OB & OS Levels: Default: OB Level 1 = 53, OB Level 2 = 60, OS Level 1 = -53, OS Level 2 = -60
What it is: The default overbought and oversold levels used by the WaveTrend indicator to signal potential market reversals.
What it does: When the WaveTrend crosses above the OB levels, it indicates an overbought condition, potentially signaling a reversal or selling opportunity. Conversely, when it crosses below the OS levels, it indicates an oversold condition, potentially signaling a reversal or buying opportunity.
Example: A trader might use these levels to time entry or exit points, such as selling when the WaveTrend crosses into the overbought zone or buying when it crosses into the oversold zone.
Show OB/OS Levels: Default: True
What it is: Toggle options to show or hide the overbought and oversold levels on your chart.
What it does: When enabled, these levels will be visually represented on your chart, helping you to easily identify when the market reaches these critical thresholds.
Example: Displaying these levels can help you quickly see when the WaveTrend is approaching or has crossed into overbought or oversold territory, allowing for more informed trading decisions.
Line Style, Width, and Color for OB/OS Levels:
What it is: Options to customize the appearance of the OB and OS levels on your chart, including line style (solid, dotted, dashed), line width, and color.
What it does: These settings allow you to adjust how prominently these levels are displayed on your chart, which can help you better visualize and respond to overbought or oversold conditions.
Example: Setting a thicker, dashed line in a contrasting color can make these levels stand out more clearly, aiding in quick visual identification.
Example of Use:
Scenario: A trader wants to identify potential selling points when the market is overbought. They set the OB levels at 53 and 60, choosing a solid, red line style to make these levels clear on their chart. As the WaveTrend crosses above 53, they monitor for further price action, and upon crossing 60, they consider initiating a sell order.
WAVETREND DIVERGENCES
Display of WaveTrend Divergence:
Display of WaveTrend Divergence Setting:
WaveTrend Divergence Indicator Explanation
The WaveTrend Divergence feature helps identify potential reversal points in the market by highlighting divergences between the price and the WaveTrend indicator. Divergences can signal a shift in market momentum, indicating a possible trend reversal. This component allows traders to visualize and customize divergence detection on their charts.
WaveTrend Divergence Input Settings:
Potential Reversal Range: Default: 28
What it is: The number of bars to look back when detecting potential tops and bottoms.
What it does: Sets the range for identifying possible reversal points based on historical data.
Example: A setting of 28 looks back across the last 28 bars to find reversal points, offering a balance between responsiveness and reliability.
Reversal Minimum LVL OB & OS: Default: OB = 35, OS = -35
What it is: The minimum overbought and oversold levels required for detecting potential reversals.
What it does: Adjusts the thresholds that trigger a reversal signal based on the WaveTrend indicator.
Example: A higher OB level reduces the sensitivity to overbought conditions, potentially filtering out false reversal signals.
Lookback Bar Left & Right: Default: Left = 10, Right = 1
What it is: The number of bars to the left and right used to confirm a top or bottom.
What it does: Helps determine the position of peaks and troughs in the price action.
Example: A larger left lookback captures more extended price action before the peak, while a smaller right lookback focuses on the immediate past.
Lookback Range Min & Max: Default: Min = 5, Max = 60
What it is: The minimum and maximum range for the lookback period when identifying divergences.
What it does: Fine-tunes the detection of divergences by controlling the range over which the indicator looks back.
Example: A wider range increases the chances of detecting divergences across different market conditions.
R.Div Minimum LVL OB & OS: Default: OB = 53, OS = -53
What it is: The threshold levels for detecting regular divergences.
What it does: Adjusts the sensitivity of the regular divergence detection.
Example: Higher thresholds make the detection more conservative, identifying only stronger divergence signals.
H.Div Minimum LVL OB & OS: Default: OB = 20, OS = -20
What it is: The threshold levels for detecting hidden divergences.
What it does: Similar to regular divergence settings but for hidden divergences, which can indicate potential reversals that are less obvious.
Example: Lower thresholds make the hidden divergence detection more sensitive, capturing subtler market shifts.
Divergence Label Options:
What it is: Options to display and customize labels for regular and hidden divergences.
What it does: Allows users to visually differentiate between regular and hidden divergences using customizable labels and colors.
Example: Using different colors and symbols for regular (R) and hidden (H) divergences makes it easier to interpret signals on the chart.
Text Size and Color:
What it is: Customization options for the size and color of divergence labels.
What it does: Adjusts the readability and visibility of divergence labels on the chart.
Example: Larger text size may be preferred for charts with a lot of data, ensuring divergence labels stand out clearly.
FAST & SLOW MONEY FLOW INDEX
Display of Fast & Slow Money Flow:
Display of Fast & Slow Money Flow Setting:
Fast Money Flow Indicator Explanation
The Fast Money Flow indicator helps traders identify the flow of money into and out of an asset over a shorter time frame. By tracking the volume-weighted average of price movements, it provides insights into buying and selling pressure in the market, which can be crucial for making timely trading decisions.
Fast Money Flow Input Settings:
Fast Money Flow: Length: Default: 9
What it is: The period used for calculating the Fast Money Flow.
What it does: Determines the sensitivity of the Money Flow calculation. A shorter length makes the indicator more responsive to recent price changes, while a longer length provides a smoother signal.
Example: A length of 9 is suitable for traders looking to capture quick shifts in market sentiment over a short period.
Fast MFI Area Multiplier: Default: 5
What it is: A multiplier applied to the Money Flow area calculation.
What it does: Adjusts the size of the Money Flow area on the chart, effectively amplifying or reducing the visual impact of the indicator.
Example: A higher multiplier can make the Money Flow more prominent on the chart, aiding in the quick identification of significant money flow changes.
Y Position (Y Pos): Default: 0
What it is: The vertical position adjustment for the Fast Money Flow plot on the chart.
What it does: Allows you to move the Money Flow plot up or down on the chart to avoid overlap with other indicators.
Example: Adjusting the Y Position can be useful if you have multiple indicators on the chart and need to maintain clarity.
Fast MFI Style, Width, and Color:
What it is: Customization options for how the Fast Money Flow is displayed on the chart.
What it does: Enables you to choose between different plot styles (line or area), set the line width, and select colors for positive and negative money flow.
Example: Using different colors for positive (green) and negative (red) money flow helps to visually distinguish between periods of buying and selling pressure.
Slow Money Flow Indicator Explanation
The Slow Money Flow indicator tracks the flow of money into and out of an asset over a longer time frame. It provides a broader perspective on market sentiment, smoothing out short-term fluctuations and highlighting longer-term trends.
Slow Money Flow Input Settings:
Slow Money Flow: Length: Default: 12
What it is: The period used for calculating the Slow Money Flow.
What it does: A longer period smooths out short-term fluctuations, providing a clearer view of the overall money flow trend.
Example: A length of 12 is often used by traders looking to identify sustained trends rather than short-term volatility.
Slow MFI Area Multiplier: Default: 5
What it is: A multiplier applied to the Slow Money Flow area calculation.
What it does: Adjusts the size of the Money Flow area on the chart, helping to emphasize the indicator’s significance.
Example: Increasing the multiplier can help highlight the Money Flow in markets with less volatile price action.
Y Position (Y Pos): Default: 0
What it is: The vertical position adjustment for the Slow Money Flow plot on the chart.
What it does: Allows for vertical repositioning of the Money Flow plot to maintain chart clarity when used with other indicators.
Example: Adjusting the Y Position ensures that the Slow Money Flow indicator does not overlap with other key indicators on the chart.
Slow MFI Style, Width, and Color:
What it is: Customization options for the visual display of the Slow Money Flow on the chart.
What it does: Allows you to choose the plot style (line or area), set the line width, and select colors to differentiate positive and negative money flow.
Example: Customizing the colors for the Slow Money Flow allows traders to quickly distinguish between buying and selling trends in the market.
RSI
Display of RSI:
Display of RSI Setting:
RSI Indicator Explanation
The Relative Strength Index (RSI) is a momentum oscillator that measures the speed and change of price movements. It is typically used to identify overbought or oversold conditions in the market, providing traders with potential signals for buying or selling.
RSI Input Settings:
RSI Source: Default: Close
What it is: The data source used for calculating the RSI.
What it does: Determines which price data (e.g., close, open) is used in the RSI calculation, affecting how the indicator reflects market conditions.
Example: Using the closing price is standard practice, as it reflects the final agreed-upon price for a given time period.
MA Type (Moving Average Type): Default: SMA
What it is: The type of moving average applied to the RSI for smoothing purposes.
What it does: Changes the smoothing technique of the RSI, impacting how quickly the indicator responds to price movements.
Example: Using an Exponential Moving Average (EMA) will make the RSI more sensitive to recent price changes compared to a Simple Moving Average (SMA).
RSI Length: Default: 14
What it is: The period over which the RSI is calculated.
What it does: Adjusts the sensitivity of the RSI. A shorter length (e.g., 7) makes the RSI more responsive to recent price changes, while a longer length (e.g., 21) smooths out the indicator, reducing the number of signals.
Example: A 14-period RSI is commonly used for identifying overbought and oversold conditions, providing a balance between sensitivity and reliability.
RSI Plot Style, Width, and Color:
What it is: Options to customize the appearance of the RSI line on the chart.
What it does: Allows you to adjust the visual representation of the RSI, including the line width and color.
Example: Setting a thicker line width and a bright color like yellow can make the RSI more visible on the chart, aiding in quick analysis.
Display of RSI with RSI Moving Average:
RSI Moving Average Explanation
The RSI Moving Average adds a smoothing layer to the RSI, helping to filter out noise and provide clearer signals. It is particularly useful for confirming trend strength and identifying potential reversals.
RSI Moving Average Input Settings:
MA Length: Default: 14
What it is: The period over which the Moving Average is calculated on the RSI.
What it does: Adjusts the smoothing of the RSI, helping to reduce false signals and provide a clearer trend indication.
Example: A 14-period moving average on the RSI can smooth out short-term fluctuations, making it easier to spot genuine overbought or oversold conditions.
MA Plot Style, Width, and Color:
What it is: Customization options for how the RSI Moving Average is displayed on the chart.
What it does: Allows you to adjust the line width and color, helping to differentiate the Moving Average from the main RSI line.
Example: Using a contrasting color for the RSI Moving Average (e.g., magenta) can help it stand out against the main RSI line, making it easier to interpret the indicator.
STOCHASTIC RSI
Display of Stochastic RSI:
Display of Stochastic RSI Setting:
Stochastic RSI Indicator Explanation
The Stochastic RSI (Stoch RSI) is a momentum oscillator that measures the level of the RSI relative to its high-low range over a set period of time. It is used to identify overbought and oversold conditions, providing potential buy and sell signals based on momentum shifts.
Stochastic RSI Input Settings:
Stochastic RSI Length: Default: 14
What it is: The period over which the Stochastic RSI is calculated.
What it does: Adjusts the sensitivity of the Stochastic RSI. A shorter length makes the indicator more responsive to recent price changes, while a longer length smooths out the fluctuations, reducing noise.
Example: A length of 14 is commonly used to identify momentum shifts over a medium-term period, providing a balanced view of potential overbought or oversold conditions.
Display of Stochastic RSI %K Line:
Stochastic RSI %K Line Explanation
The %K line in the Stochastic RSI is the main line that tracks the momentum of the RSI over the chosen period. It is the faster-moving component of the Stochastic RSI, often used to identify entry and exit points.
Stochastic RSI %K Input Settings:
%K Length: Default: 3
What it is: The period used for smoothing the %K line of the Stochastic RSI.
What it does: Smoothing the %K line helps reduce noise and provides a clearer signal for potential market reversals.
Example: A smoothing length of 3 is common, offering a balance between responsiveness and noise reduction, making it easier to spot significant momentum shifts.
%K Plot Style, Width, and Color:
What it is: Customization options for the visual representation of the %K line.
What it does: Allows you to adjust the appearance of the %K line on the chart, including line width and color, to fit your visual preferences.
Example: Setting a blue color and a medium width for the %K line makes it stand out clearly on the chart, helping to identify key points of momentum change.
%K Fill Color (Above):
What it is: The fill color that appears above the %K line on the chart.
What it does: Adds visual clarity by shading the area above the %K line, making it easier to interpret the direction and strength of momentum.
Example: Using a light blue fill color above the %K line can help emphasize bullish momentum, making it visually prominent.
Display of Stochastic RSI %D Line:
Stochastic RSI %D Line Explanation
The %D line in the Stochastic RSI is a moving average of the %K line and acts as a signal line. It is slower-moving compared to the %K line and is often used to confirm signals or identify potential reversals when it crosses the %K line.
Stochastic RSI %D Input Settings:
%D Length: Default: 3
What it is: The period used for smoothing the %D line of the Stochastic RSI.
What it does: Smooths out the %D line, making it less sensitive to short-term fluctuations and more reliable for identifying significant market signals.
Example: A length of 3 is often used to provide a smoothed signal line that can help confirm trends or reversals indicated by the %K line.
%D Plot Style, Width, and Color:
What it is: Customization options for the visual representation of the %D line.
What it does: Allows you to adjust the appearance of the %D line on the chart, including line width and color, to match your preferences.
Example: Setting an orange color and a thicker line width for the %D line can help differentiate it from the %K line, making crossover points easier to spot.
%D Fill Color (Below):
What it is: The fill color that appears below the %D line on the chart.
What it does: Adds visual clarity by shading the area below the %D line, making it easier to interpret bearish momentum.
Example: Using a light orange fill color below the %D line can highlight bearish conditions, making it visually easier to identify.
RSI & STOCHASTIC RSI OVERBOUGHT AND OVERSOLD LEVELS
Display of RSI & Stochastic with Overbought & Oversold Levels:
Display of RSI & Stochastic Overbought & Oversold Settings:
RSI & Stochastic Overbought & Oversold Levels Explanation
The Overbought (OB) and Oversold (OS) levels for RSI and Stochastic RSI indicators are key thresholds that help traders identify potential reversal points in the market. These levels are used to determine when an asset is likely overbought or oversold, which can signal a potential trend reversal.
RSI & Stochastic Overbought & Oversold Input Settings:
RSI & Stochastic Level 1 Overbought (OB) & Oversold (OS): Default: OB Level = 170, OS Level = 130
What it is: The first set of thresholds for determining overbought and oversold conditions for both RSI and Stochastic RSI indicators.
What it does: When the RSI or Stochastic RSI crosses above the overbought level, it suggests that the asset might be overbought, potentially signaling a sell opportunity. Conversely, when these indicators drop below the oversold level, it suggests the asset might be oversold, potentially signaling a buy opportunity.
Example: If the RSI crosses above 170, traders might look for signs of a potential trend reversal to the downside, while a cross below 130 might indicate a reversal to the upside.
RSI & Stochastic Level 2 Overbought (OB) & Oversold (OS): Default: OB Level = 180, OS Level = 120
What it is: The second set of thresholds for determining overbought and oversold conditions for both RSI and Stochastic RSI indicators.
What it does: These levels provide an additional set of reference points, allowing traders to differentiate between varying degrees of overbought and oversold conditions, potentially leading to more refined trading decisions.
Example: When the RSI crosses above 180, it might indicate an extreme overbought condition, which could be a stronger signal for a sell, while a cross below 120 might indicate an extreme oversold condition, which could be a stronger signal for a buy.
RSI & Stochastic Overbought (OB) Band Customization:
OB Level 1: Width, Style, and Color:
What it is: Customization options for the visual appearance of the first overbought band on the chart.
What it does: Allows you to set the line width, style (solid, dotted, dashed), and color for the first overbought band, enhancing its visibility on the chart.
Example: A dashed red line with medium width can clearly indicate the first overbought level, helping traders quickly identify when this threshold is crossed.
OB Level 2: Width, Style, and Color:
What it is: Customization options for the visual appearance of the second overbought band on the chart.
What it does: Allows you to set the line width, style, and color for the second overbought band, providing a clear distinction from the first band.
Example: A dashed red line with a slightly thicker width can represent a more significant overbought level, making it easier to differentiate from the first level.
RSI & Stochastic Oversold (OS) Band Customization:
OS Level 1: Width, Style, and Color:
What it is: Customization options for the visual appearance of the first oversold band on the chart.
What it does: Allows you to set the line width, style (solid, dotted, dashed), and color for the first oversold band, making it visually prominent.
Example: A dashed green line with medium width can highlight the first oversold level, helping traders identify potential buying opportunities.
OS Level 2: Width, Style, and Color:
What it is: Customization options for the visual appearance of the second oversold band on the chart.
What it does: Allows you to set the line width, style, and color for the second oversold band, providing an additional visual cue for extreme oversold conditions.
Example: A dashed green line with a thicker width can represent a more significant oversold level, offering a stronger visual cue for potential buying opportunities.
RSI DIVERGENCES
Display of RSI Divergence Labels:
Display of RSI Divergence Settings:
RSI Divergence Lookback Explanation
The RSI Divergence settings allow traders to customize the parameters for detecting divergences between the RSI (Relative Strength Index) and price action. Divergences occur when the price moves in the opposite direction to the RSI, potentially signaling a trend reversal. These settings help refine the accuracy of divergence detection by adjusting the lookback period and range. ( NOTE: This setting only imply to the RSI. This doesn't effect the STOCHASTIC RSI. )
RSI Divergence Lookback Input Settings:
Lookback Left: Default: 10
What it is: The number of bars to look back from the current bar to detect a potential divergence.
What it does: Defines the left-side lookback period for identifying pivot points in the RSI, which are used to spot divergences. A longer lookback period may capture more significant trends but could also miss shorter-term divergences.
Example: A setting of 10 bars means the script will consider pivot points up to 10 bars before the current bar to check for divergence patterns.
Lookback Right: Default: 1
What it is: The number of bars to look forward from the current bar to complete the divergence pattern.
What it does: Defines the right-side lookback period for confirming a potential divergence. This setting helps ensure that the identified divergence is valid by allowing the script to check subsequent bars for confirmation.
