Cold Brew Ranges🧭 Core Logic and Calculation
The fundamental logic for each range (OR and CR) is identical:
Time Definition: Each range is defined by a specific Start Time and a fixed 30-second duration. The timestamp function, using the "America/New_York" time zone, is used to calculate the exact start time in Unix milliseconds for the current day.
Example: t0200 = timestamp(TZ, yC, mC, dC, 2, 0, 0) sets the start time for the 02:00 OR to 2:00:00 AM NY time.
Range Data Collection: The indicator uses the request.security_lower_tf() function to collect the High (hArr) and Low (lArr) prices of all bars that fall within the defined 30-second window, using a user-specified, sub-chart-timeframe (openrangetime, defaulted to "1" second, "30S", or "5" minutes). This ensures high precision in capturing the exact high and low during the 30-second window.
High/Low Determination: It iteratively finds the absolute highest price (OR_high) and the absolute lowest price (OR_low) recorded by the bars during that 30-second window.
Range Locking: Once the current chart bar's time (lastTs) passes the 30-second End Time (tEnd), the High and Low are locked (OR_locked = true), meaning the range calculation is complete for the day.
Drawing: Upon locking, the range is drawn on the chart using line.new for the High, Low, and Equilibrium, and box.new for the shaded fill. The lines are extended to a subsequent time anchor point (e.g., the 02:00 OR is extended to 08:20, the 09:30 OR is extended to 16:00).
Equilibrium (EQ): This is calculated as the simple average (midpoint) of the High and Low of the range.
EQ=
2
OR_High+OR_Low
⏰ Defined Trading Ranges
The indicator defines and tracks the following specific 30-second ranges:
Range Name Type Start Time (NY) Line Extension End Time (NY) Common Market Context
02:00 OR Opening 02:00:00 08:20:00 Asian/European Market Overlap
08:20 OR Opening 08:20:00 16:00:00 Pre-New York Open
09:30 OR Opening 09:30:00 16:00:00 New York Stock Exchange Open (Most significant OR)
18:00 OR Opening 18:00:00 20:00:00 Futures Market Open (Sunday/Monday)
20:00 OR Opening 20:00:00 Next Day's session start Asian Session Start
15:50 CR Closing 15:50:00 20:00:00 New York Close Range
⚙️ Key User Inputs and Customization
The script offers extensive control over which ranges are displayed and how they are visualized:
Range Time & History
openrangetime: Sets the sub-timeframe (e.g., "1" for 1 second) used to calculate the precise High/Low of the 30-second range. Crucial for accuracy.
showHistory: A toggle to show the ranges from previous days (up to a histCap of 50 days).
Range Toggles and Styling
On/Off Toggles: Independent input.bool (e.g., OR_0200_on) to enable or disable the display of each individual range.
Colors & Width: Separate color and width inputs for the High/Low lines (hlC), the Equilibrium line (eqC), and the background fill (fillC) for each range.
Line Styles: Global inputs for the line styles of High/Low (lineStyleInput) and Equilibrium (eqLineStyleInput) lines (Solid, Dotted, or Dashed).
showFill: Global toggle to enable the shaded background box that highlights the area between the High and Low.
Extensions
The script calculates and plots extensions (multiples of the initial range) above the High and below the Low.
showExt: Toggles the visibility of the extension lines.
useRangeMultiples: If true, the step size for each extension level is equal to the initial range size:
Step=Range=OR_High−OR_Low
If false, the step size is a fixed value defined by stepPts (e.g., 60.0 points, which is a common value for NQ futures).
stepCnt: Determines how many extension levels (multiples) are drawn above and below the range (default is 10).
📈 Trading Strategy Implications
The Cold Brew Ranges indicator is a tool for session-based support and resistance and range breakout/reversal strategies.
Key Support/Resistance: The High and Low of these defined opening ranges often act as strong, predefined price levels. Traders look for price rejection off these boundaries or a breakout with conviction.
Equilibrium (Midpoint): The EQ often represents a fair value for that specific session's opening. Movements away from it are seen as opportunities, and a return to it is common.
Extensions: The range extensions serve as potential profit targets or stronger, layered support/resistance levels if the market trends aggressively after the opening range is set.
The core idea is that the activity in the first 30 seconds of a significant trading session (like the NYSE or a market session open) sets a bias and initial boundary for the trading period that follows.
Cerca negli script per "如何用wind搜索股票的发行价和份数"

RSI Profile [Kodexius]RSI Profile is an advanced technical indicator that turns the classic RSI into a distribution profile instead of a single oscillating line. Rather than only showing where the RSI is at the current bar, it displays where the RSI has spent most of its time or most of its volume over a user defined lookback period.
The script builds a histogram of RSI values between 0 and 100, splits that range into configurable bins, and then projects the result to the right side of the chart. This gives you a clear visual representation of the RSI structure, including the Point of Control (POC), the Value Area High (VAH), and the Value Area Low (VAL). The POC marks the RSI level with the highest activity, while VAH and VAL bracket the percentage based value area around it.
By combining standard RSI, a distribution profile, and value area logic, this tool lets you study RSI behavior statistically instead of only bar by bar. You can immediately see whether the current RSI reading is located inside the dominant zone, extended above it, or depressed below it, and whether the recent regime has been biased toward overbought, oversold, or neutral territory. This is particularly useful for swing traders, mean reversion systems, and anyone who wants to integrate RSI context into a more profile oriented workflow.
🔹 Features
1. RSI-Based Distribution Profile
-Builds a histogram of RSI values between 0 and 100.
-The RSI range is divided into a user-defined number of bins (e.g., 30 bins).
-Each bin represents a band of RSI values, such as 0–3.33, 3.33–6.66, ..., 96.66–100.
-For each bar in the lookback period, the script:
-Finds which bin the RSI value belongs to
Adds either:
-1.0 → if using time/frequency
-volume → if using volume-weighted RSI distribution
This creates a clear profile of where RSI has been concentrated over the chosen lookback window.
2. Time / Volume Weighting Mode
Under Profile Settings, you can choose:
-Weight by Volume = false
→ Profile is built using time spent at each RSI level (frequency).
-Weight by Volume = true
→ Profile is built using volume traded at each RSI level.
This flexibility allows you to decide whether you want:
-A pure momentum structure (time spent at each RSI)
-Or a participation-weighted structure (where higher-volume zones are emphasized)
3. Configurable Lookback & Resolution
-Profile Lookback: number of historical bars to analyze.
-Number of Bins: controls the resolution of the histogram:
Fewer bins → smoother, fewer gaps
More bins → more detail, but potentially more visual sparsity
-Profile Width (Bars): defines how wide the histogram extends into the future (visually), converted into time using average bar duration.
This provides a balance between performance, clarity, and visual density.
4. Value Area, POC, VAH, VAL
The script computes:
-POC (Point of Control)
→ The RSI bin with the highest total value (time or volume).
-Value Area (VA)
→ The range of RSI bins that contain a user-specified percentage of total activity (e.g., 70%).
-VAH & VAL
→ Upper and lower RSI boundaries of this Value Area.
These are then drawn as horizontal lines and labeled:
-POC line and label
-VAH line and label
-VAL line and label
This gives you a profile-style view similar to classical volume profile, but entirely on the RSI axis.
5. Color Coding & Visual Design
The histogram bars (boxes) are colored using a smart scheme:
-Below 30 RSI → Oversold zone, uses the Oversold Color (default: green).
-Above 70 RSI → Overbought zone, uses the Overbought Color (default: red).