Example: A setting of 1 bar means the script will look at the next bar to confirm the divergence pattern, ensuring that the signal is reliable.
Lookback Range Min: Default: 5
What it is: The minimum range of bars required to detect a valid divergence.
What it does: Sets a lower bound on the range of bars considered for divergence detection. A lower minimum range might capture more frequent but possibly less significant divergences.
Example: Setting the minimum range to 5 ensures that only divergences spanning at least 5 bars are considered, filtering out very short-term patterns.
Lookback Range Max: Default: 60
What it is: The maximum range of bars within which a divergence can be detected.
What it does: Sets an upper bound on the range of bars considered for divergence detection. A larger maximum range might capture more significant divergences but could also include less relevant long-term patterns.
Example: Setting the maximum range to 60 bars allows the script to detect divergences over a longer timeframe, capturing more extended divergence patterns that could indicate major trend reversals.
RSI Divergence Explanation
RSI divergences occur when the RSI indicator and price action move in opposite directions, signaling potential trend reversals. This section of the settings allows traders to customize the appearance and detection of both regular and hidden bullish and bearish divergences.
RSI Divergence Input Settings:
R. Bullish Div Label: Default: True
What it is: An option to display labels for regular bullish divergences.
What it does: Enables or disables the visibility of labels that mark regular bullish divergences, where the price makes a lower low while the RSI makes a higher low, indicating a potential upward reversal.
Example: A trader might use this to spot buying opportunities in a downtrend when a bullish divergence suggests the trend may be reversing.
Bullish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of regular bullish divergence labels.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: Selecting a green label color and a distinct line width makes bullish divergences easily recognizable on your chart.
R. Bearish Div Label: Default: True
What it is: An option to display labels for regular bearish divergences.
What it does: Enables or disables the visibility of labels that mark regular bearish divergences, where the price makes a higher high while the RSI makes a lower high, indicating a potential downward reversal.
Example: A trader might use this to spot selling opportunities in an uptrend when a bearish divergence suggests the trend may be reversing.
Bearish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of regular bearish divergence labels.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: Choosing a red label color and a specific line width makes bearish divergences clearly stand out on your chart.
H. Bullish Div Label: Default: False
What it is: An option to display labels for hidden bullish divergences.
What it does: Enables or disables the visibility of labels that mark hidden bullish divergences, where the price makes a higher low while the RSI makes a lower low, indicating potential continuation of an uptrend.
Example: A trader might use this to confirm an existing uptrend when a hidden bullish divergence signals continued buying strength.
Hidden Bullish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of hidden bullish divergence labels.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: A softer green color with a thinner line width might be chosen to subtly indicate hidden bullish divergences, keeping the chart clean while providing useful information.
H. Bearish Div Label: Default: False
What it is: An option to display labels for hidden bearish divergences.
What it does: Enables or disables the visibility of labels that mark hidden bearish divergences, where the price makes a lower high while the RSI makes a higher high, indicating potential continuation of a downtrend.
Example: A trader might use this to confirm an existing downtrend when a hidden bearish divergence signals continued selling pressure.
Hidden Bearish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of hidden bearish divergence labels.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: A muted red color with a thinner line width might be selected to indicate hidden bearish divergences without overwhelming the chart.
Divergence Text Size and Color: Default: S (Small)
What it is: Settings to adjust the size and color of text labels for RSI divergences.
What it does: Allows you to customize the size and color of text labels that display the divergence information on the chart.
Example: Choosing a small text size with a bright white color can make divergence labels easily readable without taking up too much space on the chart.
STOCHASTIC DIVERGENCES
Display of Stochastic RSI Divergence Labels:
Display of Stochastic RSI Divergence Settings:
Stochastic RSI Divergence Explanation
Stochastic RSI divergences occur when the Stochastic RSI indicator and price action move in opposite directions, signaling potential trend reversals. These settings allow traders to customize the detection and visual representation of both regular and hidden bullish and bearish divergences in the Stochastic RSI.
Stochastic RSI Divergence Input Settings:
R. Bullish Div Label: Default: True
What it is: An option to display labels for regular bullish divergences in the Stochastic RSI.
What it does: Enables or disables the visibility of labels that mark regular bullish divergences, where the price makes a lower low while the Stochastic RSI makes a higher low, indicating a potential upward reversal.
Example: A trader might use this to spot buying opportunities in a downtrend when a bullish divergence in the Stochastic RSI suggests the trend may be reversing.
Bullish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of regular bullish divergence labels in the Stochastic RSI.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: Selecting a blue label color and a distinct line width makes bullish divergences in the Stochastic RSI easily recognizable on your chart.
R. Bearish Div Label: Default: True
What it is: An option to display labels for regular bearish divergences in the Stochastic RSI.
What it does: Enables or disables the visibility of labels that mark regular bearish divergences, where the price makes a higher high while the Stochastic RSI makes a lower high, indicating a potential downward reversal.
Example: A trader might use this to spot selling opportunities in an uptrend when a bearish divergence in the Stochastic RSI suggests the trend may be reversing.
Bearish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of regular bearish divergence labels in the Stochastic RSI.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: Choosing an orange label color and a specific line width makes bearish divergences in the Stochastic RSI clearly stand out on your chart.
H. Bullish Div Label: Default: False
What it is: An option to display labels for hidden bullish divergences in the Stochastic RSI.
What it does: Enables or disables the visibility of labels that mark hidden bullish divergences, where the price makes a higher low while the Stochastic RSI makes a lower low, indicating potential continuation of an uptrend.
Example: A trader might use this to confirm an existing uptrend when a hidden bullish divergence in the Stochastic RSI signals continued buying strength.
Hidden Bullish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of hidden bullish divergence labels in the Stochastic RSI.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: A softer blue color with a thinner line width might be chosen to subtly indicate hidden bullish divergences, keeping the chart clean while providing useful information.
H. Bearish Div Label: Default: False
What it is: An option to display labels for hidden bearish divergences in the Stochastic RSI.
What it does: Enables or disables the visibility of labels that mark hidden bearish divergences, where the price makes a lower high while the Stochastic RSI makes a higher high, indicating potential continuation of a downtrend.
Example: A trader might use this to confirm an existing downtrend when a hidden bearish divergence in the Stochastic RSI signals continued selling pressure.
Hidden Bearish Label Color, Line Width, and Line Color:
What it is: Settings to customize the appearance of hidden bearish divergence labels in the Stochastic RSI.
What it does: Allows you to choose the color of the labels, adjust the width of the divergence lines, and select the color for these lines.
Example: A muted orange color with a thinner line width might be selected to indicate hidden bearish divergences without overwhelming the chart.
Divergence Text Size and Color: Default: S (Small)
What it is: Settings to adjust the size and color of text labels for Stochastic RSI divergences.
What it does: Allows you to customize the size and color of text labels that display the divergence information on the chart.
Example: Choosing a small text size with a bright white color can make divergence labels easily readable without taking up too much space on the chart.
Alert System:
Custom Alerts for Divergences and Reversals:
What it is: The script includes customizable alert conditions to notify you of detected divergences or potential reversals based on WaveTrend, RSI, and Stochastic RSI.
What it does: Helps you stay informed of key market movements without constantly monitoring the charts, enabling timely decisions.
Example: Setting an alert for regular bearish divergence on the WaveTrend could notify you of a potential sell opportunity as soon as it is detected.
How to Use Alerts:
Set up custom alerts in TradingView based on these conditions to be notified of potential trading opportunities. Alerts are triggered when the indicator detects conditions that match the selected criteria, such as divergences or potential reversals.
By following the detailed guidelines and examples above, you can effectively use and customize this powerful indicator to suit your trading strategy.
For further understanding and customization, refer to the input settings within the script and adjust them to match your trading style and preferences.
How Components Work Together
Synergy and Cross-Validation: The indicator combines multiple layers of analysis to validate trading signals. For example, a WaveTrend buy signal that coincides with a bullish divergence in RSI and positive fast money flow is likely to be more reliable than any single indicator’s signal. This cross-validation reduces the likelihood of false signals and enhances decision-making.
Comprehensive Market Analysis: Each component plays a role in analyzing different aspects of the market. WaveTrend focuses on trend strength, Money Flow indicators assess market sentiment, while RSI and Stochastic RSI offer detailed views of price momentum and potential reversals.
Ideal For
Traders who require a reliable, multifaceted tool for detecting market trends and reversals.
Investors seeking a deeper understanding of market dynamics across different timeframes and conditions, whether in forex, equities, or cryptocurrency markets.
This script is designed to provide a comprehensive tool for technical analysis, combining multiple indicators and divergence detection into one versatile and customizable script. It is especially useful for traders who want to monitor various indicators simultaneously and look for convergence or divergence signals across different technical tools.
Acknowledgements
Special thanks to these amazing creators for inspiration and their creations:
I want to thank these amazing creators for creating there amazing indicators , that inspired me and also gave me a head start by making this indicator! Without their amazing indicators it wouldn't be possible!
vumanchu: VuManChu Cipher B Divergences.
MisterMoTa: RSI + Divergences + Alerts .
DevLucem: Plain Stochastic Divergence.
Note
This indicator is designed to be a powerful tool in your trading arsenal. However , it is essential to backtest and adjust the settings according to your trading strategy before applying it to live trading . If you have any questions or need further assistance, feel free to reach out.

GL Gann Swing IndicatorIntroduction
The GL Gann Swing Indicator is a versatile tool designed to help traders identify market trends, support and resistance areas, and potential reversals. This indicator applies the principles of Gann Swing Charts, a technique developed by W.D. Gann, which focuses on market swings to determine the overall direction and turning points of price action. Gann Swing Charts are a time-tested method of technical analysis that simplifies price action by focusing on significant highs and lows, thereby eliminating market noise and providing a clearer view of the trend.
By analyzing price action and determining swing directions and turning points, the indicator filters out market noise using four distinct bar types:
Up Bar: Higher High, Higher Low
Down Bar: Lower High, Lower Low
Inside Bar: Lower High, Higher Low
Outside Bar: Higher High, Lower Low
This approach helps traders to:
Identify the primary trend direction.
Determine key support and resistance levels.
Recognize potential reversal points.
Filter out minor price fluctuations that do not affect the overall trend.
Features
Bar Types: Display bar types by checking the Show Bar Type box in the indicator's settings. Up bars appear as green upward-pointing triangles, down bars as red downward-pointing triangles, inside bars as grey circles, and outside bars as blue diamonds. These visual aids help traders quickly identify the type of bar and its significance.
Break Lines: These lines highlight when the price rises above a previous swing high or falls below a prior swing low. Green lines indicate breaks of swing highs, while red lines indicate breaks of swing lows. Break lines are enabled by default but can be turned off in the indicator's settings. Break lines provide visual confirmation of trend continuation or reversal.
Bar Count: Bar counts help determine if a swing is overextended and if a reversal is likely. This feature is off by default but can be enabled in the indicator's settings. Users can set a minimum bar count to focus on significant swings. Analyzing the number of bars in a swing can help traders gauge the strength and potential exhaustion of a trend.
Swing MA (Moving Averages): This feature plots the average of a user-defined number of previous swing highs and lows. Options are available to add two moving averages, allowing for both fast and slow averages. Swing MAs can be enabled in the indicator's settings. These moving averages smooth out the price data, making it easier to identify the underlying trend direction.
Why This Indicator is Useful
The GL Gann Swing Indicator is particularly useful for several reasons:
Trend Identification: By focusing on significant price swings, the indicator helps traders identify the primary trend direction, making it easier to align trades with the overall market movement.
Noise Reduction: The indicator filters out minor price fluctuations, allowing traders to focus on meaningful market movements and avoid being misled by short-term volatility.
Support and Resistance Levels: By highlighting key swing highs and lows, the indicator helps traders identify crucial support and resistance levels, which are essential for making informed trading decisions.
Potential Reversals: The indicator's ability to identify overextended swings and potential reversal points can help traders anticipate market turning points and adjust their strategies accordingly.
Customizability: With options to display bar types, break lines, bar counts, and swing moving averages, traders can customize the indicator to suit their specific trading style and preferences.
By incorporating Gann Swing principles, the GL Gann Swing Indicator offers traders a powerful tool to enhance their technical analysis, improve their trading decisions, and ultimately achieve better trading outcomes.

D9 IndicatorD9 Indicator
Category
Technical Indicators
Overview
The D9 Indicator is designed to identify potential trend reversals by counting the number of consecutive closes that are higher or lower than the close four bars earlier. This indicator highlights key moments in the price action where a trend might be exhausting and potentially reversing, providing valuable insights for traders.
Features
Up Signal: Plots a downward triangle or a cross above the bar when the count of consecutive closes higher than the close four bars earlier reaches 7, 8, or 9.
Down Signal: Plots an upward triangle or a checkmark below the bar when the count of consecutive closes lower than the close four bars earlier reaches 7, 8, or 9.
Visual Signals
Red Downward Triangle (7): Indicates the seventh consecutive bar with a higher close.
Red Downward Triangle (8): Indicates the eighth consecutive bar with a higher close.
Red Cross (❌): Indicates the ninth consecutive bar with a higher close, suggesting a potential bearish reversal.
Green Upward Triangle (7): Indicates the seventh consecutive bar with a lower close.
Green Upward Triangle (8): Indicates the eighth consecutive bar with a lower close.
Green Checkmark (✅): Indicates the ninth consecutive bar with a lower close, suggesting a potential bullish reversal.
Usage
The D9 Indicator is useful for traders looking for visual cues to identify potential trend exhaustion and reversals. It can be applied to any market and timeframe, providing flexibility in various trading strategies.
How to Read
When a red cross (❌) appears above a bar, it may signal an overextended uptrend and a potential bearish reversal.
When a green checkmark (✅) appears below a bar, it may signal an overextended downtrend and a potential bullish reversal.
Example
When the price has consecutively closed higher than four bars ago for nine bars, a red cross (❌) will appear above the ninth bar. This suggests that the uptrend might be exhausting, and traders could look for potential short opportunities. Conversely, when the price has consecutively closed lower than four bars ago for nine bars, a green checkmark (✅) will appear below the ninth bar, indicating a potential buying opportunity.

chrono_utilsLibrary "chrono_utils"
Collection of objects and common functions that are related to datetime windows session days and time
ranges. The main purpose of this library is to handle time-related functionality and make it easy to reason about a
future bar checking if it will be part of a predefined session and/or inside a datetime window. All existing session
functionality I found in the documentation e.g. "not na(time(timeframe, session, timezone))" are not suitable for
strategy scripts, since the execution of the orders is delayed by one bar, due to the script execution happening at
the bar close. Moreover, a history operator with a negative value that looks forward is not allowed in any pinescript
expression. So, a prediction for the next bar using the bars_back argument of "time()"" and "time_close()" was
necessary. Thus, I created this library to overcome this small but very important limitation. In the meantime, I
added useful functionality to handle session-based behavior. An interesting utility that emerged from this
development is the data anomaly detection where a comparison between the prediction and the actual value is happening.
If those two values are different then a data inconsistency happened between the prediction bar and the actual bar
(probably due to a holiday, half session day, a timezone change etc..)
exTimezone(timezone)
exTimezone - Convert extended timezone to timezone string
Parameters:
timezone (simple string) : - The timezone or a special string
Returns: string representing the timezone
nameOfDay(day)
nameOfDay - Convert the day id into a short nameOfDay
Parameters:
day (int) : - The day id to convert
Returns: - The short name of the day
today()
today - Get the day id of this day
Returns: - The day id
nthDayAfter(day, n)
nthDayAfter - Get the day id of n days after the given day
Parameters:
day (int) : - The day id of the reference day
n (int) : - The number of days to go forward
Returns: - The day id of the day that is n days after the reference day
nextDayAfter(day)
nextDayAfter - Get the day id of next day after the given day
Parameters:
day (int) : - The day id of the reference day
Returns: - The day id of the next day after the reference day
nthDayBefore(day, n)
nthDayBefore - Get the day id of n days before the given day
Parameters:
day (int) : - The day id of the reference day
n (int) : - The number of days to go forward
Returns: - The day id of the day that is n days before the reference day
prevDayBefore(day)
prevDayBefore - Get the day id of previous day before the given day
Parameters:
day (int) : - The day id of the reference day
Returns: - The day id of the previous day before the reference day
tomorrow()
tomorrow - Get the day id of the next day
Returns: - The next day day id
normalize(num, min, max)
normalizeHour - Check if number is inthe range of
Parameters:
num (int)
min (int)
max (int)
Returns: - The normalized number
normalizeHour(hourInDay)
normalizeHour - Check if hour is valid and return a noralized hour range from
Parameters:
hourInDay (int)
Returns: - The normalized hour
normalizeMinute(minuteInHour)
normalizeMinute - Check if minute is valid and return a noralized minute from
Parameters:
minuteInHour (int)
Returns: - The normalized minute
monthInMilliseconds(mon)
monthInMilliseconds - Calculate the miliseconds in one bar of the timeframe
Parameters:
mon (int) : - The month of reference to get the miliseconds
Returns: - The number of milliseconds of the month
barInMilliseconds()
barInMilliseconds - Calculate the miliseconds in one bar of the timeframe
Returns: - The number of milliseconds in one bar
method to_string(this)
to_string - Formats the time window into a human-readable string
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object with the from and to datetimes
Returns: - The string of the time window
method to_string(this)
to_string - Formats the session days into a human-readable string with short day names
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
Returns: - The string of the session day short names
method to_string(this)
to_string - Formats the session time into a human-readable string
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
Returns: - The string of the session time
method to_string(this)
to_string - Formats the session time into a human-readable string
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object with the start and end time of the daily session
Returns: - The string of the session time
method to_string(this)
to_string - Formats the session into a human-readable string
Namespace types: Session
Parameters:
this (Session) : - The session object with the day and the time range selection
Returns: - The string of the session
method init(this, fromDateTime, toDateTime)
init - Initialize the time window object from boolean values of each session day
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object that will hold the from and to datetimes
fromDateTime (int) : - The starting datetime of the time window
toDateTime (int) : - The ending datetime of the time window
Returns: - The time window object
method init(this, refTimezone, chTimezone, fromDateTime, toDateTime)
init - Initialize the time window object from boolean values of each session day
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object that will hold the from and to datetimes
refTimezone (simple string) : - The timezone of reference of the 'from' and 'to' dates
chTimezone (simple string) : - The target timezone to convert the 'from' and 'to' dates
fromDateTime (int) : - The starting datetime of the time window
toDateTime (int) : - The ending datetime of the time window
Returns: - The time window object
method init(this, sun, mon, tue, wed, thu, fri, sat)
init - Initialize the session days object from boolean values of each session day
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object that will hold the day selection
sun (bool) : - Is Sunday a trading day?
mon (bool) : - Is Monday a trading day?
tue (bool) : - Is Tuesday a trading day?
wed (bool) : - Is Wednesday a trading day?
thu (bool) : - Is Thursday a trading day?
fri (bool) : - Is Friday a trading day?
sat (bool) : - Is Saturday a trading day?
Returns: - The session days object
method init(this, unixTime)
init - Initialize the object from the hour and minute of the session time in exchange timezone (syminfo.timezone)
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
unixTime (int) : - The unix time
Returns: - The session time object
method init(this, hourInDay, minuteInHour)
init - Initialize the object from the hour and minute of the session time in exchange timezone (syminfo.timezone)
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
hourInDay (int) : - The hour of the time
minuteInHour (int) : - The minute of the time
Returns: - The session time object
method init(this, hourInDay, minuteInHour, refTimezone)
init - Initialize the object from the hour and minute of the session time
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
hourInDay (int) : - The hour of the time
minuteInHour (int) : - The minute of the time
refTimezone (string) : - The timezone of reference of the 'hour' and 'minute'
Returns: - The session time object
method init(this, startTime, endTime)
init - Initialize the object from the start and end session time in exchange timezone (syminfo.timezone)
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object that will hold the start and end time of the daily session
startTime (SessionTime) : - The time the session begins
endTime (SessionTime) : - The time the session ends
Returns: - The session time range object
method init(this, startTimeHour, startTimeMinute, endTimeHour, endTimeMinute, refTimezone)
init - Initialize the object from the start and end session time
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object that will hold the start and end time of the daily session
startTimeHour (int) : - The time hour the session begins
startTimeMinute (int) : - The time minute the session begins
endTimeHour (int) : - The time hour the session ends
endTimeMinute (int) : - The time minute the session ends
refTimezone (string)
Returns: - The session time range object
method init(this, days, timeRanges)
init - Initialize the session object from session days and time range
Namespace types: Session
Parameters:
this (Session) : - The session object that will hold the day and the time range selection
days (SessionDays) : - The session days object that defines the days the session is happening
timeRanges (array) : - The array of all the session time ranges during a session day
Returns: - The session object
method init(this, days, timeRanges, names, colors)
init - Initialize the session object from session days and time range
Namespace types: SessionView
Parameters:
this (SessionView) : - The session view object that will hold the session, the names and the color selections
days (SessionDays) : - The session days object that defines the days the session is happening
timeRanges (array) : - The array of all the session time ranges during a session day
names (array) : - The array of the names of the sessions
colors (array) : - The array of the colors of the sessions
Returns: - The session object
method get_size_in_secs(this)
get_size_in_secs - Count the seconds from start to end in the given timeframe
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object with the from and to datetimes
Returns: - The number of seconds inside the time widow for the given timeframe
method get_size_in_secs(this)
get_size_in_secs - Calculate the seconds inside the session
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object with the start and end time of the daily session
Returns: - The number of seconds inside the session
method get_size_in_bars(this)
get_size_in_bars - Count the bars from start to end in the given timeframe
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object with the from and to datetimes
Returns: - The number of bars inside the time widow for the given timeframe
method get_size_in_bars(this)
get_size_in_bars - Calculate the bars inside the session
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object with the start and end time of the daily session
Returns: - The number of bars inside the session for the given timeframe
method is_bar_included(this, offset_forward)
is_bar_included - Check if the given bar is between the start and end dates of the window
Namespace types: DateTimeWindow
Parameters:
this (DateTimeWindow) : - The time window object with the from and to datetimes
offset_forward (simple int) : - The number of bars forward. Default is 1
Returns: - Whether the current bar is inside the datetime window
method is_bar_included(this, offset_forward)
is_bar_included - Check if the given bar is inside the session as defined by the input params (what "not na(time(timeframe.period, this.to_sess_string()) )" should return if you could write it
Namespace types: Session
Parameters:
this (Session) : - The session with the day and the time range selection
offset_forward (simple int) : - The bar forward to check if it is between the from and to datetimes. Default is 1
Returns: - Whether the current time is inside the session
method to_sess_string(this)
to_sess_string - Formats the session days into a session string with day ids
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object
Returns: - The string of the session day ids
method to_sess_string(this)
to_sess_string - Formats the session time into a session string
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
Returns: - The string of the session time
method to_sess_string(this)
to_sess_string - Formats the session time into a session string
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object with the start and end time of the daily session
Returns: - The string of the session time
method to_sess_string(this)
to_sess_string - Formats the session into a session string
Namespace types: Session
Parameters:
this (Session) : - The session object with the day and the time range selection
Returns: - The string of the session
method from_sess_string(this, sess)
from_sess_string - Initialize the session days object from the session string
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object that will hold the day selection
sess (string) : - The session string part that represents the days
Returns: - The session days object
method from_sess_string(this, sess)
from_sess_string - Initialize the session time object from the session string in exchange timezone (syminfo.timezone)
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object that will hold the hour and minute of the time
sess (string) : - The session string part that represents the time HHmm
Returns: - The session time object
method from_sess_string(this, sess, refTimezone)
from_sess_string - Initialize the session time object from the session string
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object that will hold the hour and minute of the time
sess (string) : - The session string part that represents the time HHmm
refTimezone (simple string) : - The timezone of reference of the 'hour' and 'minute'
Returns: - The session time object
method from_sess_string(this, sess)
from_sess_string - Initialize the session time range object from the session string in exchange timezone (syminfo.timezone)
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object that will hold the start and end time of the daily session
sess (string) : - The session string part that represents the time range HHmm-HHmm
Returns: - The session time range object
method from_sess_string(this, sess, refTimezone)
from_sess_string - Initialize the session time range object from the session string
Namespace types: SessionTimeRange
Parameters:
this (SessionTimeRange) : - The session time range object that will hold the start and end time of the daily session
sess (string) : - The session string part that represents the time range HHmm-HHmm
refTimezone (simple string) : - The timezone of reference of the time ranges
Returns: - The session time range object
method from_sess_string(this, sess)
from_sess_string - Initialize the session object from the session string in exchange timezone (syminfo.timezone)
Namespace types: Session
Parameters:
this (Session) : - The session object that will hold the day and the time range selection
sess (string) : - The session string that represents the session HHmm-HHmm,HHmm-HHmm:ddddddd
Returns: - The session time range object
method from_sess_string(this, sess, refTimezone)
from_sess_string - Initialize the session object from the session string
Namespace types: Session
Parameters:
this (Session) : - The session object that will hold the day and the time range selection
sess (string) : - The session string that represents the session HHmm-HHmm,HHmm-HHmm:ddddddd
refTimezone (simple string) : - The timezone of reference of the time ranges
Returns: - The session time range object
method nth_day_after(this, day, n)
nth_day_after - The nth day after the given day that is a session day (true) in the object
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
day (int) : - The day id of the reference day
n (int) : - The number of days after
Returns: - The day id of the nth session day of the week after the given day
method nth_day_before(this, day, n)
nth_day_before - The nth day before the given day that is a session day (true) in the object
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
day (int) : - The day id of the reference day
n (int) : - The number of days after
Returns: - The day id of the nth session day of the week before the given day
method next_day(this)
next_day - The next day that is a session day (true) in the object
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
Returns: - The day id of the next session day of the week
method previous_day(this)
previous_day - The previous day that is session day (true) in the object
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
Returns: - The day id of the previous session day of the week
method get_sec_in_day(this)
get_sec_in_day - Count the seconds since the start of the day this session time represents
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
Returns: - The number of seconds passed from the start of the day until that session time
method get_ms_in_day(this)
get_ms_in_day - Count the milliseconds since the start of the day this session time represents
Namespace types: SessionTime
Parameters:
this (SessionTime) : - The session time object with the hour and minute of the time of the day
Returns: - The number of milliseconds passed from the start of the day until that session time
method is_day_included(this, day)
is_day_included - Check if the given day is inside the session days
Namespace types: SessionDays
Parameters:
this (SessionDays) : - The session days object with the day selection
day (int) : - The day to check if it is a trading day
Returns: - Whether the current day is included in the session days
DateTimeWindow
DateTimeWindow - Object that represents a datetime window with a beginning and an end
Fields:
fromDateTime (series int) : - The beginning of the datetime window
toDateTime (series int) : - The end of the datetime window
SessionDays
SessionDays - Object that represent the trading days of the week
Fields:
days (map) : - The map that contains all days of the week and their session flag
SessionTime
SessionTime - Object that represents the time (hour and minutes)
Fields:
hourInDay (series int) : - The hour of the day that ranges from 0 to 24
minuteInHour (series int) : - The minute of the hour that ranges from 0 to 59
minuteInDay (series int) : - The minute of the day that ranges from 0 to 1440. They will be calculated based on hourInDay and minuteInHour when method is called
SessionTimeRange
SessionTimeRange - Object that represents a range that extends from the start to the end time
Fields:
startTime (SessionTime) : - The beginning of the time range
endTime (SessionTime) : - The end of the time range
isOvernight (series bool) : - Whether or not this is an overnight time range
Session
Session - Object that represents a session
Fields:
days (SessionDays) : - The map of the trading days
timeRanges (array) : - The array with all time ranges of the session during the trading days
SessionView
SessionView - Object that visualize a session
Fields:
sess (Session) : - The Session object to be visualized
names (array) : - The names of the session time ranges
colors (array) : - The colors of the session time ranges

Bilson Gann CountGann counting is a method for identifying swing points,trends, and overall market structure. It simplifies price action by drawing short trend lines that summarize moves.
There's essentially 4 types of bar/candle.
Up bar - Higher high and higher low than previous bar
Down bar - Lower high and lower low than previous bar
Inside bar - Lower high and higher low than previous bar
Outside bar - Higher high and lower low than previous bar
We use these determinations to decide how the trendline moves through the candles.
Up bars we join to the high, down bars we join to the low, inside bars are ignored.
There are other indicators that already exist which do this, the difference here is how we handle outside bars.
Other gann counting methods skip outside bars, this method determines how to handle the outside bar after the outside bar is broken.
examples
UP -> OUTSIDE -> UP = Outside bar treated as swing low
UP -> OUTSIDE -> DOWN = Outside bar treated as swing high
DOWN -> OUTSIDE -> UP = Outside bar treated as swing low
DOWN -> OUTSIDE -> DOWN = Outside bar treated as swing high
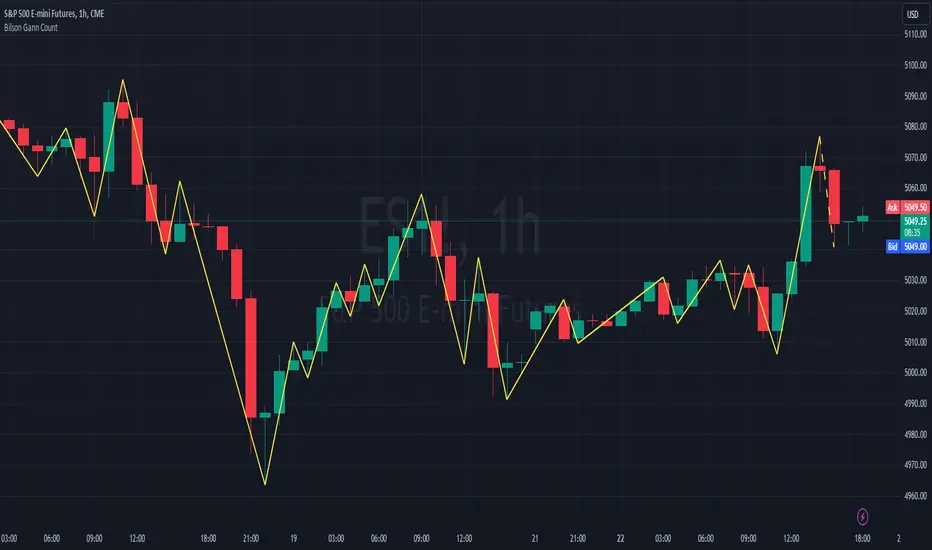
[TTI] High Volume Close (HVC) Setup📜 ––––HISTORY & CREDITS––––
The High Volume Close (HVC) Setup is a specialised indicator designed for the TradingView platform used to identify specific bar. This tool was developed with the objective of identifying a technical pattern that trades have claimed is significant trading opportunities through a unique blend of volume analysis and price action strategies. It is based on the premise that high-volume bars, when combined with specific price action criteria, can signal key market movements.
The HVC is applicable both for swing and longer term trading and as a technical tool it can be used by traders of any asset type (stocks, ETF, crypto, forex etc).
🦄 –––UNIQUENESS–––
The uniqueness of the HVC Setup lies in its flexibility to determine an important price level based on historically important bar. The idea is to identify significant bars (e.g. those who have created the HIGHEST VOLUME: Ever, Yearly, Quarterly and meet additional criteria from the settings) and plot on the chart the close on that day as a significant level as well as theoretical stop loss and target levels. This approach allows traders to discern high volume bars that are contextually significant — a method not commonly found in standard trading tools.
🎯 ––––WHAT IT DOES––––
The HVC Setup indicator performs a series of calculations to identify high volume close bars/bar (HVC bars) based on the user requirements.
These bars are determined based on the highest volume recorded within a user-inputs:
👉 Period (Ever, Yearly, Quarterly) and must meet additional criteria such as:
👉 a minimum percentage Price Change (change is calculated based on a close/close) and
👉 specific Closing Range requirements for the HVC da.
The theory is that this is a significant bar that is important to know where it is on the chart.
The script includes a comparative analysis of the HVC bar's price against historical price highs (all-time, yearly, quarterly), which provides further context and significance to the identified bars. All of these USER input requirement are then taken into account as a condition to identity the High Volume Close Bar (HVC).
The visual representation includes color-coded bar (default is yellow) and lines to delineate these key trading signals. It then draws a blue line for the place where the close ofthe bar is, a red line that would signify a stop loss and 2 target profit levels equal to 2R and 3R of the risked level (close-stop loss). Additional lines can be turned on/off with their coresponding checkboxes in the settings.
If the user chooses "Ever" for Period - the script will look at the first available bar ever in Tradingview - this is generally the IPO bar;
If the users chooses "Yearly" - the script would look at the highest available bar for a completed year;
If the users chooses "Quarterly" - it would do the same for the quarter. (works on daily timeframe only);
While we have not backtested the performance of the script, this methodology has been widely publicised.
🛠️ ––––HOW TO USE IT––––
To utilize the HVC Setup effectively:
👉Customize Input Settings: Choose the HVC period, percentage change threshold, closing range, stop loss distance, and target multiples according to your trading strategy. Use the tick boxes to enable and disable if a given condition is used within the calculation.
👉Identify HVC Bars: The script highlights HVC bars, indicating potential opportunities based on volume and price action analysis.
👉Interpret Targets and Stop Losses: Use the color-coded lines (green for targets, red for stop losses) to guide your trade entries and exits.
👉Contextual Analysis: Always consider the HVC bar signals in conjunction with overall market trends and additional technical indicators for comprehensive trading decisions.
This script is designed to assist traders in identifying high-potential trading setups by using a combination of volume and price analysis, enhancing traditional methods with a unique, algorithmically driven approach.

Volume Delta Trailing Stop [LuxAlgo]The ' Volume Delta Trailing Stop ' indicator uses Lower Time Frame (LTF) volume delta data which can provide potential entries together with a Volume-Delta based Trailing Stop-line .
🔶 USAGE
Our 'Volume Delta Trailing Stop' script can show potential entries/Stop Loss lines
A trigger line needs to be broken before a position is taken, after which a Volume Delta-controlled Trailing Stop-line is created:
🔶 DETAILS
🔹 Volume rises when bought or sold
🔹 When the opening price appears on the chart, a buy/sell order has been executed.
If that order is less than the available supply of that particular price, volume will rise, without moving the price.
🔹 When the opening price is the same as the closing price, the volume of that bar can be seen as "neutral volume" (nV); nor "up", nor "down" volume.
Example
A buy order doesn't fill the first available supply in the order book. This price will be the opening price with a certain volume.
When at closing time, price still hasn't moved (the first available supply in the order book isn't filled, or no movement downwards),
the closing price will be equal to the opening price, but with volume. This can be seen as "neutral volume (nV)".
🔹 Delta Volume (ΔV): this is "up volume" minus "down volume"
🔹 Standard volume is colored red when closing price is lower than opening price ( = "down volume").
🔹 Standard volume is colored green when closing price is higher OR equal (nV) than opening price ( = "up volume").
🔹 Neutral Volume
The "Neutral-Volume" is considered "Up-Volume" - setting will dictate whether nV is considered as green 'buy' volume or not.
🔶 EXAMPLE
29 July 10:00 -> 10:05, chart timeframe 5 minutes, open 29311.28, close 29313.89
close > open, so the volume (39.55) is colored green ("up volume").
(The Volume script used in the following examples is the open-source publication Volume Columns w. Alerts (V) from LucF )
Let's zoom to the 1-minute TF:
The same period is now divided into more bars, volume direction (color) is dependable on the difference between open and close.
Counting up and down volume gives a more detailed result, it remains in an upward direction though):
(ΔV = +15.51)
Let's further zoom in to the 1-second TF:
The same period is now divided into even more bars (more possibility for changing direction on each bar)
Here we see several bars that haven't moved in price, but they have volume ("neutral" volume).