-Between 30 and 70 RSI → Neutral zone, uses a gradient between:
A soft blue at lower mid levels
A soft orange at higher mid levels
Additional styling:
-POC bin is highlighted in bright yellow.
-Bins inside the Value Area → lower transparency (more solid).
-Bins outside the Value Area → higher transparency (faded).
This makes it easy to visually distinguish:
-Core RSI activity (VA)
-Extremes (oversold/overbought)
-The single dominant zone (POC)
🔹 Calculations
This section summarizes the core logic behind the script and highlights the main building blocks that power the profile.
1. Profile Structure and Bin Initialization
A custom Profile type groups together configuration, bins and drawing objects. During initialization, the script splits the 0 to 100 RSI range into evenly spaced bins, each represented by a Bin record:
method initBins(Profile p) =>
p.bins := array.new()
float step = 100.0 / p.binCount
for i = 0 to p.binCount - 1
float low = i * step
float high = (i + 1) * step
p.bins.push(Bin.new(low, high, 0.0, box(na)))
2. Filling the Profile Over the Lookback Window
On the last bar, the script clears previous drawings and walks backward through the selected lookback window. For each historical bar, it reads the RSI and volume series and feeds them into the profile:
if barstate.islast
myProfile.reset()
int start = math.max(0, bar_index - lookback)
int end = bar_index
for i = 0 to (end - start)
float r = rsi
float v = volume
if not na(r)
myProfile.add(r, v)
The add method converts each RSI value into a bin index and accumulates either a frequency count or the bar volume, depending on the chosen mode:
method add(Profile p, float rsiValue, float volumeValue) =>
int idx = int(rsiValue / (100.0 / p.binCount))
if idx >= p.binCount
idx := p.binCount - 1
if idx < 0
idx := 0
Bin targetBin = p.bins.get(idx)
float addedValue = p.useVolume ? volumeValue : 1.0
targetBin.value += addedValue
3. Finding POC and Building the Value Area
Inside the draw method, the script first scans all bins to determine the maximum value and the total sum. The bin with the highest value becomes the POC. The value area is then constructed by expanding from that center bin until the desired percentage of total activity is covered:
for in p.bins
totalVal += b.value
if b.value > maxVal
maxVal := b.value
pocIdx := i
float vaTarget = totalVal * (p.vaPercent / 100.0)
float currentVaVol = maxVal
int upIdx = pocIdx
int downIdx = pocIdx
while currentVaVol < vaTarget
float upVol = (upIdx < p.binCount - 1) ? p.bins.get(upIdx + 1).value : 0.0
float downVol = (downIdx > 0) ? p.bins.get(downIdx - 1).value : 0.0
if upVol == 0 and downVol == 0
break
if upVol >= downVol
upIdx += 1
currentVaVol += upVol
else
downIdx -= 1
currentVaVol += downVol

Prime-Time × Vortex (3/6/9) — Ace (clean v3)1️⃣ Prime-Time Index (PT)
A bar becomes Prime-Time when the count satisfies the formula:
4·n − 3 is a perfect square
This generates the sequence:
1, 3, 7, 13, 21, 31, 43, 57, 73, 91, …
These are time windows where price is more likely to form:
Shifts in market structure
Impulses
Reversals
Liquidity expansions
These PT bars are drawn as small circles above the candle.
If labels are enabled, the counter value (n) is also shown.
2️⃣ Vortex 3/6/9 Digital-Root Timing
Every bar also has a digital root, calculated from the counter:
If n → digitalRoot(n) = 3, 6, or 9,
the bar is considered a Vortex bar.
These moments often align with:
Swing highs / swing lows
Micro shifts
Mini-reversals
Minor liquidity grabs
When a Prime-Time bar is also a 3/6/9 bar → high-probability timing.
These bars are highlighted in green by default.
3️⃣ Filters & Display
You can customize:
Anchor time → when counting begins
Reset daily → restart counter each new trading day
Show only 3/6/9 → hides normal PT hits
Label offset → distance above the candle
Color themes
This makes the indicator usable on:
1Min
5Min
15Min
1H
Any timeframe you want
4️⃣ How To Apply It in Trading
Use it as a time confluence tool, not a signal generator.
✔ Best ways to use:
Look for MSS, sweeps, OB retests, FVG reactions when
they occur on or near a Prime-Time or 3/6/9 bar
Expect volatility increases after PT bars
Use 3/6/9 hits to anticipate internal turning points
Combine with:
Session High/Low
Killzones (London, NYO, PM)
Purge Protocol
MMXM Execution
✔ Example:
If price sweeps a level and prints a 3/6/9 vortex bar inside a PT window →
you have a very strong timing alignment for reversal.
5️⃣ Simple Summary
Feature Meaning
Prime-Time Hit (PT) Major time window where price often shifts
3/6/9 Vortex Bar Micro-timing for internal swings
PT + 3/6/9 together High-probability timing for entries
Reset Daily Perfect for intraday models like NYO & London
Anchor Time Defines the entire cycle structure

Volatility Signal-to-Noise Ratio🙏🏻 this is VSNR: the most effective and simple volatility regime detector & automatic volatility threshold scaler that somehow no1 ever talks about.
This is simply an inverse of the coefficient of variation of absolute returns, but properly constructed taking into account temporal information, and made online via recursive math with algocomplexity O(1) both in expanding and moving windows modes.
How do the available alternatives differ (while some’re just worse)?
Mainstream quant stat tests like Durbin-Watson, Dickey-Fuller etc: default implementations are ALL not time aware. They measure different kinds of regime, which is less (if at all) relevant for actual trading context. Mix of different math, high algocomplexity.
The closest one is MMI by financialhacker, but his approach is also not time aware, and has a higher algocomplexity anyways. Best alternative to mine, but pls modify it to use a time-weighted median.
Fractal dimension & its derivatives by John Ehlers: again not time aware, very low info gain, relies on bar sizes (high and lows), which don’t always exist unlike changes between datapoints. But it’s a geometric tool in essence, so this is fundamental. Let it watch your back if you already use it.
Hurst exponent: much higher algocomplexity, mix of parametric and non-parametric math inside. An invention, not a math entity. Again, not time aware. Also measures different kinds of regime.
How to set it up:
Given my other tools, I choose length so that it will match the amount of data that your trading method or study uses multiplied by ~ 4-5. E.g if you use some kind of bands to trade volatility and you calculate them over moving window 64, put VSNR on 256.
However it depends mathematically on many things, so for your methods you may instead need multipliers of 1 or ~ 16.
Additionally if you wanna use all data to estimate SNR, put 0 into length input.
How to use for regime detection:
First we define:
MR bias: mean reversion bias meaning volatility shorts would work better, fading levels would work better
Momo bias: momentum bias meaning volatility longs would work better, trading breakouts of levels would work better.
The study plots 3 horizontal thresholds for VSNR, just check its location:
Above upper level: significant Momo bias
Above 1 : Momo bias
Below 1 : MR bias
Below lower level: significant MR bias
Take a look at the screenshots, 2 completely different volatility regimes are spotted by VSNR, while an ADF does not show different regime:
^^ CBOT:ZN1!
^^ INDEX:BTCUSD
How to use as automatic volatility threshold scaler
Copy the code from the script, and use VSNR as a multiplier for your volatility threshold.
E.g you use a regression channel and fade/push upper and lower thresholds which are RMSEs multiples. Inside the code, multiply RMSE by VSNR, now you’re adaptive.
^^ The same logic as when MM bots widen spreads with vola goes wild.
How it works:
Returns follow Laplace distro -> logically abs returns follow exponential distro , cuz laplace = double exponential.