(neutral volume is coloured light green here, while up volume is coloured darker green)
When we count all green and red volume bars, the result is quite different:
(ΔV = -0.35)
In total more volume is found when price went downwards, yet price went up in these 5 minutes.
-> This is the heart of our publication, when this divergence occurs, you can see a barcolor changement:
• orange: when price went up, but LTF Volume was mainly in a downward direction.
• blue: when price went down, but LTF Volume was mainly in an upwards direction.
When we split the green "up volume" into "up" and "neutral", the difference is even higher
(here "neutral volume" is colored grey):
(ΔV = -12.76; "up" - "down")
🔶 CONCEPTS
bullishBear = current bar is red but LTF volume is in upward direction -> blue bar
bearishBull = current bar is green but LTF volume is in downward direction -> orange bar
🔹 Potential positioning - forming of Trigger-line
When not in position, the script will wait for a divergence between price and volume direction. When found, a Trigger-line will appear:
• at high when a blue bar appears ( bullishBear ).
• at low when an orange bar appears ( bearishBull ).
Next step is when the Trigger-line is broken by close or high/low (settings: Trigger )
Here, the closing price went under the grey Trigger-line -> bearish position:
🔹 Trailing Stop-line
When the Trigger-line is broken, the Trailing Stop-line (TS-line) will start:
• low when bullish position
• high when bearish position
You can choose (settings -> Trigger -> Close or H/L ) whether close price or high/low should break the Trigger-line
When alerts are enabled ("Any alert() function call"), you'll get the following message:
• ' signal up ' when bullish position
• ' signal down' when bearish position
After that, the TS-line will be adjusted when:
• a blue bullishBear bar appears when in bullish position -> lowest of {low , previous blue bar's high or orange bar's low}
• an orange bearishBull bar appears when in bearish position -> highest of {high, previous blue bar's high or orange bar's low}
When alerts are enabled ("Any alert() function call"), and the TS-line is broken, you'll get the following message:
• ' TS-line broken down ' when out bullish position
• ' TS-line broken up ' when out bearish position
🔹 Reference Point
Default the direction of price will be evaluated by comparing closing price with opening price.
When open and close are the same, you'll get "neutral volume".
You can use "previous close" instead (as in built-in volume indicator) to include gaps.
If close equals open , but close is lower than previous close , it will be regarded as " down volume ",
similar, when close is higher than previous close , it will be regarded as " up volume "
Note, the setting applies for the current timeframe AND Lower timeframe:
Based on: " open " (close - open)
Based on: " previous close " (close - previous close)
🔹 Adjustment
When the TS-line changes, this can be adjusted with a percentage of price , or a multiple of " True Range "
Default (Δ line -> Adjustment - 0)
Δ line -> Adjustment 0.03% (of price)
Δ line -> Mult of TR (10)
🔶 SETTINGS
🔹 LTF: choose your Lower TimeFrame: 1S (seconds), 5S, 10S, 15S, 30S, 1 minute)
🔹 Trigger: Choose the trigger for breaking the Trigger-line ; close or H/L (high when bullish position, low when bearish position)
🔹 Δ line ( Trailing Stop-line ): add/subtract an adjustment when the TS-line changes ( default: Adjustment ):
• Adjustment ( default: 0 ): add/subtract an extra % of price
• Mult of TR : add/subtract a multiple of True Range
🔹 Based on: compare closing price against:
• open
• previous close
🔹 "Neutral-Volume" is considered "Up-Volume" : this setting will dictate whether nV is considered as green 'buy' volume or not.
🔶 CONSIDERATIONS
🔹 The lowest LTF (1S) will give you more detail and will get data close to tick data.
However, a maximum of 100,000 intrabars can be used in calculations .
This means on the daily chart you won't see anything since 1 day ~ 86400 seconds. (just over 1 bar)
-> choose a lower chart timeframe, or choose a higher LTF (5S, 10S, ... 1 minute)
🔹 Always choose a LTF lower than the current chart timeframe.
🔹 Pine Script™ code using this request.security_lower_tf() may calculate differently on historical and real-time bars, leading to repainting .
Volume Profile (Maps) [LuxAlgo]The Pine Script® developers have unleashed "maps"!
Volume Profile (Maps) displays volume, associated with price, above and below the latest price, by using maps
The largest and second-largest volume is highlighted.
🔶 USAGE
The proposed script can highlight more frequent closing prices/prices with the highest volume, potentially highlighting more liquid areas. The prices with the highest associated volume (in red and orange in the indicator) can eventually be used as support/resistance levels.
Voids within the volume profile can highlight large price displacements (volatile variations).
🔶 CONCEPTS
🔹 Maps
A map object is a collection that consists of key - value pairs
Each key is unique and can only appear once. When adding a new value with a key that the map already contains, that value replaces the old value associated with the key .
You can change the value of a particular key though, for example adding volume (value) at the same price (key), the latter technique is used in this script.
Volume is added to the map, associated with a particular price (default close, can be set at high, low, open,...)
When the map already contains the same price (key), the value (volume) is added to the existing volume at the associated price.
A map can contain maximum 50K values, which is more than enough to hold 20K bars (Basic 5K - Premium plan 20K), so the whole history can be put into a map.
🔹 Visible line/box limit
We can only display maximum 500 line.new() though.
The code locates the current (last) close, and displays volume values around this price, using lines, for example 250 lines above and 250 lines below current price.
If one side contains fewer values, the other side can show more lines, taking the maximum out of the 500 visible line limitation.
Example (max. 500 lines visible)
• 100 values below close
• 2000 values above close
-> 100 values will be displayed below close
-> 400 remaining -> 400 values will be displayed above close
Pushing the limits even further, when ' Amount of bars ' is set higher than 500, boxes - box.new() - will be used as well.
These have a limit of 500 as well, bringing the total limit to 1000.
Note that there are visual differences when boxes overlap against lines.
If this is confusing, please keep ' Amount of bars ' at max. 500 (then only lines will be used).
🔹 Rounding function
This publication contains 2 round functions, which can be used to widen the Volume Profile
Round
• "Round" set at zero -> nothing changes to the source number
• "Round" set below zero -> x digit(s) after the decimal point, starting from the right side, and rounded.
• "Round" set above zero -> x digit(s) before the decimal point, starting from the right side, and rounded.
Example: 123456.789
0->123456.789
1->123456.79
2->123456.8
3->123457
-1->123460
-2->123500
Step
Another option is custom steps.
After setting "Round" to "Step", choose the desired steps in price,
Examples
• 2 -> 1234.00, 1236.00, 1238.00, 1240.00
• 5 -> 1230.00, 1235.00, 1240.00, 1245.00
• 100 -> 1200.00, 1300.00, 1400.00, 1500.00
• 0.05 -> 1234.00, 1234.05, 1234.10, 1234.15
•••
🔶 FEATURES
🔹 Adjust position & width
🔹 Table
The table shows the details:
• Size originalMap : amount of elements in original map
• # higher: amount of elements, higher than last "close" (source)
• index "close" : index of last "close" (source), or # element, lower than source
• Size newMap : amount of elements in new map (used for display lines)
• # higher : amount of elements in newMap, higher than last "close" (source)
• # lower : amount of elements in newMap, lower than last "close" (source)
🔹 Volume * currency
Let's take as example BTCUSD, relative to USD, 10 volume at a price of 100 BTCUSD will be very different than 10 volume at a price of 30000 (1K vs. 300K)
If you want volume to be associated with USD, enable Volume * currency . Volume will then be multiplied by the price:
• 10 volume, 1 BTC = 100 -> 1000
• 10 volume, 1 BTC = 30K -> 300K
Disabled
Enabled
🔶 DETAILS
🔹 Put
When the map doesn't contain a price, it will be added, using map.put(id, key, value)
In our code:
map.put(originalMap, price, volume)
or
originalMap.put(price, volume)
A key (price) is now associated with a value (volume) -> key : value
Since all keys are unique, we don't have to know its position to extract the value, we just need to know the key -> map.get(id, key)
We use map.get() when a certain key already exists in the map, and we want to add volume with that value.
if originalMap.contains(price)
originalMap.put(price, originalMap.get(price) + volume)
-> At the last bar, all prices (source) are now associated with volume.
🔹 Copy & sort
Next, every key of the map is copied and sorted (array of keys), after which the index (idx) is retrieved of last (current) price.
copyK = originalMap.keys().copy()
copyK.sort()
idx = copyK.binary_search_leftmost(src)
Then left and right side of idx is investigated to show a maximum amount of lines at both sides of last price.
🔹 New map & display
The keys (from sorted array of copied keys) that will be displayed are put in a new map, with the associated volume values from the original map.
newMap = map.new()
🔹 Re-cap
• put in original amp (price key, volume value)
• copy & sort
• find index of last price
• fetch relevant keys left/right from that index
• put keys in new map and fetch volume associated with these keys (from original map)
Simple example (only show 5 lines)
bar 0, price = 2, volume = 23
bar 1, price = 4, volume = 3
bar 2, price = 8, volume = 21
bar 3, price = 6, volume = 7
bar 4, price = 9, volume = 13
bar 5, price = 5, volume = 85
bar 6, price = 3, volume = 13
bar 7, price = 1, volume = 4
bar 8, price = 7, volume = 9
Original map:
Copied keys array:
Sorted:
-> 5 keys around last price (7) are fetched (5, 6, 7, 8, 9)
-> keys are placed into new map + volume values from original map
Lastly, these values are displayed.
🔶 SETTINGS
Source : Set source of choice; default close , can be set as high , low , open , ...
Volume & currency : Enable to multiply volume with price (see Features )
Amount of bars : Set amount of bars which you want to include in the Volume Profile
Max lines : maximum 1000 (if you want to use only lines, and no boxes -> max. 500, see Concepts )
🔹 Round -> ' Round/Step '
Round -> see Concepts
Step -> see Concepts
🔹 Display Volume Profile
Offset: shifts the Volume Profile (max. 500 bars to the right of last bar, see Features )
Max width Volume Profile: largest volume will be x bars wide, the rest is displayed as a ratio against largest volume (see Features )
Show table : Show details (see Features )
🔶 LIMITATIONS
• Lines won't go further than first bar (coded).
• The Volume Profile can be placed maximum 500 bar to the right of last price.
• Maximum 500 lines/boxes can be displayed
MW Volume ImpulseMW Volume Impulse
Settings
* Moving Average Period: The moving average period used to generate the moving average line for the bar chart. Default=14
* Dot Size: The size of the dot that indicates when the moving average of the CVD is breached. Default=10
* Dot Transparency: The transparency of the dot that indicates when the moving average of the CVD is breached. Default=50
* EMA: The exponential moving average that the price must break through, in addition to the CVD moving
* Accumulation Length: Period used to generate the Cumulative Volume Delta (CVD) for the bar chart. Default=14
Introduction
Velocity = Change in Position over time
Acceleration = Change in Velocity over time
For this indicator, Position is synonymous with the Cumulative Volume Delta (CVD) value. What the indicator attempts to do is to determine when the rate of acceleration of buying or selling volume is changing in either or buying or selling direction in a meaningful way.
Calculations
The CVD, upon which these changes is calculated using candle bodies and wicks. For a red candle, buying volume is calculated by multiplying the volume by the spread percentage of the average of the top and bottom wicks, while Selling Volume is calculated multiplying the volume by the spread percentage of the average of the top and bottom wicks - in addition to the spread percentage of the candle body.
For a green candle, buying volume is calculated by multiplying the volume by the spread percentage of the average of the top and bottom wicks - plus the spread percentage of the candle body - while Selling Volume is calculated using only the spread percentage average of the top and bottom wicks.
How to Interpret
The difference between the buying volume and selling volume is the source of what generates the red and green bars on the indicator. But, more specifically, this indicator uses an exponential moving average of these volumes (14 EMA by default) to determine that actual bar size. The change in this value indicates the velocity of volume and, ultimately, the red and green bars on the indicator.
- When the bar height is zero, that means that there is no velocity, which indicates either a balance between buyers and sellers, or very little volume.
- When the bar height remains largely unchanged from period to period - and not zero - it means that the velocity of volume is constant in one direction. That direction is indicated by the color of the bar. Buyers are dominating when the bars are green, and sellers are dominating when the bars are red.
- When the bar height increases, regardless of bar color, it means that volume is accelerating in a buying direction.
- When the bar height decreases, regardless of bar color, it means that volume is accelerating in a selling direction.
The white line represents the moving average of the bar values, while the red and white - and green and white - dots show when the moving average has been breached by the Cumulative Volume Delta value AND the price has broken the 7 EMA (which is user editable). As with most moving averages, a breach can indicate a move in a bearish or bullish direction, and the sensitivity can be adjusted for differing market conditions
Other Usage Notes and Limitations
For better use of the signal, consider the following,
1. Volume moving below the moving average can indicate that the volume may be ready to exit an overbought condition, especially if the bars were making lower highs prior to the signal - regardless of bar color.
3. Volume moving above the moving average can indicate that the volume may be ready to exit an oversold condition, especially if the bars were making higher lows prior to the signal - regardless of bar color.
Additionally, a green dot that occurs with a positive (green) Cumulative Volume Delta can indicate a buying condition, while a red dot that occurs with a negative (red) Cumulative Volume Delta can indicate a selling condition. What this means is that buying or selling momentum briefly went against the direction of buying or selling Cumulative Volume Delta , but was not strong enough to change the buying or selling direction. In cases like this, once the volume begins to accelerate again in the direction of the buying or selling volume - indicated by a red or green dot - then the price is more likely to favor the direction of the Cumulative Volume Delta and its corresponding acceleration.
Although a red or green signal can indicate a change in direction, this script cannot predict the magnitude or duration of the change. It is best used with accompanying indicators that can be used to confirm a direction change, such as a moving average, or a supply or demand range.

Developing Market Profile / TPO [Honestcowboy]The Developing Market Profile Indicator aims to broaden the horizon of Market Profile / TPO research and trading. While standard Market Profiles aim is to show where PRICE is in relation to TIME on a previous session (usually a day). Developing Market Profile will change bar by bar and display PRICE in relation to TIME for a user specified number of past bars.
What is a market profile?
"Market Profile is an intra-day charting technique (price vertical, time/activity horizontal) devised by J. Peter Steidlmayer. Steidlmayer was seeking a way to determine and to evaluate market value as it developed in the day time frame. The concept was to display price on a vertical axis against time on the horizontal, and the ensuing graphic generally is a bell shape--fatter at the middle prices, with activity trailing off and volume diminished at the extreme higher and lower prices."
For education on market profiles I recommend you search the net and study some profitable traders who use it.
Key Differences
Does not have a value area but distinguishes each column in relation to the biggest column in percentage terms.
Updates bar by bar
Does not take sessions into account
Shows historical values for each bar
While there is an entire education system build around Market Profiles they usually focus on a daily profile and in some cases how the value area develops during the day (there are indicators showing the developing value area).
The idea of trading based on a developing value area is what inspired me to build the Developing Market Profile.
🟦 CALCULATION
Think of this Developing Market Profile the same way as you would think of a moving average. On each bar it will lookback 200 bars (or as user specified) and calculate a Market Profile from those bars (range).
🔹Market Profile gets calculated using these steps:
Get the highest high and lowest low of the price range.
Separate that range into user specified amount of price zones (all spaced evenly)
Loop through the ranges bars and on each bar check in which price zones price was, then add +1 to the zones price was in (we do this using the OccurenceArray)
After it looped through all bars in the range it will draw columns for each price zone (using boxes) and make them as wide as the OccurenceArray dictates in number of bars
🔹Coloring each column:
The script will find the biggest column in the Profile and use that as a reference for all other columns. It will then decide for each column individually how big it is in % compared to the biggest column. It will use that percentage to decide which color to give it, top 20% will be red, top 40% purple, top 60% blue, top 80% green and all the rest yellow. The user is able to adjust these numbers for further customisation.
The historical display of the profiles uses plotchar() and will not only use the color of the column at that time but the % rating will also decide transparancy for further detail when analysing how the profiles developed over time. Each of those historical profiles is calculated using its own 200 past bars. This makes the script very heavy and that is why it includes optimisation settings, more info below.
🟦 USAGE
My general idea of the markets is that they are ever changing and that in studying that changing behaviour a good trader is able to distinguish new behaviour from old behaviour and adapt his approach before losing traders "weak hands" do.
A Market Profile can visually show a trader what kind of market environment we currently are in. In training this visual feedback helps traders remember past market environments and how the market behaved during these times.
Use the history shown using plotchars in colors to get an idea of how the Market Profile looked at each bar of the chart.
This history will help in studying how price moves at different stages of the Market Profile development.
I'm in no way an expert in trading Market Profiles so take this information with a grain of salt. Below an idea of how I would trade using this indicator:
🟦 SETTINGS
🔹MARKET PROFILING
Lookback: The amount of bars the Market Profile will look in the past to calculate where price has been the most in that range
Resolution: This is the amount of columns the Market Profile will have. These columns are calculated using the highest and lowest point price has been for the lookback period
Resolution is limited to a maximum of 32 because of pinescript plotting limits (64). Each plotchar() because of using variable colors takes up 2 of these slots
🔹VISUAL SETTINGS
Profile Distance From Chart: The amount of bars the market profile will be offset from the current bar
Border width (MP): The line thickness of the Market Profile column borders
Character: This is the character the history will use to show past profiles, default is a square.
Color theme: You can pick 5 colors from biggest column of the Profile to smallest column of the profile.
Numbers: these are for % to decide column color. So on default top 20% will be red, top 40% purple... Always use these in descending order
Show Market Profile: This setting will enable/disable the current Market Profile (columns on right side of current bar)
Show Profile History: This setting will enable/disable the Profile History which are the colored characters you see on each bar
🔹OPTIMISATION AND DEBUGGING
Calculate from here: The Market Profile will only start to calculate bar by bar from this point. Setting is needed to optimise loading time and quite frankly without it the script would probably exceed tradingview loading time limits.