Exponential distro has a natural coefficient of variation = 1 -> signal to noise ratio defined as mean/stdev = 1 as well. The same can be said for Student t distro with parameter v = 4. So 1 is our main threshold.
We can add additional thresholds by discovering SNRs of Student t with v = 3 and v = 5 (+- 1 from baseline v = 4). These have lighter & heavier tails each favoring mean reversion or momentum more. I computed the SNR values you see in the code with mpmath python module, with precision 256 decimals, so you can trust it I put it on my momma.
Then I use exponential smoothing with properly defined alphas (one matches cumulative WMA and another minimizes error with WMA in moving window mode) to estimate SNR of abs returns.
…
Lightweight huh?
∞
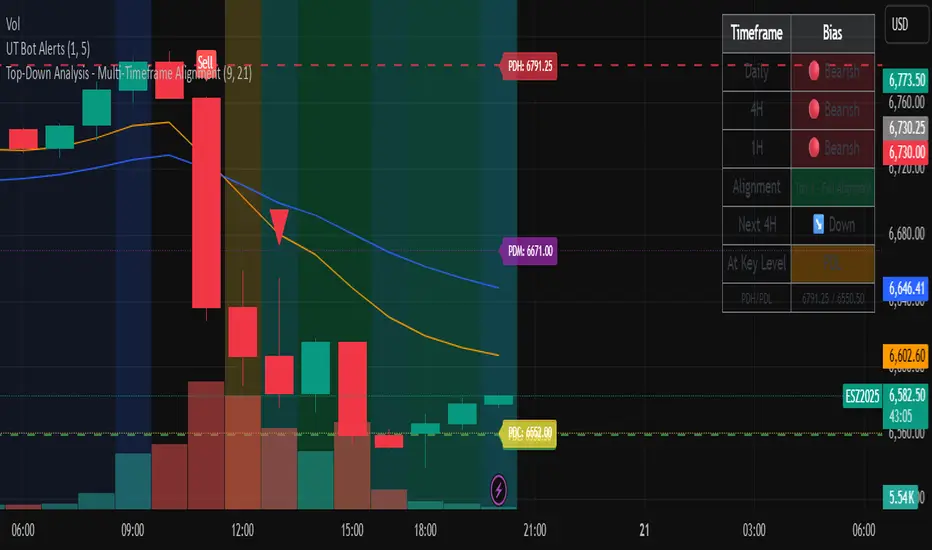
Top-Down Analysis - Multi-Timeframe AlignmentThis indicator implements a Top-Down Multi-Timeframe Trading Analysis System. Here's what it does:
Core Functionality
1. Multi-Timeframe Bias Detection
Monitors three timeframes: Daily, 4-Hour, and 1-Hour
Determines if each timeframe is bullish, bearish, or neutral based on two EMAs (9 and 21 period by default)
A timeframe is bullish when: Fast EMA > Slow EMA AND price is above Fast EMA
A timeframe is bearish when: Fast EMA < Slow EMA AND price is below Fast EMA
2. Alignment Tier System
Tier 1 (Full Alignment): All three timeframes agree (Daily = 4H = 1H direction)
Tier 2 (Partial Alignment): Daily and 1H agree, but 4H differs
No Alignment: Timeframes disagree
3. Previous Day Support & Resistance Levels
Automatically plots key levels from the previous day:
Previous Day High (PDH) - resistance
Previous Day Low (PDL) - support
Previous Day Close (PDC)
Previous Day Midpoint (PDM)
4. Execution Zone (15-Minute Window)
Highlights the first 15 minutes after each new 4H candle opens
This is the optimal entry window when alignment conditions are met
5. Pattern Recognition
Detects trading setups:
Double tops/bottoms
Long wicks at support/resistance
Bullish/bearish closes aligned with bias
6. Trade Signals
Generates entry signals when:
There's Tier 1 or Tier 2 alignment
Price is in the 15-minute execution zone
A valid pattern forms (double top/bottom or wick rejection)
7. Visual Dashboard
Shows a real-time table with:
Each timeframe's current bias
Alignment status
Next 4H prediction
Whether price is at a key support/resistance level
Trading Strategy
The indicator helps traders follow the principle of "trade with the higher timeframe trend" by only taking trades when multiple timeframes agree, focusing entries during specific windows, and respecting previous day's key price levels as potential reaction zones.
Forex Session TrackerForex Session Tracker - Professional Trading Session Indicator
The Forex Session Tracker is a comprehensive and visually intuitive indicator designed specifically for forex traders who need precise tracking of major global trading sessions. This powerful tool helps traders identify active market sessions, monitor session-specific price ranges, and capitalize on volatility patterns unique to each trading period.
Understanding when major financial centers are active is crucial for forex trading success. This indicator provides real-time visualization of the Tokyo, London, New York, and Sydney trading sessions, allowing traders to align their strategies with peak liquidity periods and avoid low-volatility trading windows.
---
Key Features
📊 Four Major Global Trading Sessions
The indicator tracks all four primary forex trading sessions with precision:
- Tokyo Session (Asian Market) - Captures the Asian trading hours, ideal for JPY, AUD, and NZD pairs
- London Session (European Market) - Monitors the most liquid trading period, perfect for EUR, GBP pairs
- New York Session (American Market) - Tracks US market hours, essential for USD-based currency pairs
- Sydney Session (Pacific Market) - Identifies the opening of the trading week and AUD/NZD activity
Each session is fully customizable with individual color schemes, making it easy to distinguish between different market periods at a glance.
🎯 Session Range Visualization
For each active trading session, the indicator automatically:
- Draws rectangular boxes that highlight the session's time period
- Tracks and displays session HIGH and LOW price levels in real-time
- Creates horizontal lines at session extremes for easy reference
- Positions session labels at the center of each trading period
- Updates dynamically as new highs or lows are formed within the session
This visual approach helps traders quickly identify:
- Session breakout opportunities
- Support and resistance zones formed during specific sessions
- Range-bound vs. trending session behavior
- Key price levels that institutional traders are watching
📱 Live Information Dashboard
A sleek, professional information panel displays:
- Real-time session status - Instantly see which sessions are currently active
- Color-coded indicators - Green dots for active sessions, gray for closed sessions
- Timezone information - Confirms your current timezone settings
- Customizable positioning - Place the dashboard anywhere on your chart (Top Left, Top Right, Bottom Left, Bottom Right)
- Adjustable size - Choose from Tiny, Small, Normal, or Large text sizes for optimal visibility
The dashboard provides at-a-glance awareness of market conditions without cluttering your chart analysis.
⚙️ Extensive Customization Options
Every aspect of the indicator can be tailored to your trading preferences:
Session-Specific Controls:
- Enable/disable individual sessions
- Customize colors for each trading period
- Adjust session times to match your broker's server time
- Toggle background highlighting on/off
- Show/hide session high/low lines independently
General Settings:
- UTC Offset Control - Adjust timezone from UTC-12 to UTC+14
- Exchange Timezone Option - Automatically use your chart's exchange timezone
- Background Transparency - Fine-tune the opacity of session highlighting (0-100%)
- Session Labels - Show or hide session name labels
- Information Panel - Toggle the live status dashboard on/off
Style Settings:
- Turn session backgrounds ON/OFF directly from the Style tab
- Maintain clean charts while keeping all analytical features active
🔔 Built-in Alert System
Stay informed about session openings with customizable alerts:
- Tokyo Session Started
- London Session Started
- New York Session Started
- Sydney Session Started
Set up notifications to never miss important market opening periods, even when you're away from your charts.