Min Size: This setting is there to avoid visual bugs in the script. Scaling the chart there can be issues where the Market Profile extends all the way to 0. To avoid this use a minimum size bigger than the bugged bottom box
LNL Scalper ArrowsLNL Scalper Arrows
The indicator consist of various different types of candlestick patterns that are truly time tested by multiple veteran traders. These arrows are a combination of short-term scalping strategies taught by Linda Raschke & a trader that goes by name Quant Trade Edge. These strategies/patterns occur regularly within the markets. They offer high probability quick moves during the trending days. These four patterns are based on pure price action, no oscillators, no trend, no momentum indicators involved. Trend (ema) is there just as a simple trend gauge.
LNL Scalper Arrows were designed specifically for intra-day trading. Mostly useful for the futures but also stocks as well. These arrows can work anywhere between the fast-moving 512 or 1600 tick charts to a 1min, 2min and up to 5min or 10min charts.
Trend Gauge (Exponential Moving Average)
Nothing fancy just a classic EMA that can guide the direction of the short-term trend. I have added a custom coloring of the EMA that is based on a simple RSI filter. That should help to visualize the non-directional moments within the trend. Although the length is adjustable, for scalping it is better to focus on smaller periods such as 9, 13 or 20 or 34 but anything above 50 loses its purpose as a short-term trend gauge. Again, this is a scalping tool not a trend tool, you are not going to get rid of the fakeouts by increasing the period of the trend.
Tail Arrows (Eat the Tail Pattern)
Tail is a candlestick that is either a price rejection spike, or a flag continuation pattern on a lower time frame. A failed action. It is basically a candle with much bigger wick (shadow) of the candle than the actual body. Such candles are usually telling us about strong participation from the other side of the market. Eat the tail pattern occurs whenever the low of the Tail candle is immediately broken on a following candle "the tail is eaten alive". Such a breaks occurs in a most aggressive types of markets with a strong momentum. DO NOT try to trade this in a low volume or a ranging market. Tail Arrows are the most aggressive arrows & should be only used on the highest volume or a parabolic momentum markets.
Scalp Arrows (Scallop Pattern)
Known as Scallops or minor lows or highs, these patterns are the most common within the all scalper arrows. They occur regularly on 1min & 5min charts - basically everyday. Scallops provide the best possible risk to reward entry within the trend without the need of any indicators or oscillators. The Scallop Up 3 bar pattern consist of a high that is lower that the previous high but also low that is lower than the previous low. Scallop Up or a minor low triggers when the last high is broken, creating a three bar mountain or a peak within the 5 bar span.
Hoagie Arrows (Hoagie Pattern)
Hoagies occur way less often than any other scalping patterns. Hoagies represent two (or more) inside candles within the shadow of a first candle. Such a formation is creating a small compression or a range that sooner or later breaks out. The hoagie is triggered whenever the high or low of the shadow (first) candle is broken. The great thing about the hoagies is that they can work either way despite the trend direction. Although this indicator is coded for the 2 bar hoagies, there are no limitations on how much inside bars can hoagie include.
Umbrella Arrows (Umbrella Pattern)
Another really awesome 3 bar pattern that is really fun to trade. Umbrella occurs when the candle before the previous candle is a pin bar or a tail bar and the body of the previous candle is within the shadow or a wick of the candle before. The umbrella is triggered once the high or low of the previous bar is broken. Umbrellas are more frequent than Hoagies but occur much less than the Scallops.
Outside Bar Wedges (Outside Bar Pattern)
Pretty much self-explanatory candlestick pattern. Outside Bar is basically any bar that peaks outside of the both ends of the previous candle. So the range of the candle is higher & it looked beyond the high and beyond the low of the previous candle. These candles are signalizing the potenial momentum change. Ouside Bars usually occur at the tops or bottoms of the moves. I decided to add them because they can serve as a great addition to these scalping patterns.
Signal vs. SignalBreak Mode
The trigger can be viewed in two different ways:
1. Signal: Plots the trigger before the trigger bar, basically right when the pattern is formed but NOT YET triggered. The signal is triggered once the next candle break the high or low of the current candle.
2. SignalBrake: Plots the trigger after the break of the high or low of the actual pattern. It is basically a candle after the signal candle. (Signal is better for trading because it gives you time to prepare for the actual break of the high or low = the actual signal. SignalBrake is great for looking back in history only for the patterns that actually traded).
Pin Bar BTW Ratio
Pin Bar (Body-To-Wick) Ratio represents the size of the body of a pin bar candle for Eat the Tail and Umbrella patterns. Pin Bar BTW Ratio measures the ratio between the wick & the body of the candle. Ref. interval is 2.0 - 5.0 (ideal pin bar is 2.0 - 3.0 = the wick or a shadow is 2x - 3x bigger than the body of the candle)
ATR Stop & Target Labels
I also created three simple labels (tables) that can show you the ideal target & stop as well as the current ATR. Since LNL Scalper Arrows consist of high probability scalping patterns, a good rule of thumb to follow is to use a half of the current ATR as a target and a current ATR as a stop (or two times the target). So if the current 7 period ATR is 30 the target would be 15 pts. and a stop around 30 pts. With such a risk management you should aim for a win rate 70% or higher. Obviously you can adjust the risk management in the settings to your personal preference.
Low Range vs. High Range Markets
There are two major downsides with the Scalper Arrows:
1. You need volume and a volatility. These patterns really do struggle in ranging "boring" sideways action. It is absolutely crucial to recognize the current market environment and really stay cautions and (or completely out) in case the chop continues. Adding something like DMI can help you recognize the potential flat markets.
2. Not only do you need volume & momentum, you also need a decent range. This indicator works better on a rangy market such as NQ futures or YM. But are much tougher to trade on lower range markets such as some stocks or ZB futures or basically any other lower range market.
Hope it helps.

libhs.log.DEMO◼ Overview
This is a demonstration of dual logging library I have ported from my personal use for public use. Please start bar replay from Bar#4, and progress automatically slowly or manually.You would need to go through 450+ bars to see the full capability.
Logger=A dual logging library for developers. Tradingview lacks logging capability. This library provided logging while developing your scripts and is to be used by developers when developing and debugging their scripts.
Using this library would potentially slow down you scripts. Hence, use this for debugging only. Once your code is as you would like it to be, remove the logging code.
◼︎ Usage (Console):
Console = A sleek single cell logging with a limit of 4096 characters. When you dont need a large logging capability.
//@version=5
indicator("demo.Console", overlay=true)
plot(na)
import GETpacman/log/2 as logger
var console = logger.log.new()
console.init() // init() should be called as first line after variable declaration
console.FrameColor:=color.green
console.log('\n')
console.log('\n')
console.log('Hello World')
console.log('\n')
console.log('\n')
console.ShowStatusBar:=true
console.StatusBarAtBottom:=true
console.FrameColor:=color.blue //settings can be changed anytime before show method is called. Even twice. The last call will set the final value
console.ShowHeader:=false //this wont throw error but is not used for console
console.show(position=position.bottom_right) //this should be the last line of your code, after all methods and settings have been dealt with.
◼︎ Usage (Logx):
Logx = Multiple columns logging with a limit of 4096 characters each message. When you need to log large number of messages.
//@version=5
indicator("demo.Logx", overlay=true)
plot(na)
import GETpacman/log/2 as logger
var logx = logger.log.new()
logx.init() // init() should be called as first line after variable declaration
logx.FrameColor:=color.green
logx.log('\n')
logx.log('\n')
logx.log('Hello World')
logx.log('\n')
logx.log('\n')
logx.ShowStatusBar:=true
logx.StatusBarAtBottom:=true
logx.ShowQ3:=false
logx.ShowQ4:=false
logx.ShowQ5:=false
logx.ShowQ6:=false
logx.FrameColor:=color.olive //settings can be changed anytime before show method is called. Even twice. The last call will set the final value
logx.show(position=position.top_right) //this should be the last line of your code, after all methods and settings have been dealt with.
◼︎ Fields (with default settings)
▶︎ IsConsole = True Log will act as Console if true, otherwise it will act as Logx
▶︎ ShowHeader = True (Log only) Will show a header at top or bottom of logx.
▶︎ HeaderAtTop = True (Log only) Will show the header at the top, or bottom if false, if ShowHeader is true.
▶︎ ShowStatusBar = True Will show a status bar at the bottom
▶︎ StatusBarAtBottom = True Will show the status bar at the bottom, or top if false, if ShowHeader is true.
▶︎ ShowMetaStatus = True Will show the meta info within status bar (Current Bar, characters left in console, Paging On Every Bar, Console dumped data etc)
▶︎ ShowBarIndex = True Logx will show column for Bar Index when the message was logged. Console will add Bar index at the front of logged messages
▶︎ ShowDateTime = True Logx will show column for Date/Time passed with the logged message logged. Console will add Date/Time at the front of logged messages
▶︎ ShowLogLevels = True Logx will show column for Log levels corresponding to error codes. Console will log levels in the status bar
▶︎ ReplaceWithErrorCodes = True (Log only) Logx will show error codes instead of log levels, if ShowLogLevels is switched on
▶︎ RestrictLevelsToKey7 = True Log levels will be restricted to Ley 7 codes - TRACE, DEBUG, INFO, WARNING, ERROR, CRITICAL, FATAL
▶︎ ShowQ1 = True (Log only) Show the column for Q1
▶︎ ShowQ2 = True (Log only) Show the column for Q2
▶︎ ShowQ3 = True (Log only) Show the column for Q3
▶︎ ShowQ4 = True (Log only) Show the column for Q4
▶︎ ShowQ5 = True (Log only) Show the column for Q5
▶︎ ShowQ6 = True (Log only) Show the column for Q6
▶︎ ColorText = True Log/Console will color text as per error codes
▶︎ HighlightText = True Log/Console will highlight text (like denoting) as per error codes
▶︎ AutoMerge = True (Log only) Merge the queues towards the right if there is no data in those queues.
▶︎ PageOnEveryBar = True Clear data from previous bars on each new bar, in conjuction with PageHistory setting.
▶︎ MoveLogUp = True Move log in up direction. Setting to false will push logs down.
▶︎ MarkNewBar = True On each change of bar, add a marker to show the bar has changed
▶︎ PrefixLogLevel = True (Console only) Prefix all messages with the log level corresponding to error code.
▶︎ MinWidth = 40 Set the minimum width needed to be seen. Prevents logx/console shrinking below these number of characters.
▶︎ TabSizeQ1 = 0 If set to more than one, the messages on Q1 or Console messages will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ2 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ3 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ4 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ5 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ6 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ PageHistory = 0 Used with PageOnEveryBar. Determines how many historial pages to keep.
▶︎ HeaderQbarIndex = 'Bar#' (Logx only) The header to show for Bar Index
▶︎ HeaderQdateTime = 'Date' (Logx only) The header to show for Date/Time
▶︎ HeaderQerrorCode = 'eCode' (Logx only) The header to show for Error Codes
▶︎ HeaderQlogLevel = 'State' (Logx only) The header to show for Log Level
▶︎ HeaderQ1 = 'h.Q1' (Logx only) The header to show for Q1
▶︎ HeaderQ2 = 'h.Q2' (Logx only) The header to show for Q2
▶︎ HeaderQ3 = 'h.Q3' (Logx only) The header to show for Q3
▶︎ HeaderQ4 = 'h.Q4' (Logx only) The header to show for Q4
▶︎ HeaderQ5 = 'h.Q5' (Logx only) The header to show for Q5
▶︎ HeaderQ6 = 'h.Q6' (Logx only) The header to show for Q6
▶︎ Status = '' Set the status to this text.
▶︎ HeaderColor Set the color for the header
▶︎ HeaderColorBG Set the background color for the header
▶︎ StatusColor Set the color for the status bar
▶︎ StatusColorBG Set the background color for the status bar
▶︎ TextColor Set the color for the text used without error code or code 0.
▶︎ TextColorBG Set the background color for the text used without error code or code 0.
▶︎ FrameColor Set the color for the frame around Logx/Console
▶︎ FrameSize = 1 Set the size of the frame around Logx/Console
▶︎ CellBorderSize = 0 Set the size of the border around cells.
▶︎ CellBorderColor Set the color for the border around cells within Logx/Console
▶︎ SeparatorColor = gray Set the color of separate in between Console/Logx Attachment
◼︎ Methods (summary)
● init ▶︎ Initialise the log
● log ▶︎ Log the messages. Use method show to display the messages
● page ▶︎ Clear messages from previous bar while logging messages on this bar.
● show ▶︎ Shows a table displaying the logged messages
● clear ▶︎ Clears the log of all messages
● resize ▶︎ Resizes the log. If size is for reduction then oldest messages are lost first.
● turnPage ▶︎ When called, all messages marked with previous page, or from start are cleared
● dateTimeFormat ▶︎ Sets the date time format to be used when displaying date/time info.
● resetTextColor ▶︎ Reset Text Color to library default
● resetTextBGcolor ▶︎ Reset Text BG Color to library default
● resetHeaderColor ▶︎ Reset Header Color to library default
● resetHeaderBGcolor ▶︎ Reset Header BG Color to library default
● resetStatusColor ▶︎ Reset Status Color to library default
● resetStatusBGcolor ▶︎ Reset Status BG Color to library default
● setColors ▶︎ Sets the colors to be used for corresponding error codes
● setColorsBG ▶︎ Sets the background colors to be used for corresponding error codes. If not match of error code, then text color used.
● setColorsHC ▶︎ Sets the highlight colors to be used for corresponding error codes.If not match of error code, then text bg color used.
● resetColors ▶︎ Reset the colors to library default (Total 36, not including error code 0)
● resetColorsBG ▶︎ Reset the background colors to library default
● resetColorsHC ▶︎ Reset the highlight colors to library default
● setLevelNames ▶︎ Set the log level names to be used for corresponding error codes. If not match of error code, then empty string used.
● resetLevelNames ▶︎ Reset the log level names to library default. (Total 36) 1=TRACE, 2=DEBUG, 3=INFO, 4=WARNING, 5=ERROR, 6=CRITICAL, 7=FATAL
● attach ▶︎ Attaches a console to an existing Logx, allowing to have dual logging system independent of each other
● detach ▶︎ Detaches an already attached console from Logx

loggerLibrary "logger"
◼ Overview
A dual logging library for developers. Tradingview lacks logging capability. This library provides logging while developing your scripts and is to be used by developers when developing and debugging their scripts.
Using this library would potentially slow down you scripts. Hence, use this for debugging only. Once your code is as you would like it to be, remove the logging code.
◼︎ Usage (Console):
Console = A sleek single cell logging with a limit of 4096 characters. When you dont need a large logging capability.
//@version=5
indicator("demo.Console", overlay=true)
plot(na)
import GETpacman/logger/1 as logger
var console = logger.log.new()
console.init() // init() should be called as first line after variable declaration
console.FrameColor:=color.green
console.log('\n')
console.log('\n')
console.log('Hello World')
console.log('\n')
console.log('\n')
console.ShowStatusBar:=true
console.StatusBarAtBottom:=true
console.FrameColor:=color.blue //settings can be changed anytime before show method is called. Even twice. The last call will set the final value
console.ShowHeader:=false //this wont throw error but is not used for console
console.show(position=position.bottom_right) //this should be the last line of your code, after all methods and settings have been dealt with.
◼︎ Usage (Logx):
Logx = Multiple columns logging with a limit of 4096 characters each message. When you need to log large number of messages.
//@version=5
indicator("demo.Logx", overlay=true)
plot(na)
import GETpacman/logger/1 as logger
var logx = logger.log.new()
logx.init() // init() should be called as first line after variable declaration
logx.FrameColor:=color.green
logx.log('\n')
logx.log('\n')
logx.log('Hello World')
logx.log('\n')
logx.log('\n')
logx.ShowStatusBar:=true
logx.StatusBarAtBottom:=true
logx.ShowQ3:=false
logx.ShowQ4:=false
logx.ShowQ5:=false
logx.ShowQ6:=false
logx.FrameColor:=color.olive //settings can be changed anytime before show method is called. Even twice. The last call will set the final value
logx.show(position=position.top_right) //this should be the last line of your code, after all methods and settings have been dealt with.
◼︎ Fields (with default settings)
▶︎ IsConsole = True Log will act as Console if true, otherwise it will act as Logx
▶︎ ShowHeader = True (Log only) Will show a header at top or bottom of logx.
▶︎ HeaderAtTop = True (Log only) Will show the header at the top, or bottom if false, if ShowHeader is true.
▶︎ ShowStatusBar = True Will show a status bar at the bottom
▶︎ StatusBarAtBottom = True Will show the status bar at the bottom, or top if false, if ShowHeader is true.
▶︎ ShowMetaStatus = True Will show the meta info within status bar (Current Bar, characters left in console, Paging On Every Bar, Console dumped data etc)
▶︎ ShowBarIndex = True Logx will show column for Bar Index when the message was logged. Console will add Bar index at the front of logged messages
▶︎ ShowDateTime = True Logx will show column for Date/Time passed with the logged message logged. Console will add Date/Time at the front of logged messages
▶︎ ShowLogLevels = True Logx will show column for Log levels corresponding to error codes. Console will log levels in the status bar
▶︎ ReplaceWithErrorCodes = True (Log only) Logx will show error codes instead of log levels, if ShowLogLevels is switched on
▶︎ RestrictLevelsToKey7 = True Log levels will be restricted to Ley 7 codes - TRACE, DEBUG, INFO, WARNING, ERROR, CRITICAL, FATAL
▶︎ ShowQ1 = True (Log only) Show the column for Q1
▶︎ ShowQ2 = True (Log only) Show the column for Q2
▶︎ ShowQ3 = True (Log only) Show the column for Q3
▶︎ ShowQ4 = True (Log only) Show the column for Q4
▶︎ ShowQ5 = True (Log only) Show the column for Q5
▶︎ ShowQ6 = True (Log only) Show the column for Q6
▶︎ ColorText = True Log/Console will color text as per error codes
▶︎ HighlightText = True Log/Console will highlight text (like denoting) as per error codes
▶︎ AutoMerge = True (Log only) Merge the queues towards the right if there is no data in those queues.
▶︎ PageOnEveryBar = True Clear data from previous bars on each new bar, in conjuction with PageHistory setting.
▶︎ MoveLogUp = True Move log in up direction. Setting to false will push logs down.
▶︎ MarkNewBar = True On each change of bar, add a marker to show the bar has changed
▶︎ PrefixLogLevel = True (Console only) Prefix all messages with the log level corresponding to error code.
▶︎ MinWidth = 40 Set the minimum width needed to be seen. Prevents logx/console shrinking below these number of characters.
▶︎ TabSizeQ1 = 0 If set to more than one, the messages on Q1 or Console messages will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ2 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ3 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ4 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ5 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ TabSizeQ6 = 0 If set to more than one, the messages on Q2 will indent by this size based on error code (Max 4 used)
▶︎ PageHistory = 0 Used with PageOnEveryBar. Determines how many historial pages to keep.
▶︎ HeaderQbarIndex = 'Bar#' (Logx only) The header to show for Bar Index
▶︎ HeaderQdateTime = 'Date' (Logx only) The header to show for Date/Time
▶︎ HeaderQerrorCode = 'eCode' (Logx only) The header to show for Error Codes
▶︎ HeaderQlogLevel = 'State' (Logx only) The header to show for Log Level
▶︎ HeaderQ1 = 'h.Q1' (Logx only) The header to show for Q1
▶︎ HeaderQ2 = 'h.Q2' (Logx only) The header to show for Q2
▶︎ HeaderQ3 = 'h.Q3' (Logx only) The header to show for Q3
▶︎ HeaderQ4 = 'h.Q4' (Logx only) The header to show for Q4
▶︎ HeaderQ5 = 'h.Q5' (Logx only) The header to show for Q5
▶︎ HeaderQ6 = 'h.Q6' (Logx only) The header to show for Q6
▶︎ Status = '' Set the status to this text.
▶︎ HeaderColor Set the color for the header
▶︎ HeaderColorBG Set the background color for the header
▶︎ StatusColor Set the color for the status bar
▶︎ StatusColorBG Set the background color for the status bar
▶︎ TextColor Set the color for the text used without error code or code 0.
▶︎ TextColorBG Set the background color for the text used without error code or code 0.
▶︎ FrameColor Set the color for the frame around Logx/Console
▶︎ FrameSize = 1 Set the size of the frame around Logx/Console
▶︎ CellBorderSize = 0 Set the size of the border around cells.
▶︎ CellBorderColor Set the color for the border around cells within Logx/Console
▶︎ SeparatorColor = gray Set the color of separate in between Console/Logx Attachment
◼︎ Methods (summary)
● init ▶︎ Initialise the log
● log ▶︎ Log the messages. Use method show to display the messages
● page ▶︎ Clear messages from previous bar while logging messages on this bar.
● show ▶︎ Shows a table displaying the logged messages
● clear ▶︎ Clears the log of all messages
● resize ▶︎ Resizes the log. If size is for reduction then oldest messages are lost first.
● turnPage ▶︎ When called, all messages marked with previous page, or from start are cleared
● dateTimeFormat ▶︎ Sets the date time format to be used when displaying date/time info.
● resetTextColor ▶︎ Reset Text Color to library default
● resetTextBGcolor ▶︎ Reset Text BG Color to library default
● resetHeaderColor ▶︎ Reset Header Color to library default
● resetHeaderBGcolor ▶︎ Reset Header BG Color to library default
● resetStatusColor ▶︎ Reset Status Color to library default
● resetStatusBGcolor ▶︎ Reset Status BG Color to library default
● setColors ▶︎ Sets the colors to be used for corresponding error codes
● setColorsBG ▶︎ Sets the background colors to be used for corresponding error codes. If not match of error code, then text color used.
● setColorsHC ▶︎ Sets the highlight colors to be used for corresponding error codes.If not match of error code, then text bg color used.
● resetColors ▶︎ Reset the colors to library default (Total 36, not including error code 0)
● resetColorsBG ▶︎ Reset the background colors to library default
● resetColorsHC ▶︎ Reset the highlight colors to library default
● setLevelNames ▶︎ Set the log level names to be used for corresponding error codes. If not match of error code, then empty string used.
● resetLevelNames ▶︎ Reset the log level names to library default. (Total 36) 1=TRACE, 2=DEBUG, 3=INFO, 4=WARNING, 5=ERROR, 6=CRITICAL, 7=FATAL
● attach ▶︎ Attaches a console to an existing Logx, allowing to have dual logging system independent of each other
● detach ▶︎ Detaches an already attached console from Logx
method clear(this)
Clears all the queue, including bar_index and time queues, of existing messages
Namespace types: log
Parameters:
this (log)
method resize(this, rows)
Resizes the message queues. If size is decreased then removes the oldest messages
Namespace types: log
Parameters:
this (log)
rows (int) : The new size needed for the queues. Default value is 40.
method dateTimeFormat(this, format)
Re/set the date time format used for displaying date and time. Default resets to dd.MMM.yy HH:mm
Namespace types: log
Parameters:
this (log)
format (string)
method resetTextColor(this)
Resets the text color of the log to library default.
Namespace types: log
Parameters:
this (log)
method resetTextColorBG(this)
Resets the background color of the log to library default.
Namespace types: log
Parameters:
this (log)
method resetHeaderColor(this)
Resets the color used for Headers, to library default.
Namespace types: log
Parameters:
this (log)
method resetHeaderColorBG(this)
Resets the background color used for Headers, to library default.
Namespace types: log
Parameters:
this (log)
method resetStatusColor(this)
Resets the text color of the status row, to library default.
Namespace types: log
Parameters:
this (log)
method resetStatusColorBG(this)
Resets the background color of the status row, to library default.
Namespace types: log
Parameters:
this (log)
method resetFrameColor(this)
Resets the color used for the frame around the log table, to library default.
Namespace types: log
Parameters:
this (log)
method resetColorsHC(this)
Resets the color used for the highlighting when Highlight Text option is used, to library default
Namespace types: log
Parameters:
this (log)
method resetColorsBG(this)
Resets the background color used for setting the background color, when the Color Text option is used, to library default
Namespace types: log
Parameters:
this (log)
method resetColors(this)
Resets the color used for respective error codes, when the Color Text option is used, to library default
Namespace types: log
Parameters:
this (log)
method setColors(this, c)
Sets the colors corresponding to error codes
Index 0 of input array c is color is reserved for future use.
Index 1 of input array c is color for debug code 1.
Index 2 of input array c is color for debug code 2.
There are 2 modes of coloring
1 . Using the Foreground color
2 . Using the Foreground color as background color and a white/black/gray color as foreground color
This is denoting or highlighting. Which effectively puts the foreground color as background color
Namespace types: log
Parameters:
this (log)
c (color ) : Array of colors to be used for corresponding error codes. If the corresponding code is not found, then text color is used
method setColorsHC(this, c)
Sets the highlight colors corresponding to error codes
Index 0 of input array c is color is reserved for future use.
Index 1 of input array c is color for debug code 1.
Index 2 of input array c is color for debug code 2.
There are 2 modes of coloring
1 . Using the Foreground color
2 . Using the Foreground color as background color and a white/black/gray color as foreground color
This is denoting or highlighting. Which effectively puts the foreground color as background color
Namespace types: log
Parameters:
this (log)
c (color ) : Array of highlight colors to be used for corresponding error codes. If the corresponding code is not found, then text color BG is used
method setColorsBG(this, c)
Sets the highlight colors corresponding to debug codes
Index 0 of input array c is color is reserved for future use.
Index 1 of input array c is color for debug code 1.
Index 2 of input array c is color for debug code 2.
There are 2 modes of coloring
1 . Using the Foreground color
2 . Using the Foreground color as background color and a white/black/gray color as foreground color
This is denoting or highlighting. Which effectively puts the foreground color as background color
Namespace types: log
Parameters:
this (log)
c (color ) : Array of background colors to be used for corresponding error codes. If the corresponding code is not found, then text color BG is used
method resetLevelNames(this, prefix, suffix)
Resets the log level names used for corresponding error codes
With prefix/suffix, the default Level name will be like => prefix + Code + suffix
Namespace types: log
Parameters:
this (log)
prefix (string) : Prefix to use when resetting level names
suffix (string) : Suffix to use when resetting level names
method setLevelNames(this, names)
Resets the log level names used for corresponding error codes
Index 0 of input array names is reserved for future use.
Index 1 of input array names is name used for error code 1.
Index 2 of input array names is name used for error code 2.
Namespace types: log
Parameters:
this (log)
names (string ) : Array of log level names be used for corresponding error codes. If the corresponding code is not found, then an empty string is used
method init(this, rows, isConsole)
Sets up data for logging. It consists of 6 separate message queues, and 3 additional queues for bar index, time and log level/error code. Do not directly alter the contents, as library could break.
Namespace types: log
Parameters:
this (log)
rows (int) : Log size, excluding the header/status. Default value is 50.
isConsole (bool) : Whether to init the log as console or logx. True= as console, False = as Logx. Default is true, hence init as console.
method log(this, ec, m1, m2, m3, m4, m5, m6, tv, log)
Logs messages to the queues , including, time/date, bar_index, and error code
Namespace types: log
Parameters:
this (log)
ec (int) : Error/Code to be assigned.
m1 (string) : Message needed to be logged to Q1, or for console.
m2 (string) : Message needed to be logged to Q2. Not used/ignored when in console mode
m3 (string) : Message needed to be logged to Q3. Not used/ignored when in console mode
m4 (string) : Message needed to be logged to Q4. Not used/ignored when in console mode
m5 (string) : Message needed to be logged to Q5. Not used/ignored when in console mode
m6 (string) : Message needed to be logged to Q6. Not used/ignored when in console mode
tv (int) : Time to be used. Default value is time, which logs the start time of bar.
log (bool) : Whether to log the message or not. Default is true.
method page(this, ec, m1, m2, m3, m4, m5, m6, tv, page)
Logs messages to the queues , including, time/date, bar_index, and error code. All messages from previous bars are cleared
Namespace types: log
Parameters:
this (log)
ec (int) : Error/Code to be assigned.
m1 (string) : Message needed to be logged to Q1, or for console.
m2 (string) : Message needed to be logged to Q2. Not used/ignored when in console mode
m3 (string) : Message needed to be logged to Q3. Not used/ignored when in console mode
m4 (string) : Message needed to be logged to Q4. Not used/ignored when in console mode
m5 (string) : Message needed to be logged to Q5. Not used/ignored when in console mode
m6 (string) : Message needed to be logged to Q6. Not used/ignored when in console mode
tv (int) : Time to be used. Default value is time, which logs the start time of bar.
page (bool) : Whether to log the message or not. Default is true.
method turnPage(this, turn)
Set the messages to be on a new page, clearing messages from previous page.
This is not dependent on PageHisotry option, as this method simply just clears all the messages, like turning old pages to a new page.
Namespace types: log
Parameters:
this (log)
turn (bool)
method show(this, position, hhalign, hvalign, hsize, thalign, tvalign, tsize, show, attach)
Display Message Q, Index Q, Time Q, and Log Levels
All options for postion/alignment accept TV values, such as position.bottom_right, text.align_left, size.auto etc.
Namespace types: log
Parameters:
this (log)
position (string) : Position of the table used for displaying the messages. Default is Bottom Right.
hhalign (string) : Horizontal alignment of Header columns
hvalign (string) : Vertical alignment of Header columns
hsize (string) : Size of Header text Options
thalign (string) : Horizontal alignment of all messages
tvalign (string) : Vertical alignment of all messages
tsize (string) : Size of text across the table
show (bool) : Whether to display the logs or not. Default is true.
attach (log) : Console that has been attached via attach method. If na then console will not be shown
method attach(this, attach, position)
Attaches a console to Logx, or moves already attached console around Logx
All options for position/alignment accept TV values, such as position.bottom_right, text.align_left, size.auto etc.
Namespace types: log
Parameters:
this (log)
attach (log) : Console object that has been previously attached.
position (string) : Position of Console in relation to Logx. Can be Top, Right, Bottom, Left. Default is Bottom. If unknown specified then defaults to bottom.
method detach(this, attach)
Detaches the attached console from Logx.
All options for position/alignment accept TV values, such as position.bottom_right, text.align_left, size.auto etc.
Namespace types: log
Parameters:
this (log)
attach (log) : Console object that has been previously attached.

Weis V5 zigzag jayySomehow, I deleted version 5 of the zigzag script. Same name. I have added some older notes describing how the Weis Wave works.
I have also changed the date restriction that stopped the script from working after Dec 31, 2022.
What you see here is the Weis zigzag wave plotted directly on the price chart. This script is the companion to the Weis cumulative wave volume script.
What is a Weis wave? David Weis has been recognized as a Wyckoff method analyst he has written two books one of which, Trades About to Happen, describes the evolution of the now-popular Weis wave. The method employed by Weis is to identify waves of price action and to compare the strength of the waves on characteristics of wave strength. Chief among the characteristics of strength is the cumulative volume of the wave. There are other markers that Weis uses as well for example how the actual price difference between the start of the Weis wave from start to finish. Weis also uses time, particularly when using a Renko chart
David Weis did a futures io video which is a popular source of information about his method. (Search David Weis and futures.io. I strongly suggest you also read “Trades About to Happen” by David Weis.
This will get you up and running more quickly when studying charts. However, you should choose the Traditional method to be true to David Weis technique as described in his book "Trades About to Happen" and in the Futures IO Webcast featuring David Weis
. The Weis pip zigzag wave shows how far in terms of bar close price a Weis wave has traveled through the duration of a Weis wave. The Weis zigzag wave is used in combination with the Weis cumulative volume wave. The two waves should be set to the same "wave size".
To use this script, you must set the wave size: Using the traditional Weis method simply enter the desired wave size in the box "How should wave size be calculated", in this example I am using a traditional wave size of .25. Each wave for each security and each timeframe requires its own wave size. Although not the traditional method devised by David Weis a more automatic way to set wave size would be to use Average True Range (ATR). Using ATR is not the true Weis method but it does give you similar waves and, importantly, without the hassle described above. Once the Weis wave size is set then the zigzag wave will be shown with volume. Because Weis used the closing price of a wave to define waves a line Bar highs and bar lows are not captured by the Weis Wave. The default script setting is now cumulative volume waves using an ATR of 7 and a multiplication factor of .5.
To display volume in a way that does not crowd out neighbouring volumes Weis displayed volume as a maximum of 3 digits (usually). Consider two Weis Wave volumes 176,895,570 and 2,654,763,889. To display wave volume as three digits it is necessary to take a number such as 176,895,570 and truncate it. 176,895,570 can be represented as 177 X 10 to the power of 6. The number displayed must also be relative to other numbers in the field. If the highest volume on the page is: 2,654,763,889 and with only three numbers available to display the result the value shown must be 265 (265 X 10 to the power of 7). Since 176,895,570 is an order of magnitude smaller than 2,654,763,889 therefore 175,895,570 must be shown as 18 instead of 177. In this way, the relative magnitudes of the two volumes can be understood. All numbers in the field of view must be truncated by the same order of magnitude to make the relative volumes understandable. The script attempts to calculate the order of magnitude value automatically. If you see a red number in the field of view it means the script has failed to do the calculation automatically and you should use the manual method – use the dialogue box “Calculate truncated wave value automatically or manually”. Scroll down from the automatic method and select manual. Once "manual" is selected the values displayed become the power values or multipliers for each wave.
Using the manual method you will select a “Multiplier” in the next dialogue box. Scan the field and select the largest value in the field of view (visible chart) is the multiplier of interest. If you select a lower number than the maximum value will see at least one red “up”. If you are too high you will see at least one red “down”. Scroll in the direction recommended or the values on the screen will be totally incorrect. With volume truncated to the highest order values, the eye can quickly get a feel for relative volumes. It also reduces the crowding and overlapping of values on the screen. You can opt to show the full volume to help get a sense of the magnitude of the true volumes.
How does the script determine if a Weis wave is continuing to grow or not?
The script evaluates the closing price of each new bar relative to the "Weis wave size". Suppose the current bar closes at a new low close, within the current down wave, at $30.00. If the Weis wave size is $0.10 then the algorithm will remember the $30.00 close and compare it to the close of the next bar. If the bar close price does not close equal to or lower than $30.00 or close equal to or higher than $30.10 then the wave is still a down wave with a current low of $30.00. This is true even if the bar low is less than $30.00 or the bar high is greater than 30.10 – only the bar’s closing price matters. If a bar's closing price climbs back up to a close of $30.11 then because the closing price has moved more than $0.10 (the Weis wave size) then that is a wave reversal with a new up-trending wave. In the above example if there was currently a downward trending wave and the bar closes were as follows $30.00, $30.09, $30.01, $30.05, $30.10 The wave direction would continue to stay downward trending until the close of $30.10 was achieved. As such $30.00 would be the low and the following closes $30.09, $30.01, $30.05 would be allocated to the new upward-trending wave. If however There was a series of bar closes like this $30.00, $30.09, $30.01, $30.05, $29.99 since none of the closes was equal to above the 10-cent reversal target of $30.10 but instead, a new Weis wave low was achieved ($29.99). As such the closes of $30.09, $30.01, $30.05 would all be attributed to the continued down-trending wave with a current low of $29.99, even though the closing price for the interim bars was above $30.00. Now that the Weis Wave low is now 429.99 then, in order to reverse this continued downtrend price will need to close at or above $30.09 on subsequent bar closes assuming now new low bar close is achieved. With large wave sizes, wave direction can be in limbo for many bars before a close either renews wave direction or reverses it and confirms wave direction as either a reversal or a continuation. On the zig-zag, a wave line and its volume will not be "printed" until a wave reversal is confirmed.