---
How to Use This Indicator
For Day Traders:
1. Identify High-Volatility Periods - Focus your trading during London and New York session overlaps for maximum liquidity
2. Monitor Session Breakouts - Watch for price breaks above/below session highs and lows
3. Avoid Low-Volume Periods - Recognize when major sessions are closed to avoid false signals
For Swing Traders:
1. Mark Key Levels - Use session highs and lows as support/resistance zones
2. Track Multi-Session Patterns - Observe how price behaves across different trading sessions
3. Plan Entry/Exit Points - Time your trades around session openings for better execution
For Currency-Specific Traders:
1. JPY Pairs - Focus on Tokyo session movements
2. EUR/GBP Pairs - Monitor London session activity
3. USD Pairs - Track New York session volatility
4. AUD/NZD Pairs - Watch Sydney and Tokyo sessions
---
Technical Specifications
- Pine Script Version: 5
- Overlay Indicator: Yes (displays directly on price chart)
- Maximum Bars Back: 500
- Drawing Objects: Up to 500 lines, boxes, and labels
- Performance: Optimized for real-time data processing
- Compatibility: Works on all timeframes (recommended: 5m to 1H for session tracking)
---
Installation & Setup
1. Add to Chart - Click "Add to Chart" after copying the script to Pine Editor
2. Configure Timezone - Set your UTC offset or enable "Use Exchange Timezone"
3. Customize Colors - Choose your preferred color scheme for each session
4. Adjust Display - Enable/disable features based on your trading style
5. Set Alerts - Create alert notifications for session starts
---
Best Practices
✅ Combine with Price Action - Use session ranges alongside candlestick patterns for confirmation
✅ Watch Session Overlaps - The London-New York overlap (1300-1600 UTC) typically shows highest volatility
✅ Respect Session Highs/Lows - These levels often act as intraday support and resistance
✅ Adjust for Your Broker - Verify session times match your broker's server clock
✅ Use Multiple Timeframes - View sessions on both lower (15m) and higher (1H) timeframes for context
---
Why Choose Forex Session Tracker Pro?
✨ Professional Grade Tool - Built with clean, efficient code following TradingView best practices
✨ Beginner Friendly - Intuitive design with clear visual cues
✨ Highly Customizable - Adapt every feature to match your trading style
✨ Performance Optimized - Lightweight code that won't slow down your charts
✨ Actively Maintained - Regular updates and improvements
✨ No Repainting - All visual elements are fixed once the session completes
---
Support & Updates
This indicator is designed to provide reliable, accurate session tracking for forex traders of all experience levels. Whether you're a scalper looking for high-volatility windows or a position trader marking key institutional levels, the Forex Session Tracker Pro delivers the insights you need to make informed trading decisions.
Happy Trading! 📈
---
Disclaimer
This indicator is a tool for technical analysis and should be used as part of a comprehensive trading strategy. Past performance does not guarantee future results. Always practice proper risk management and never risk more than you can afford to lose. Trading forex carries a high level of risk and may not be suitable for all investors.

[Statistics] killzone SFPSFP Statistics (ICT Sessions)
This indicator automatically finds and draws the high and low of the Asia, London, and New York trading sessions. It then hunts for Swing Failure Patterns (SFPs) that sweep these key session levels.
The main purpose of this script is to gather statistics on when these high-probability SFPs occur, allowing you to map out and identify the times of day when they are most frequent.
How to Use This Indicator
Set Your SFP Timeframe: In the settings, choose the timeframe you want to hunt for SFPs on (e.g., 1H, 15m). Important: You must also set your main chart to this exact same timeframe for the statistics to be collected correctly.
Define Your Sessions: Go to the "Session Definitions" tab.
Set the Global Timezone to your preferred trading timezone (e.g., "America/New_York"). This controls all session times and table times.
Adjust the start and end times for Asia, London, and NY AM sessions.
You can turn off sessions you don't want to track (like NY Lunch or NY PM).
You can also change the colors and text style for the session boxes here.
Set Confirmation Bars: In "SFP Engine Settings," the "Confirmation Bars" (default is 2) defines how many bars must close after the SFP bar without invalidating the level. An SFP is only "confirmed" and drawn after this period.
0 = Confirms immediately on the SFP candle's close.
2 = Confirms 2 bars after the SFP candle's close.
Read the Statistics: The "Custom SFP Statistics" table will appear on your chart. This table logs every confirmed SFP and tells you:
Which time of day they happen most.
How many were Bearish (swept a high) vs. Bullish (swept a low).
It's set by default to show the "Top 20" most frequent times, sorted chronologically.
Filter Your Chart (Optional): If your chart feels cluttered, go to "Visual Time Filter" and turn it ON.
Set a time window (e.g., "09:30-11:00").
The indicator will now only draw SFP signals that occurred within that specific time window. This is perfect for focusing on a single killzone.
How to Set Up Alerts
You can set up server-side alerts to be notified every time a new SFP is confirmed.
Check the "Enable SFP Alerts" box at the top of the indicator's settings.
Click the "Alert" button (alarm clock icon) on the TradingView toolbar.
In the "Condition" dropdown, select "SFP Statistics (ICT Sessions)".
In the second dropdown, choose "Any alert() function call".
Most Important Step: In the "Message" box, delete any default text and type in this exact placeholder:
{{alert_message}}
Set the trigger to "Once Per Bar Close".
Click "Create".
How Alerts Work (Triggers & Filtering)
Trigger: Alerts are tied to the confirmed signal. An alert will only fire after your "Confirmation Bars" have passed and the SFP is locked in. This prevents you from getting alerts on fake-outs.
Alert Filtering: The alerts are linked to the "Visual Time Filter". If you turn on the Visual Time Filter (e.g., to 09:30-11:00), you will only receive alerts for SFPs that are confirmed within that time window. If an SFP happens at 14:00, the script will ignore it, it will not be drawn, and it will not send you an alert. This allows you to get alerts only for the session you are actively trading.
Note: This is a first draft of this indicator. I will continue to work on it and improve it over time, as it may still contain small bugs.
Acknowledgements:
A big thank you to TFO (tradeforopp). The session detection logic and the visual style for the session boxes were adapted from his excellent "ICT Killzones & Pivots " indicator.

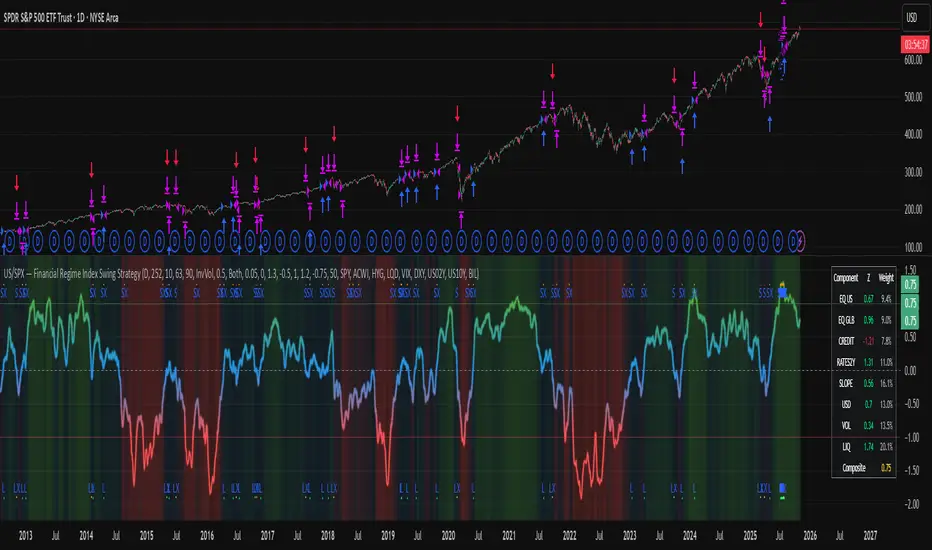
US/SPY- Financial Regime Index Swing Strategy Credits: concept inspired by EdgeTools Bloomberg Financial Conditions Index (Proxy)
Improvements: eight component basket, inverse volatility weights, winsorization option( statistical technique used to limit the influence of outliers in a dataset by replacing extreme values with less extreme ones, rather than removing them entirely), slope and price gates, exit guards, table and gradients.
Summary in one paragraph
A macro regime swing strategy for index ETFs, futures, FX majors, and large cap equities on daily calculation with optional lower time execution. It acts only when a composite Financial Conditions proxy plus slope and an optional price filter align. Originality comes from an eight component macro basket with inverse volatility weights and winsorized return z scores that produce a portable yardstick.
Scope and intent
Markets: SPY and peers, ES futures, ACWI, liquid FX majors, BTC, large cap equities.
Timeframes: calculation daily by default, trade on any chart.
Default demo: SPY on Daily.
Purpose: convert broad financial conditions into clear swing bias and exits.
Originality and usefulness
Unique fusion: return z scores for eight liquid proxies with inverse volatility weighting and optional winsorization, then slope and price gates.
Failure mode addressed: false starts in chop and early shorts during easy liquidity.
Testability: all knobs are inputs and the table shows components and weights.
Portable yardstick: z scores center at zero so thresholds transfer across symbols.
Method overview in plain language
Base measures
Return basis: natural log return over a configurable window, standardized to a z score. Winsorization optional to cap extremes.
Components
EQ US and EQ GLB measure equity tone.
CREDIT uses LQD over HYG. Higher credit quality outperformance is risk off so sign is flipped after z score.
RATES2Y uses two year yield, sign flipped.
SLOPE uses ten minus two year yield spread.
USD uses DXY, sign flipped.
VOL uses VIX, sign flipped.
LIQ uses BIL over SPY, sign flipped.
Each component is smoothed by the composite EMA.
Fusion rule
Weighted sum where weights are equal or inverse volatility with exponent gamma, normalized to percent so they sum to one.
Signal rule
Long when composite crosses up the long threshold and its slope is positive and price is above the SMA filter, or when composite is above the configured always long floor.
Short when composite crosses down the short threshold and its slope is negative and price is below the SMA filter.
Long exit on cross down of the long exit line or on a fresh short signal.
Short exit on cross up of the short exit line or on a fresh long signal, or when composite falls below the force short exit guard.
What you will see on the chart
Markers on suggestion bars: L for long, S for short, LX and SX for exits.
Reference lines at zero and soft regime bands at plus one and minus one.
Optional background gradient by regime intensity.
Compact table with component z, weight percent, and composite readout.
Table fields and quick reading guide
Component: EQ US, EQ GLB, CREDIT, RATES2Y, SLOPE, USD, VOL, LIQ.
Z: current standardized value, green for positive risk tone where applicable.
Weight: contribution percent after normalization.
Composite: current index value.
Reading tip: a broadly green Z column with slope positive often precedes better long context.
Inputs with guidance
Setup
Calc timeframe: default Daily. Leave blank to inherit chart.
Lookback: 50 to 1500. Larger length stabilizes regimes and delays turns.
EMA smoothing: 1 to 200. Higher smooths noise and delays signals.
Normalization
Winsorize z at ±3: caps extremes to reduce one off shocks.
Return window for equities: 5 to 260. Shorter reacts faster.
Weighting
Weight lookback: 20 to 520.
Weight mode: Equal or InvVol.
InvVol exponent gamma: 0.1 to 3. Higher compresses noisy components more.
Signals
Trade side: Long Short or Both.
Entry threshold long and short: portable z thresholds.
Exit line long and short: soft exits that give back less.
Slope lookback bars: 1 to 20.
Always long floor bfci ≥ X: macro easy mode keep long.
Force short exit when bfci < Y: macro stress guard.
Confirm
Use price trend filter and Price SMA length.
View
Glow line and Show component table.
Symbols
SPY ACWI HYG LQD VIX DXY US02Y US10Y BIL are defaults and can be changed.
Realism and responsible publication
No performance claims. Past is not future.
Shapes can move intrabar and settle on close.
Execution is on standard candles only.
Honest limitations and failure modes
Major economic releases and illiquid sessions can break assumptions.
Very quiet regimes reduce contrast. Use longer windows or higher thresholds.
Component proxies are ETFs and indexes and cannot match a proprietary FCI exactly.
Strategy notice
Orders are simulated on standard candles. All security calls use lookahead off. Nonstandard chart types are not supported for strategies.
Entries and exits
Long rule: bfci cross above long threshold with positive slope and optional price filter OR bfci above the always long floor.
Short rule: bfci cross below short threshold with negative slope and optional price filter.
Exit rules: long exit on bfci cross below long exit or on a short signal. Short exit on bfci cross above short exit or on a long signal or on force close guard.
Position sizing
Percent of equity by default. Keep target risk per trade low. One percent is a sensible starting point. For this example we used 3% of the total capital
Commisions
We used a 0.05% comission and 5 tick slippage
Legal
Education and research only. Not investment advice. Test in simulation first. Use realistic costs.
Cora Combined Suite v1 [JopAlgo]Cora Combined Suite v1 (CCSV1)
This is an 2 in 1 indicator (Overlay & Oscillator) the Cora Combined Suite v1 .
CCSV1 combines a price-pane Overlay for structure/trend with a compact Oscillator for timing/pressure. It’s designed to be clear, beginner-friendly, and largely automatic: you pick a profile (Scalp / Intraday / Swing), choose whether to run as Overlay or Oscillator, and CCSV1 tunes itself in the background.
What’s inside — at a glance
1) Overlay (price pane)
CoRa Wave: a smooth trend line based on a compound-ratio WMA (CRWMA).
Green when the slope rises (bull bias), Red when it falls (bear bias).
Asymmetric ATR Cloud around the CoRa Wave
Width expands more up when buyer pressure dominates and more down when seller pressure dominates.
Fill is intentionally light, so candlesticks remain readable.
Chop Guard (Range-Lock Gate)
When the cloud stays very narrow versus ATR (classic “dead water”), pullback alerts are muted to avoid noise.
Visuals don’t change—only the alerting logic goes quiet.
Typical Overlay reads
Trend: Follow the CoRa color; green favors long setups, red favors shorts.
Value: Pullbacks into/through the cloud in trend direction are higher-quality than chasing breaks far outside it.
Dominance: A visibly asymmetric cloud hints which side is funding the move (buyers vs sellers).
2) Oscillator (subpane or inline preview)
Stretch-Z (columns): how far price is from the CoRa mean (mean-reversion context), clipped to ±clip.
Near 0 = equilibrium; > +2 / < −2 = stretched/extended.
Slope-Z (line): z-score of CoRa’s slope (momentum of the trend line).
Crossing 0 upward = potential bullish impulse; downward = potential bearish impulse.
VPO (stepline): a normalized Volume-Pressure read (positive = buyers funding, negative = sellers).
Rendered as a clean stepline to emphasize state changes.
Event Bands ±2 (subpane): thin reference lines to spot extension/exhaustion zones fast.
Floor/Ceiling lines (optional): quiet boundaries so the panel doesn’t feel “bottomless.”