The wave attribution is similar when using other methods to define wave size. If ATR is used for wave size instead of a traditional wave constant size such as $0.10 or $2 or 2000 pips or ... then the wave size is calculated based on current ATR instead of the Weis wave constant (Traditional selected value).
I have the option to display pseudo-Ord volume. In truth, Ord used more traditional zig-zag pivots of bar highs and lows. Waves using closes as pivots can have some significant differences. This difference can be lessened by using smaller time frames and larger wave sizes.
There are other options such to display the delta price or pip size of a Weis Wave, the number of bars in a wave, and a few other options.

Candlestick Pattern Criteria and Analysis Indicator█ OVERVIEW
Define, then locate the presence of a candle that fits a specific criteria. Run a basic calculation on what happens after such a candle occurs.
Here, I’m not giving you an edge, but I’m giving you a clear way to find one.
IMPORTANT NOTE: PLEASE READ:
THE INDICATOR WILL ALWAYS INITIALLY LOAD WITH A RUNTIME ERROR. WHEN INITIALLY LOADED THERE NO CRITERIA SELECTED.
If you do not select a criteria or run a search for a criteria that doesn’t exist, you will get a runtime error. If you want to force the chart to load anyway, enable the debug panel at the bottom of the settings menu.
Who this is for:
- People who want to engage in TradingView for tedious and challenging data analysis related to candlestick measurement and occurrence rate and signal bar relationships with subsequent bars. People who don’t know but want to figure out what a strong bullish bar or a strong bearish bar is.
Who this is not for:
- People who want to be told by an indicator what is good or bad or buy or sell. Also, not for people that don’t have any clear idea on what they think is a strong bullish bar or a strong bearish bar and aren’t willing to put in the work.
Recommendation: Use on the candle resolution that accurately reflects your typical holding period. If you typically hold a trade for 3 weeks, use 3W candles. If you hold a trade for 3 minutes, use 3m candles.
Tldr; Read the tool tips and everything above this line. Let me know any issues that arise or questions you have.
█ CONCEPTS
Many trading styles indicate that a certain candle construct implies a bearish or bullish future for price. That said, it is also common to add to that idea that the context matters. Of course, this is how you end up with all manner of candlestick patterns accounting for thousands of pages of literature. No matter the context though, we can distill a discretionary trader's decision to take a trade based on one very basic premise: “A trader decides to take a trade on the basis of the rightmost candle's construction and what he/she believes that candle construct implies about the future price.” This indicator vets that trader’s theory in the most basic way possible. It finds the instances of any candle construction and takes a look at what happens on the next bar. This current bar is our “Signal Bar.”
█ GUIDE
I said that we vet the theory in the most basic way possible. But, in truth, this indicator is very complex as a result of there being thousands of ways to define a ‘strong’ candle. And you get to define things on a very granular level with this indicator.
Features:
1. Candle Highlighting
When the user’s criteria is met, the candle is highlighted on the chart.
The following candle is highlighted based on whether it breaks out, breaks down, or is an inside bar.
2. User-Defined Criteria
Criteria that you define include:
Candle Type: Bull bars, Bear bars, or both
Candle Attributes
Average Size based on Standard Deviation or Average of all potential bars in price history
Search within a specific price range
Search within a specific time range
Clarify time range using defined sessions and with or without weekends
3. Strike Lines on Candle
Often you want to know how price reacts when it gets back to a certain candle. Also it might be true that candle types cluster in a price region. This can be identified visually by adding lines that extend right on candles that fit the criteria.
4. User-Defined Context
Labeled “Alternative Criteria,” this facet of the script allows the user to take the context provided from another indicator and import it into the indicator to use as a overriding criteria. To account for the fact that the external indicator must be imported as a float value, true (criteria of external indicator is met) must be imported as 1 and false (criteria of external indicator is not met) as 0. Basically a binary Boolean. This can be used to create context, such as in the case of a traditional fractal, or can be used to pair with other signals.
If you know how to code in Pinescript, you can save a copy and simply add your own code to the section indicated in the code and set your bull and bear variables accordingly and the code should compile just fine with no further editing needed.
Included with the script to maximize out-of-the-box functionality, there is preloaded as alternative criteria a code snippet. The criteria is met on the bull side when the current candle close breaks out above the prior candle high. The bear criteria is met when the close breaks below the prior candle. When Alternate Criteria is run by itself, this is the only criteria set and bars are highlighted when it is true. You can qualify these candles by adding additional attributes that you think would fit well.
Using Alternative Criteria, you are essentially setting a filter for the rest of the criteria.
5. Extensive Read Out in the Data Window (right side bar pop out window).
As you can see in the thumbnail, there is pasted a copy of the Data Window Dialogue. I am doubtful I can get the thumbnail to load up perfectly aligned. Its hard to get all these data points in here. It may be better suited for a table at this point. Let me know what you think.
The primary, but not exclusive, purpose of what is in the Data Window is to talk about how often your criteria happens and what happens on the next bar. There are a lot of pieces to this.
Red = Values pertaining to the size of the current bar only
Blue = Values pertaining or related to the total number of signals
Green = Values pertaining to the signal bars themselves, including their measurements
Purple = Values pertaining to bullish bars that happen after the signal bar
Fuchsia = Values pertaining to bearish bars that happen after the signal bar
Lime = Last four rows which are your percentage occurrence vs total signals percentages
The best way I can explain how to understand parts you don’t understand otherwise in the data window is search the title of the row in the code using ‘ctrl+f’ and look at it and see if it makes more sense.
█ [b}Available Candle Attributes
Candle attributes can be used in any combination. They include:
[*}Bodies
[*}High/Low Range
[*}Upper Wick
[*}Lower Wick
[*}Average Size
[*}Alternative Criteria
Criteria will evaluate each attribute independently. If none is set for a particular attribute it is bypassed.
Criteria Quantity can be in Ticks, Points, or Percentage. For percentage keep in mind if using anything involving the candle range will not work well with percentage.
Criteria Operators are “Greater Than,” “Less Than,” and “Threshold.” Threshold means within a range of two numbers.
█ Problems with this methodology and opportunities for future development:
#1 This kind of work is hard.
If you know what you’re doing you might be able to find success changing out the inputs for loops and logging results in arrays or matrices, but to manually go through and test various criteria is a lot of work. However, it is rewarding. At the time of publication in early Oct 2022, you will quickly find that you get MUCH more follow through on bear bars than bull bars. That should be obvious because we’re in the middle of a bear market, but you can still work with the parameters and contextual inputs to determine what maximizes your probability. I’ve found configurations that yield 70% probability across the full series of bars. That’s an edge. That means that 70% of the time, when this criteria is met, the next bar puts you in profit.
#2 The script is VERY heavy.
Takes an eternity to load. But, give it a break, it’s doing a heck of a lot! There is 10 unique arrays in here and a loop that is a bit heavy but gives us the debug window.
#3 If you don’t have a clear idea its hard to know where to start.
There are a lot of levers to pull on in this script. Knowing which ones are useful and meaningful is very challenging. Combine that with long load times… its not great.
#4 Your brain is the only thing that can optimize your results because the criteria come from your mind.
Machine learning would be much more useful here, but for now, you are the machine. Learn.
#5 You can’t save your settings.
So, when you find a good combo, you’ll have to write it down elsewhere for future reference. It would be nice if we could save templates on custom indicators like we can on some of the built in drawing tools, but I’ve had no success in that. So, I recommend screenshotting your settings and saving them in Notion.so or some other solid record keeping database. Then you can go back and retrieve those settings.
#6 no way to export these results into conditions that can be copy/pasted into another script.
Copy/Paste of labels or tables would be the best feature ever at this point. Because you could take the criteria and put it in a label, copy it and drop it into another strategy script or something. But… men can dream.
█ Opportunities to PineCoders Learn:
1. In this script I’m importing libraries, showing some of my libraries functionality. Hopefully that gives you some ideas on how to use them too.
The price displacement library (which I love!)
Creative and conventional ways of using debug()
how to display arrays and matrices on charts
I didn’t call in the library that holds the backtesting function. But, also demonstrating, you can always pull the library up and just copy/paste the function out of there and into your script. That’s fine to do a lot of the time.
2. I am using REALLY complicated logic in this script (at least for me). I included extensive descriptions of this ? : logic in the text of the script. I also did my best to bracket () my logic groups to demonstrate how they fit together, both for you and my future self.
3. The breakout, built-in, “alternative criteria” is actually a small bit of genius built in there if you want to take the time to understand that block of code and think about some of the larger implications of the method deployed.
As always, a big thank you to TradingView and the Pinescript community, the Pinescript pros who have mentored me, and all of you who I am privileged to help in their Pinescripting journey.
"Those who stay will become champions" - Bo Schembechler

Impactful pattern and candles pattern AlertThe Alertion indicator!
impactful pattern:
pattern that happen near the zone or in the zone at lower timeframe and give us entry and stop limit price.
It is helpful for price action traders and those who want to decrease their risk.
There are 3 IP patterns:
Quasimodo
Head and shoulder
whipsaw engulfing
These patterns may occur near the zone or may not occur but by them, you can decrease your trading risk for example you can
trade with half lot before IP pattern and enter with other half after pattern.
how to use?
for example:
you find zone at 1h timeframe for short position
when price enter to your zone
you run this indicator and choose your lower timeframe, for example 15m and click on short position.
Then make the alert by right-click on your chart and choose the add alert and at condition box choose the impactful pattern and then click on create
now wait for message :)
Candles pattern:
like reversal bar, key reversal bar, exhaustion bar, pin bar, two-bar reversal, tree-bar reversal, inside bar, outside bar
these occur when the trend turn, so it is usable when the price enter to your zone or near your zone.
This pattern can decrease your risk.
Inside bar and outside bar:
if this pattern engulf up, it is bullish pattern and if engulf down, it is bearish pattern.
what does this indicator do?
this indicator is for making alert
it helps you to decrease your risk and failure.
You optimize it to alert you when IP pattern happen or candle pattern happen or inside bar or outside bar engulfing or all of them.
For IP pattern, it will message you entry and stop limit price.
It works at 2 different timeframes, so you can make alert for example in 1h TF for candles pattern and 15m TF for IP pattern.
Indicator will alert you for candles pattern at your chart timeframe and for IP pattern at timeframe you've chosen when you run the indicator, and it is changeable
in setting.
setting options
TIMEFRAME
IP: select the timeframe for IP patterns it means when IP pattern happen at that timeframe the indicator will alert you
example = your TF is 1h, you found the supply zone and want to trade, note that IP pattern happen in lower TF, so you select 15m TF or TF lower than 1h.
Short position: select it if you want to make short position.
BUFFERING
indicator send you entry and stop limit price
you can change it by amount of percent
it is your strategy to change your entry and stop loss or not
example= in head and shoulder pattern at short position, the stop limit is high price of head in pattern
so the indicator will message you the exact price but if you want to put
your stop limit 5 percent upper than exact price you can enter 5 in front of stop loss
or you want to enter 5 percent lower than exact high price of shoulder, you can optimize it.
ALERTION
you choose what alert you want
IP alert or candle alert or inside and outside bar alert
type your text for alert
you can write additional text for your message
ADVANCE
IP alert frequency option:
1. Once per bar : indicator will alert you for IP pattern once at your chat timeframe bar, and you should wait til next bar for next alert.
2. Once per bar close : alert you when your chart timeframe bar closed and next alert will happen when next bar is closed.
3. All: alert you all the times IP pattern happen
pivot left and right bars: lower will find smaller pattern
at the END:
this indicator is not strategy
it is part of your strategy that help you to increase your winning rate.
It is helpful for scalping and candle patterns finding.
After you make an alert, you can delete the indicator or change your timeframe or make another alert, your previous alert won’t change.
Thank you all.
Real Woodies CCIAs always, this is not financial advice and use at your own risk. Trading is risky and can cost you significant sums of money if you are not careful. Make sure you always have a proper entry and exit plan that includes defining your risk before you enter a trade.
Ken Wood is a semi-famous trader that grew in popularity in the 1990s and early 2000s due to the establishment of one of the earliest trading forums online. This forum grew into "Woodie's CCI Club" due to Wood's love of his modified Commodity Channel Index (CCI) that he used extensively. From what I can tell, the website is still active and still follows the same core principles it did in the early days, the CCI is used for entries, range bars are used to help trader's cut down on the noise, and the optional addition of Woodie's Pivot Points can be used as further confirmation of support and resistance. This is my take on his famous "Woodie's CCI" that has become standard on many charting packages through the years, including a TradingView sponsored version as one of the many stock indicators provided by TradingView. Woodie has updated his CCI through the years to include several very cool additions outside of the standard CCI. I will have to say, I am a bit biased, but I think this is hands down one of the best indicators I have ever used, and I am far too young to have been part of the original CCI Club. Being a daytrader primarily, this fits right in my timeframe wheel house. Woodie designed this indicator to work on a day-trading time scale and he frequently uses this to trade futures and commodity contracts on the 30 minute, often even down to the one minute timeframe. This makes it unique in that it is probably one of the only daytrading-designed indicators out there that I am aware of that was not a popular indicator, like the MACD or RSI, that was just adopted by daytraders.
The CCI was originally created by Donald Lambert in 1980. Over time, it has become an extremely popular house-hold indicator, like the Stochastics, RSI, or MACD. However, like the RSI and Stochastics, there are extensive debates on how the CCI is actually meant to be used. Some trade it like a reversal indicator, where values greater than 100 or less than -100 are considered overbought or oversold, respectively. Others trade it like a typical zero-line cross indicator, where once the value goes above or below the zero-line, a trade should be considered in that direction. Lastly, some treat it as strictly a momentum indicator, where values greater than 100 or less than -100 are seen as strong momentum moves and when these values are reached, a new strong trend is establishing in the direction of the move. The CCI itself is nothing fancy, it just visualizes the distance of the closing price away from a user-defined SMA value and plots it as a line. However, Woodie's CCI takes this simple concept and adds to it with an indicator with 5 pieces to it designed to help the trader enter into the highest probability setups. Bear with me, it initially looks super complicated, but I promise it is pretty straight-forward and a fun indicator to use.
1) The CCI Histogram. This is your standard CCI value that you would find on the normal CCI. Woodie's CCI uses a value of 14 for most trades and a value of 20 when the timeframe is equal to or greater than 30minutes. I personally use this as a 20-period CCI on all time frames, simply for the fact that the 20 SMA is a very popular moving average and I want to know what the crowd is doing. This is your coloured histogram with 4 colours. A gray colouring is for any bars above or below the zero line for 1-4 bars. A yellow bar is a "trend bar", where the long period CCI has been above/below the zero line for 5 consecutive bars, indicating that a trend in the current direction has been established. Blue bars above and red bars below are simply 6+n number of bars above or below the zero line confirming trend. These are used for the Zero-Line Reject Trade (explained below). The CCI Histogram has a matching long-period CCI line that is painted the same colour as the histogram, it is the same thing but is used just to outline the Histogram a bit better.
2) The CCI Turbo line. This is a sped-up 6 period CCI. This is to be used for the Zero-Line Reject trades, trendline breaks, and to identify shorter term overbought/oversold conditions against the main trend. This is coloured as the white line.
3) The Least Squares Moving Average Baseline (LSMA) Zero Line. You will notice that the Zero Line of the indicator is either green or red. This is based on when price is above or below the 25-period LSMA on the chart. The LSMA is a 25 period linear regression moving average and is one of the best moving averages out there because it is more immune to noise than a typical MA. Statistically, an LSMA is designed to find the line of best fit across the lookback periods and identify whether price is advancing, declining, or flat, without the whipsaw that other MAs can be privy to. The zero line of the indicator will turn green when the close candle is over the LSMA or red when it is below the LSMA. This is meant to be a confirmation tool only and the CCI Histogram and Turbo Histogram can cross this zero line without any corresponding change in the colour of the zero line on that immediate candle.
4) The +100 and -100 lines are used in two ways. First, they can be used by the CCI Histogram and CCI Turbo as a sort of minor price resistance and if the CCI values cannot get through these, it is considered weakness in that trade direction until they do so. You will notice that both of these lines are multi-coloured. They have been plotted with the ChopZone Indicator, another TradingView built-in indicator. The ChopZone is a trend identification tool that uses the slope and the direction of a 34-period EMA to identify when price is trending or range bound. While there are ~10 different colours, the main two a trader needs to pay attention to are the turquoise/cyan blue, which indicates price is in an uptrend, and dark red, which indicates price is in a downtrend based on the slope and direction of the 34 EMA. All other colours indicate "chop". These colours are used solely for the Zero-Line Reject and pattern trades discussed below. They are plotted both above and below so you can easily see the colouring no matter what side of the zero line the CCI is on.
5) The +200 and -200 lines are also used in two ways. First, they are considered overbought/oversold levels where if price exceeds these lines then it has moved an extreme amount away from the average and is likely to experience a pullback shortly. This is more useful for the CCI Histogram than the Turbo CCI, in all honesty. You will also notice that these are coloured either red, green, or yellow. This is the Sidewinder indicator portion. The documentation on this is extremely sparse, only pointing to a "relationship between the LSMA and the 34 EMA" (see here: tlc.thinkorswim.com). Since I am not a member of Woodie's CCI Club and never intend to be I took some liberty here and decided that the most likely relationship here was the slope of both moving averages. Therefore, the Sidewinder will be green when both the LSMA and the 34 EMA are rising, red when both are falling, and yellow when they are not in agreement with one another (i.e. one rising/flat while the other is flat/falling). I am a big fan of Dr. Alexander Elder as those who follow me know, so consider this like Woodie's version of the Elder Impulse System. I will fully admit that this version of the Sidewinder is a guess and may not represent the real Sidewinder indicator, but it is next to impossible to find any information on this, so I apologize, but my version does do something useful anyways. This is also to be used only with the Zero-Line Reject trades. They are plotted both above and below so you can easily see the colouring no matter what side of the zero line the CCI is on.