Inline vs Subpane
Inline (overlay): the oscillator auto-anchors and scales beneath price, so it never crushes the price scale.
Subpane (raw): move to a new pane for the classic ±clip view (with ±2 bands). Recommended for systematic use.
Why traders like it
Two in one: Structure on the chart, timing in the panel—built to complement each other.
Retail-first automation: Choose Scalp / Intraday / Swing and let CCSV1 auto-tune lengths, clips, and pressure windows.
Robust statistics: On fast, spiky markets/timeframes, it prefers outlier-resistant math automatically for steadier signals.
Optional HTF gate: You can require higher-timeframe agreement for oscillator alerts without changing visuals.
Quick start (simple playbook)
Run As
Overlay for structure: assess trend direction, where value is (the cloud), and whether chop guard is active.
Oscillator for timing: move to a subpane to see Stretch-Z, Slope-Z, VPO, and ±2 bands clearly.
Profile
Scalp (1–5m), Intraday (15–60m), or Swing (4H–1D). CCSV1 adjusts length/clip/pressure windows accordingly.
Overlay entries
Trade with CoRa color.
Prefer pullbacks into/through the cloud (trend direction).
If chop guard is active, wait; let the market “breathe” before engaging.
Oscillator timing
Look for Funded Flips: Slope-Z crossing 0 in the direction of VPO (i.e., momentum + funded pressure).
Use ±2 bands to manage risk: stretched conditions can stall or revert—better to scale or wait for a clean reset.
Optional HTF gate
Enable to green-light only those oscillator alerts that align with your chosen higher timeframe.
What each signal means (plain language)
CoRa turns green/red (Overlay): trend bias shift on your chart.
Cloud width tilts asymmetrically: one side (buyers/sellers) is dominating; extensions on that side are more likely.
Stretch-Z near 0: fair value around CoRa; pullback timing zone.
Stretch-Z > +2 / < −2: extended; watch for slowing momentum or scale decisions.
Slope-Z cross up/down: new impulse starting; combine with VPO sign to avoid unfunded crosses.
VPO positive/negative: net buying/selling pressure funding the move.
Alerts included
Overlay
Pullback Long OK
Pullback Short OK
Oscillator
Funded Flip Up / Funded Flip Down (Slope-Z crosses 0 with VPO agreement)
Pullback Long Ready / Pullback Short Ready (near equilibrium with aligned momentum and pressure)
Exhaustion Risk (Long/Short) (Stretch-Z beyond ±2 with weakening momentum or pressure)
Tip: Keep chart alerts concise and use strategy rules (TP/SL/filters) in your trade plan.
Best practices
One glance workflow
Read Overlay for direction + value.
Use Oscillator for trigger + confirmation.
Pairing
Combine with S/R or your preferred execution framework (e.g., your JopAlgo setups).
The suite is neutral: it won’t force trades; it highlights context and quality.
Markets
Works on crypto, indices, FX, and commodities.
Where real volume is available, VPO is strongest; on synthetic volume, treat VPO as a soft filter.
Timeframes
Use the Profile preset closest to your style; feel free to fine-tune later.
For multi-TF trading, enable the HTF gate on the oscillator alerts only.
Inputs you’ll actually use (the rest can stay on Auto)
Run As: Overlay or Oscillator.
Profile: Scalp / Intraday / Swing.
Oscillator Render: “Subpane (raw)” for a classic panel; “Inline (overlay)” only for a quick preview.
HTF gate (optional): require higher-timeframe Slope-Z agreement for oscillator alerts.
Everything else ships with sensible defaults and auto-logic.
Limitations & tips
Not a strategy: CCSV1 is a decision support tool; you still need your entry/exit rules and risk management.
Non-repainting design: Signals finalize on bar close; intrabar graphics can adjust during the bar (Pine standard).
Very flat sessions: If price and volume are extremely quiet, expect fewer alerts; that restraint is intentional.
Who is this for?
Beginners who want one clean overlay for structure and one simple oscillator for timing—without wrestling settings.
Intermediates seeking a coherent trend/pressure framework with HTF confirmation.
Advanced users who appreciate robust stats and clean engineering behind the visuals.
Disclaimer: Educational purposes only. Not financial advice. Trading involves risk. Use at your own discretion.

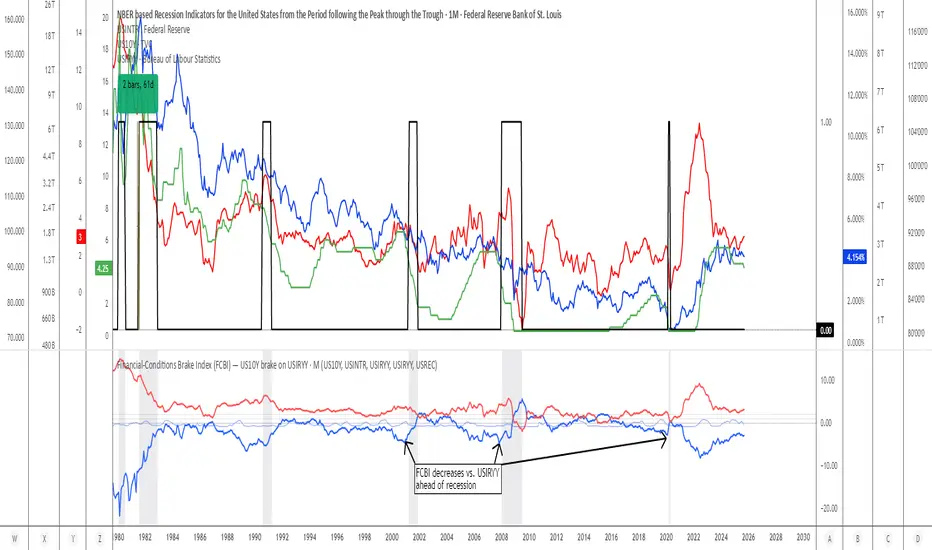
Financial-Conditions Brake Index (FCBI) — US10Y brake on USIRYYFinancial-Conditions Brake Index (FCBI) – US10Y Brake on USIRYY
Concept
The Financial-Conditions Brake Index (FCBI) measures how U.S. long-term yields (US10Y) interact with the Federal Funds Rate (USINTR) and inflation (CPI YoY) to shape real-rate conditions (USIRYY).
It visualizes whether the bond market is tightening or loosening overall financial conditions relative to the Federal Reserve’s policy stance.
Formula
FCBI = (US10Y) − (USINTR) − (CPI YoY)
How It Works
The FCBI expresses the difference between the long-term yield curve and short-term policy rates, adjusted for inflation. It shows whether the long end of the curve is amplifying or counteracting the Fed’s stance.
FCBI > +2 → Strong brake → Long yields remain elevated despite easing → tight conditions → recession delayed.
FCBI +1 to +2 → Mild brake → Financial transmission slower; lag ≈ 12–18 months.
FCBI 0 to +1 → Neutral → Typical early post-cut environment.
FCBI < 0 → Accelerator → Long yields and inflation expectations falling → liquidity flows freely → recession often follows within 6–14 months.
How to Read the Chart
Blue line (FCBI) shows the strength of the financial brake.
Red line (USIRYY) represents the real yield baseline.
Recession shading (gray) marks NBER recessions for comparison.
FCBI < USIRYY → Brake engaged → financial conditions tighter than real-rate baseline.
FCBI > USIRYY → Brake released → long end easing faster than policy → liquidity surge → late-cycle setup.