How to Trade It According to Woodie's CCI Club:
Now that I have all of my components and history out of the way, this is what you all care about. I will only provide a brief overview of the trades in this system, but there are quite a few more detailed descriptions listed in the Woodie's CCI Club pamphlet. I have had little success trading the "patterns" but they do exist and do work on occasion. I just prefer to trade with the flow of the markets rather than getting overly scalpy. If you are interested in these patterns, see the pamphlet here (www.trading-attitude.com), hop into the forums and see for yourself, or check out a couple of the YouTube videos.
1) Zero line cross. As simple as any other momentum oscillator out there. When the long period CCI crosses above or below the zero line open a trade in that direction. Extra confirmation can be had when the CCI Turbo has already broken the +100/-100 line "resistance or support". Trend traders may wish to wait until the yellow "trend confirmation bar" has been printed.
2) Zero Line Reject. This is when the CCI Turbo heads back down to the zero line and then bounces back in the same direction of the prevailing trend. These are fantastic continuation trades if you missed the initial entry either on the zero line cross or on the trend bar establishment. ZLR trades are only viable when you have the ChopZone indicator showing a trend (turquoise/cyan for uptrend, dark red for downtrend), the LSMA line is green for an uptrend or red for a downtrend, and the SideWinder is either green confirming the uptrend or red confirming the downtrend.
3) Hook From Extreme. This is the exact same as the Zero Line Reject trade, however, the CCI Turbo now goes to the +100/-100 line (whichever is opposite the currently established trend) and then hooks back into the established trend direction. Ideally the HFE trade needs to have the Long CCI Histogram above/below the corresponding 100 level and the CCI Turbo both breaks the 100 level on the trend side and when it does break it has increased ~20 points from the previous value (i.e. CCI Histogram = +150 with LSMA, CZ, and SW all matching up and trend bars printed on CCI Histogram, CCI Turbo went to -120 and bounced to +80 on last 2 bars, current bar closes with CCI Turbo closing at +110).
4) Trend Line Break. Either the CCI Turbo or CCI Histogram, whichever you prefer (I find the Turbo a bit more accurate since its a faster value) creates a series of higher highs/lows you can draw a trend line linking them. When the line breaks the trendline that is your signal to take a counter trade position. For example, if the CCI Turbo is making consistently higher lows and then breaks the trendline through the zero line, you can then go short. This is a good continuation trade.
5) The Tony Trade. Consider this like a combination zero line reject, trend line break, and weak zero line cross all in one. The idea is that the SW, CZ, and LSMA values are all established in one direction. The CCI Histogram should be in an established trend and then cross the zero line but never break the 100 level on the new side as long as it has not printed more than 9 bars on the new side. If the CCI Histogram prints 9 or less bars on the new side and then breaks the trendline and crosses back to the original trend side, that is your signal to take a reversal trade. This is best used in the Elder Triple Screen method (discussed in final section) as a failed dip or rip.
6) The GB100 Trade. This is a similar trade as the Tony Trade, however, the CCI Histogram can break the 100 level on the new side but has to have made less than 6 bars on the new side. A trendline break is not necessary here either, it is more of a "pop and drop" or "momentum failure" trade trying in the new direction.
7) The Famir Trade. This is a failed CCI Long Histogram ZLR trade and is quite complicated. I have never traded this but it is in the pamphlet. Essentially you have a typical ZLR reject (i.e. all components saying it is likely a long/short continuation trade), but the ZLR only stays around the 50 level, goes back to the trend side, fails there as well immediately after 1 bar and then rebreaks to the new side. This is important to be considered with the LSMA value matching the side of the trade, so if the Famir says to go long, you need the LSMA indicator to also say to go long.
8) The Vegas Trade. This is essentially a trend-reversal trade that takes into account the LSMA and a cup and handle formation on the CCI Long Histogram after it has reached an extreme value (+200/-200). You will see the CCI Histogram hit the extreme value, head towards the zero line, and then sort of round out back in the direction of the extreme price. The low point where it reversed back in the direction of the extreme can be considered support or resistance on the CCI and once the CCI Long Histogram breaks this level again, with LSMA confirmation, you can take a counter trend trade with a stop under/over the highest/lowest point of the last 2 bars as you want to be out quickly if you are wrong without much damage but can get a huge win if you are right and add later to the position once a new trade has formed.
9) The Ghost Trade. This is nothing more than a(n) (inverse) head and shoulders pattern created on the CCI. Draw a trend line connecting the head and shoulders and trade a reversal trade once the CCI Long Histogram breaks the trend line. Same deal as the Vegas Trade, stop over/under the most recent 2 bar high/low and add later if it is a winner but cut quickly if it is a loser.
Like I said, this is a complicated system and could quite literally take years to master if you wanted to go into the patterns and master them. I prefer to trade it in a much simpler format, using the Elder Triple Screen System. First, since I am a day trader, I look to use the 20 period Woodie's on the hourly and look at the CZ, SW, and LSMA values to make sure they all match the direction of the CCI Long Histogram (a trend establishment is not necessary here). It shows you the hourly trend as your "tide". I then drill down to the 15 minute time frame and use the Turbo CCI break in the opposite direction of the trend as my "wave" and to indicate when there is a dip or rip against the main trend. Lastly, I drill down to a 3 minute time frame and enter when the CCI Long Histogram turns back to match the main trend ("ripple") as long as the CCI Turbo has broken the 100 level in the matched direction.
Enjoy, and please read the pamphlet if you have any questions about the patterns as they are not how I use these and will not be able to answer those questions.

tunnel trading betaThe original author of the tunnel trading system: youtuber:Teacher Jin
This is a set of indicators system that trades completely based on the moving average. It belongs to the right trading. The idea is as follows:
(1) Basic trend (major trend)
When the short-term moving average is higher than the long-term moving average, it is an upward trend; otherwise, it is a downward trend.
The tentative short-term moving average is ema12, and the long-term moving average is ema169.
(2) The first type of buying point (or short point): trend establishment
Starting from the bar where the uptrend is established, the first outgoing bar is the first buying point. (Outgoing means that the closing price is higher than the opening price and higher than the high point of the previous bar)
Starting from the bar where the downtrend is established, the first bar to fall is the first shorting point. (Fall means that the closing price is lower than the opening price and lower than the low point of the previous bar)
(3) The second type of buying point (or short point): the buying point when pulling back (or the short point when rebounding)
The buying point at the time of pullback (callback) means that the general trend is up, but the small trend is down. You can buy when it is clear that the down trend is over.
Two concepts need to be defined here: "pullback (callback)" and "end of down trend". The definition of pullback is that when the general trend is rising, bar falls below the long-term moving average, and at this time the short-term moving average is still higher than the long-term moving average; The definition of the end of a down trend is that it is outgoing and ema12 is on the rise.
In the same way, we can know what is the "short point when rebounding":
The big trend is down, but the small trend is up. When it is clear that the rise is over, you can go short.
(4) Setting of Stop Loss and Take Profit
When going long:
Stop Loss Price: The low point of a bar before the buying point.
Stop-profit price: After the stop-loss price is determined, the profit-loss ratio is 3:1 to determine the stop-profit price. (The default value is 3, the user can modify it)
When shorting:
Stop Loss Price: The high point of a bar before the purchase point.
Stop-profit price: After the stop-loss price is determined, the profit-loss ratio is 3:1 to determine the stop-profit level. (The default value is 3, the user can modify it)
Chinese introduction:
隧道交易体系的原作者:油管金老师看盘室
这是一套完全根据均线进行交易的指标体系,属于右侧交易,思路如下:
(1) 基本趋势(大趋势)
短期均线高于长期均线时,是上涨趋势;反之,是下降趋势。
暂定短期均线为ema12,长期均线为ema169。
(2) 第一种买入点(或做空点):趋势确立
从上涨趋势确立的那根bar开始,第一个出头的bar,是第一买入点。(出头,是指收盘价高于开盘价,且高于前一根bar的高点)
从下降趋势确立的那根bar开始,第一个落尾的bar,是第一做空点。(落尾,是指收盘价低于开盘价,且低于前一根bar的低点)
(3) 第二种买入点(或做空点):拉回时的买入点(或反弹时的做空点)
拉回时(回调时)的买入点,是指大趋势是上涨,但小趋势是下跌,当明确下跌结束时,可以买入。
这里需要定义2个概念:“拉回(回调)”和“下跌结束”。拉回的定义是,大趋势是上涨时,bar跌破长期均线,此时短期均线仍高于长期均线;下跌结束的定义是,出头且ema12在上升。
同理可知什么是“反弹时的做空点”:
大趋势是下跌,但小趋势是上涨,当明确上涨结束时,可以做空。
(4) 止损位和止盈位的设置
做多时:
止损位:买入点前一根bar的低点。
止盈位:止损位确定后,按盈亏比3:1确定止盈位。(默认值为3,用户可以修改)
做空时:
止损位:买入点前一根bar的高点。
止盈位:止损位确定后,按盈亏比3:1确定止盈位。(默认值为3,用户可以修改)

MAFIA CANDLESMafia Candles is a Exhaustion bar count and candle count indicator, Using the Leledc Candles and 1-3 counting candle play gives you a pretty good idea where a so called "top" will be or a so called "bottom" will be!
In this example, getting the transparent round circles ( either lime or red ) would mean that the move will be a good size move!
EXAMPLE=1 You see a down trend and then the Mafia Candles Flashes a Green Dot on the forming new red candle. This is where in theory you might want to consider going long on the market!
EXAMPLE=2 If you see a RED $ symbol, after a uptrend, this means in theory, there might be room for a short play or room for a small pullback in the price!
THE CIRCLES(RED OR LIME COLORED) ARE INDICATING BIGGER MOVES!
THE $ SYMBOLS (RED OR LIME COLORED) ARE INDICATING SMALLER PULLBACKS OR SMALLER PUMPS IN PRICE!
RED IS CONSIDERED TO BE A SELL!
LIME COLOR IS CONSIDERED TO BE A BUY!
AS MUCH IS BASED OF THE 1-3 CANDLE COUNT AND THE LEDLEC CANDLE DEVIATION STRATEGY, LET ME EXPLAIN THE THEORY ON BOTH THE 1-3 CANDLE COUNT AND THE LELEDC STRATEGY I COMBINE TO BRING YOU THIS ADDITION OF THE INDICATOR....
LELEDC THEORY USAGE...
An Exhaustion Bar is a bar which signals
the exhaustion of the trend in the current direction. In other words an
exhaustion bar is “A bar of last seller” in case of a downtrend and “A bar of
last buyer”in case of an uptrend.
Having said that when a party cannot take the price further in their direction,naturally the other party comes in , takes charge and reverses the direction of the trend.
TO EASIER UNDERSTAND I GIVE YOU A EASY EXAMPLE OF WHAT AN LELEDC EXHAUSTION BAR IS...
1. A wide range bar ( a bar with
long body!!!).
2. A long wick at the bottom of
the bar and no or negligible wick at the top of the bar in case of “Bear exhaustion bar” and
a long wick at the top and no or
negligible wick at the bottom of the bar in case of
“Bull exhuation bar”!!!
3. Extreme volume and.....
4. Bar forming at a key support or resistance
area including a Round Number (RN) and Big Round Number ( BRN ).THE PSYCHOLOGY BEHIND THIS!!!
Now let's assume that we have a group
of people,say 100 people who decides to go for a casual running. After running for few KM's few of
them will say “I am exhausted. I cannot run further”. They will quit running.
After running further, another bunch of runners will say “I am exhausted. I can’t run
further” and they also will quit running.
This goes on and on and then there will be a stage where only few will be left in the running. Now a stage will come where the last person left in the running will say “I
am exhausted” and he stops running. That means no one is left now in the
running.This means all are exhausted in the running.
The same way an exhaustion bar works and if we can figure out that
exhaustion bar with all the tools available on hand, we will be in a big trade
for sure!!.The reason is an exhaustion bar is formed at exact tops and bottoms most of the times.In forex with wide variety of pairs available at the counter ,one can trade this technique to make lifetime gains.
NOW LET ME EXPLAIN THE 1-3 CANDLE CORRECTION COUNT THEORY WHICH IS USED TO GET THE SUM UP SIGNALS FROM THIS INDICATOR FROM ITS INPUT LEVELS!!!
1-3 CANDLES....
The 1-3 Candlestick pattern is basically like sequential, aka a candle counting system!
1-3 CANDLE COUNT means you count the number of bullish=green candles or the bearish=red candles!
3 BULL/GREEN CANDLES in a row, each closing its close higher than the previous one before it is the 1-3 candle top count idea!
lets say you get 3 red bear candles, each candle after the first closes its body below the previous red candle before it, then you see 3 red candles with each closing lower bodies lower than the previous candle, THATS A POSSIBLE SIGN OF BEARISH EXHAUSTION, AND YOU MIGHT HAVE SOME BULLS STEP IN TO TAKE THE PRICE UP AFTER THE IMMEDIATE DOWNFALL OF THOSE 3 RED CANDLES!!
PLEASE IF ANYONE HAS QUESTIONS OR NEEDS ANY FURTHER EXPLANATION, DONT HESISITATE TO MESSAGE ME! CHALRES KNIGHT IS THE ORIGINAL AUTHOR OF THE 1-3 CANDLE COUNT AND THE LELEDC EXHAUSTION BAR INDICATOR ON METE-TRADER! R.IP CHARLES F KNIGHT!!! WE LOVE YOU AND MISS YOU BROTHER!
CHARLES KNIGHT PASSED DOWN ALL OF HIS INDICATORS AND SCRIPTS IN ORIGINAL CODE TO MYSELF WHEN HE PASSED AWAY AND I WILL CONTINUE TO HONOR HIS MEMORY BY ENHANCING HIS ORIGINAL SOURCE CODED SCRIPTS TO ENHANCE THE LIFE FOR ALL TRADERS!
CHARLIE LOVED WHEN I WOULD PUT MY OWN SWING ON HIS INDICATORS! HE TAUGHT ME EVERYTHING I KNOW AND I KNOW ONE DAY I WILL SEE HIM AGAIN!
TRADE IN PARADISE CHARLIE!!!
THE BEST TRADER IN THE WORLD!!!

How to avoid repainting when NOT using security()Even when your code does not use security() calls, repainting dynamics still come into play in the realtime bar. Script coders and users must understand them and, if they choose to avoid repainting, need to know how to do so. This script demonstrates three methods to avoid repainting when NOT using the security() function.
Note that repainting dynamics when not using security() usually only come into play in the realtime bar, as historical data is fixed and thus cannot cause repainting, except in situations related to stock splits or dividend adjustments.
For those who don’t want to read
Configure your alerts to trigger “Once Per Bar Close” and you’re done.
For those who want to understand
Put this indicator on a 1 minute or seconds chart with a live symbol. As price changes you will see four of this script’s MAs (all except the two orange ones) move in the realtime bar. You are seeing repainting in action. When the current realtime bar closes and becomes a historical bar, the lines on the historical bars will no longer move, as the bar’s OHLC values are fixed. Note that you may need to refresh your chart to see the correct historical OHLC values, as exchange feeds sometimes produce very slight variations between the end values of the realtime bar and those of the same bar once it becomes a historical bar.
Some traders do not use signals generated by a script but simply want to avoid seeing the lines plotted by their scripts move during the realtime bar. They are concerned with repainting of the lines .
Other traders use their scripts to evaluate conditions, which they use to either plot markers on the chart, trigger alerts, or both. They may not care about the script’s plotted lines repainting, but do not want their markers to appear/disappear on the chart, nor their alerts to trigger for a condition that becomes true during the realtime bar but is no longer true once it closes. Those traders are more concerned with repainting of signals .
For each of the three methods shown in this script’s code, comments explain if its lines, markers and alerts will repaint or not. Through the Settings/Inputs you will be able to control plotting of lines and markers corresponding to each method, as well as experiment with the option, for method 2, of disabling only the lines plotting in the realtime bar while still allowing the markers and alerts to be generated.
An unavoidable fact is that non-repainting lines, markers or alerts are always late compared to repainting ones. The good news is that how late they are will in many cases be insignificant, so that the added reliability of the information they provide will largely offset the disadvantages of waiting.
Method 1 illustrates the usual way of going about things in a script. Its gray lines and markers will always repaint but repainting of the alerts the marker conditions generate can be avoided by configuring alerts to trigger “Once Per Bar Close”. Because this gray marker repaints, you will occasionally see it appear/disappear during the realtime bar when the gray MAs cross/un-cross.
Method 2 plots the same MAs as method 1, but in green. The difference is that it delays its marker condition by one bar to ensure it does not repaint. Its lines will normally repaint but its markers will not, as they pop up after the condition has been confirmed on the bar preceding the realtime bar. Its markers appear at the beginning of the realtime bar and will never disappear. When using this method alerts can be configured to trigger “Once Per Bar” so they fire the moment the marker appears on the chart at the beginning of the realtime bar. Note that the delay incurred between methods 1 and 2 is merely the instant between the close of a realtime bar and the beginning of the next one—a delay measured in milliseconds. Method 2 also allows its lines to be hidden in the realtime bar with the corresponding option in the script’s Settings/Inputs . This will be useful to those wishing to eliminate unreliable lines from the realtime bar. Commented lines in method 2 provide for a 2b option, which is to delay the calculation of the MAs rather than the cross condition. It has the obvious inconvenient of plotting delayed MAs, but may come in handy in some situations.
Method 3 is not the best solution when using MAs because it uses the open of bars rather than their close to calculate the MAs. While this provides a way of avoiding repainting, it is not ideal in the case of MA calcs but may come in handy in other cases. The orange lines and markers of method 3 will not repaint because the value of open cannot change in the realtime bar. Because its markers do not repaint, alerts may be configured using “Once Per Bar”.
Spend some time playing with the different options and looking at how this indicator’s lines plot and behave when you refresh you chart. We hope everything you need to understand and prevent repainting when not using security() is there.
Look first. Then leap.