Historically, U.S. recessions begin on average about 14 months after the first Fed rate cut, and a decline of the FCBI below zero often precedes that window.
Practical Use
Use the FCBI to identify when policy transmission is blocked (brake engaged) or flowing (brake released).
Cross-check with yield-curve inversions, Fed policy shifts, and inflation expectations to estimate macro timing windows.
Current Example (Oct 2025)
FCBI ≈ −3.1, USIRYY ≈ +3.0 → Brake still engaged.
Once FCBI rises above USIRYY and crosses positive, it signals the “brake released” phase — historically the final liquidity surge before a U.S. recession.
Summary
FCBI shows how tight the brake is.
USIRYY shows how fast the car is moving.
When FCBI rises above USIRYY, the brake is released — liquidity accelerates and the historical recession countdown begins.
Asia & London Session High/Low – EOD Segments (v4.5)What it does
Plots the Asia and London session high & low each day.
When a session ends, its high/low are locked (non-repainting) and drawn as horizontal segments that auto-extend to the end of that same day (no infinite rays).
Optional labels show the exact level at session close.
Toggle whether to keep prior days on the chart or auto-clear them on the first bar of a new day.
Why traders use it
Quickly see overnight liquidity levels that often act as magnets or barriers during the U.S. session.
Map session range extremes for breakout/reversal planning, partials, and invalidation.
Works great alongside VWAP, 8/20/200 MAs, or your NY session tools to build confluence.
How it works
You define the session windows (defaults: Asia 00:00–06:00, London 07:00–11:00).
While a session is active, the script tracks running high/low.
On the bar after the session ends, the level is finalized and drawn; the segment’s right edge updates each bar until EOD, then stops automatically.
Inputs
Session Timezone: “Exchange”, UTC, or a specific region (set this to match your venue).
Asia / London Session: editable HHMM-HHMM windows.
Show Asia / Show London: enable either/both sessions.
Keep history: keep or auto-delete previous days.
Show labels: price labels at session close.
Colors & width: customize high/low colors and line width.
Best practices
Use on intraday timeframes (1–60m).
For equities/futures, set timezone to your exchange (e.g., America/New_York). For FX/crypto, pick what matches your workflow.
Common tweak: London 08:00–12:00 local; Asia 00:00–05:00 or your broker’s definition.
Notes
Non-repainting: levels only print once the session is complete.
Designed to be light and reliable—no boxes, just clean lines and labels.
If you want NY session levels, midlines (50%), anchored stop-time, or alerts on touches, this script can be extended.
For educational use only. Not financial advice.

Custom Net ATR Mapping - NateThis indicator measures how much an asset actually moves — both on average and across full periods — so traders can compare short-term volatility with longer-term net momentum.
It displays four key metrics in a simple color-coded table:
Standard ATR – the average daily (or per-bar) range, showing typical volatility.
Net ATR – the average open-to-close move, revealing how much price tends to travel directionally within each bar.
Total Net Move – the total distance price has moved from the start to the end of the most recent measurement window.
Average Net Move – the typical size of that full-period move, averaged across multiple recent windows.
Together these readings help you see whether recent price action is choppy but contained (high ATR, low net move) or sustained and directional (high net move relative to ATR) — useful for spotting trend strength, breakout potential, or range-bound conditions.

Jensen Alpha RS🧠 Jensen Alpha RS (J-Alpha RS)
Jensen Alpha RS is a quantitative performance evaluation tool designed to compare multiple assets against a benchmark using Jensen’s Alpha — a classic risk-adjusted return metric from modern portfolio theory.
It helps identify which assets have outperformed their benchmark on a risk-adjusted basis and ranks them in real time, with optional gating and visual tools. 📊
✨ Key Features
• 🧩 Multi-Asset Comparison: Evaluate up to four assets simultaneously.
• 🔀 Adaptive Benchmarking: TOTALES mode uses CRYPTOCAP:TOTALES (total crypto market cap ex-stablecoins). Dynamic mode automatically selects the strongest benchmark among BTC, ETH, and TOTALES based on rolling momentum.
• 📐 Jensen’s Alpha Calculation: Uses rolling covariance, variance, and beta to estimate α, showing how much each asset outperformed its benchmark.
• 📈 Z-Score & Consistency Metrics: Z-Score highlights statistical deviations in alpha; Consistency % shows how often α has been positive over a chosen window.
• 🚦 Trend & Zero Gates: Optional filters that require assets to be above EMA (trend) and/or have α > 0 for confirmation.
• 🏆 Leaders Board Table: Displays α, Z, Rank, Consistency %, and Gate ✓/✗ for all assets in a clear visual layout.
• 🔔 Dynamic Alerts: Get notified whenever the top alpha leader changes on confirmed (non-repainting) data.
• 🎨 Visual Enhancements: Smooth α with an SMA or color bars by the current top-performing asset.
🧭 Typical Use Cases
• 🔄 Portfolio Rotation & Relative Strength: Identify which assets consistently outperform their benchmark to optimize capital allocation.
• 🧮 Alpha Persistence Analysis: Gauge whether a trend’s performance advantage is statistically sustainable.
• 🌐 Market Regime Insight: Observe how asset leadership rotates as benchmarks shift across market cycles.
⚙️ Inputs Overview
• 📝 Assets (1–4): Select up to four tickers for evaluation.
• 🧭 Benchmark Mode: Choose between static TOTALES or Dynamic auto-selection.
• 📏 Alpha Settings: Adjustable lookback, smoothing, and consistency windows.
• 🚦 Gates: Optional trend and alpha filters to refine results.
• 🖥️ Display: Enable/disable table and customize colors.
• 🔔 Alerts: Toggle notifications on leadership changes.
🔎 Formula Basis
Jensen’s Alpha (α) is estimated as:
α = E − β × E
where β = Cov(Ra, Rb) / Var(Rb), and Ra/Rb represent asset and benchmark returns, respectively.
A positive α indicates outperformance relative to the risk-adjusted benchmark expectation. ✅
⚠️ Disclaimer
This script is for educational and analytical purposes only.
It is NOT a signal. 🚫📉
It does not constitute financial advice, trading signals, or investment recommendations. 💬
The author is not responsible for any financial losses or trading decisions made based on this indicator. 🙏
Always perform your own analysis and use proper risk management. 🛡️

Session Volume Spike DetectorSession Volume Spike Detector (Buy/Sell, Dual Windows, MTF + Edge/Cooldown)
What it does
Detects statistically significant buy/sell volume spikes inside two DST-aware Mountain Time sessions and projects 1m / 5m / 10m signals onto any chart timeframe (even 1s). Spikes are confirmed at the close of their native bar and are edge-triggered with optional cooldowns to prevent duplicate alerts.
How spikes are detected
Volume ≥ SMA × multiplier
Optional jump vs recent highest volume
Optional Z-Score gate for significance
Separate Buy/Sell logic using your Direction Mode (Prev Close or Candle Body)
Multi-Timeframe (MTF) display
Shows 1m, 5m, 10m arrows on your current chart
Each HTF fires once on its bar close (no repaint after close)
Sessions (DST-aware, MT)
Morning: 05:30–08:30
Midday: 11:00–13:30
Spikes only count inside these windows.
Inputs & styling
Thresholds: SMA length, multipliers, recent lookback, Z-Score toggle/level
Toggles for which TFs to display (chart TF, 1m, 5m, 10m)
Per-TF colors + cooldowns (seconds) for Any TF, 1m, 5m, 10m
Alerts (edge + cooldown)
MTF Volume Spike (Any TF) — fires on the first qualifying spike across enabled TFs
1m / 5m / 10m Volume Spike — per-TF alerts, Buy or Sell
Recommended: set alert Trigger = Once per bar close. Cooldowns tame “triggered too often” warnings.
Great with
FVG zones, bank/insto levels, session range breaks, and trend filters. Use the MTF arrows as a participation/pressure tell to confirm or fade moves.
Notes
Works on any symbol/timeframe; best viewed on 1m or sub-minute charts.
HTF spikes appear on the bar close of 1m/5m/10m respectively.
No dynamic plot titles; Pine v6-safe.
Short summary (≤250 chars):
MTF volume-spike detector for intraday sessions (DST-aware, MT). Projects 1m/5m/10m buy/sell spikes onto any chart, with edge-triggered alerts and per-TF cooldowns to prevent duplicates. Ideal for spotting institutional participation.

ORB 15m + MAs (v4.1)Session ORB Live Pro — Pre-Market Boxes & MA Suite (v4.1)
What it is
A precision Opening Range Breakout (ORB) tool that anchors every session to one specific 15-minute candle—then projects that same high/low onto lower timeframes so your 1m/5m levels always match the source 15m bar. Perfect for scalpers who want session structure without drift.
What it draws
Asia, Pre-London, London, Pre-New York, New York session boxes.
On 15m: only the high/low of the first 15-minute bar of each window (optionally persists for extra bars).
On 5m: mirrors the same 15m range, visible up to 10 bars.
On 1m: mirrors the same 15m range, visible up to 15 bars.
Levels update live while the 15m candle is forming, then lock.
Fully editable windows (easy UX)
Change session times with TradingView’s native input.session fields using the familiar format HHMM-HHMM:1234567. You can tweak each window independently:
Asia
Pre-London
London
Pre-New York
New York
Multi-TF logic (no guesswork)
Designed to show only on 1m, 5m, 15m (by default).
15m = ground truth. Lower timeframes never “recalculate a different range”—they mirror the 15m bar for that session, exactly.
Alerts
Optional breakout alerts when price closes above/below the session range.
Clean visuals
Per-session color controls (box + lines). Boxes extend only for the configured number of bars per timeframe, keeping charts uncluttered.
Built-in MA suite
SMA 50 and RMA 200.
Three extra MAs (SMA/EMA/RMA/WMA/HMA) with selectable color, width, and style (line, stepline, circles).
Why traders like it
Consistency: Lower-TF ranges always match the 15m source bar.
Speed: You see structure immediately—no waiting for N bars.
Control: Edit session times directly; tune how long boxes stay on chart per TF.
Clarity: Minimal, purposeful plotting with alerts when it matters.
Quick start
Set your session times via the five input.session fields.
Choose how long boxes persist on 1m/5m/15m.
Enable alerts if you want instant breakout notifications.
(Optional) Configure the MA suite for trend/bias context.
Best for
Intraday traders and scalpers who rely on repeatable session behavior and demand exact cross-TF alignment of ORB levels.

Small Business Economic Conditions - Statistical Analysis ModelThe Small Business Economic Conditions Statistical Analysis Model (SBO-SAM) represents an econometric approach to measuring and analyzing the economic health of small business enterprises through multi-dimensional factor analysis and statistical methodologies. This indicator synthesizes eight fundamental economic components into a composite index that provides real-time assessment of small business operating conditions with statistical rigor. The model employs Z-score standardization, variance-weighted aggregation, higher-order moment analysis, and regime-switching detection to deliver comprehensive insights into small business economic conditions with statistical confidence intervals and multi-language accessibility.
1. Introduction and Theoretical Foundation
The development of quantitative models for assessing small business economic conditions has gained significant importance in contemporary financial analysis, particularly given the critical role small enterprises play in economic development and employment generation. Small businesses, typically defined as enterprises with fewer than 500 employees according to the U.S. Small Business Administration, constitute approximately 99.9% of all businesses in the United States and employ nearly half of the private workforce (U.S. Small Business Administration, 2024).
The theoretical framework underlying the SBO-SAM model draws extensively from established academic research in small business economics and quantitative finance. The foundational understanding of key drivers affecting small business performance builds upon the seminal work of Dunkelberg and Wade (2023) in their analysis of small business economic trends through the National Federation of Independent Business (NFIB) Small Business Economic Trends survey. Their research established the critical importance of optimism, hiring plans, capital expenditure intentions, and credit availability as primary determinants of small business performance.
The model incorporates insights from Federal Reserve Board research, particularly the Senior Loan Officer Opinion Survey (Federal Reserve Board, 2024), which demonstrates the critical importance of credit market conditions in small business operations. This research consistently shows that small businesses face disproportionate challenges during periods of credit tightening, as they typically lack access to capital markets and rely heavily on bank financing.
The statistical methodology employed in this model follows the econometric principles established by Hamilton (1989) in his work on regime-switching models and time series analysis. Hamilton's framework provides the theoretical foundation for identifying different economic regimes and understanding how economic relationships may vary across different market conditions. The variance-weighted aggregation technique draws from modern portfolio theory as developed by Markowitz (1952) and later refined by Sharpe (1964), applying these concepts to economic indicator construction rather than traditional asset allocation.
Additional theoretical support comes from the work of Engle and Granger (1987) on cointegration analysis, which provides the statistical framework for combining multiple time series while maintaining long-term equilibrium relationships. The model also incorporates insights from behavioral economics research by Kahneman and Tversky (1979) on prospect theory, recognizing that small business decision-making may exhibit systematic biases that affect economic outcomes.
2. Model Architecture and Component Structure
The SBO-SAM model employs eight orthogonalized economic factors that collectively capture the multifaceted nature of small business operating conditions. Each component is normalized using Z-score standardization with a rolling 252-day window, representing approximately one business year of trading data. This approach ensures statistical consistency across different market regimes and economic cycles, following the methodology established by Tsay (2010) in his treatment of financial time series analysis.
2.1 Small Cap Relative Performance Component
The first component measures the performance of the Russell 2000 index relative to the S&P 500, capturing the market-based assessment of small business equity valuations. This component reflects investor sentiment toward smaller enterprises and provides a forward-looking perspective on small business prospects. The theoretical justification for this component stems from the efficient market hypothesis as formulated by Fama (1970), which suggests that stock prices incorporate all available information about future prospects.
The calculation employs a 20-day rate of change with exponential smoothing to reduce noise while preserving signal integrity. The mathematical formulation is:
Small_Cap_Performance = (Russell_2000_t / S&P_500_t) / (Russell_2000_{t-20} / S&P_500_{t-20}) - 1
This relative performance measure eliminates market-wide effects and isolates the specific performance differential between small and large capitalization stocks, providing a pure measure of small business market sentiment.
2.2 Credit Market Conditions Component
Credit Market Conditions constitute the second component, incorporating commercial lending volumes and credit spread dynamics. This factor recognizes that small businesses are particularly sensitive to credit availability and borrowing costs, as established in numerous Federal Reserve studies (Bernanke and Gertler, 1995). Small businesses typically face higher borrowing costs and more stringent lending standards compared to larger enterprises, making credit conditions a critical determinant of their operating environment.
The model calculates credit spreads using high-yield bond ETFs relative to Treasury securities, providing a market-based measure of credit risk premiums that directly affect small business borrowing costs. The component also incorporates commercial and industrial loan growth data from the Federal Reserve's H.8 statistical release, which provides direct evidence of lending activity to businesses.
The mathematical specification combines these elements as:
Credit_Conditions = α₁ × (HYG_t / TLT_t) + α₂ × C&I_Loan_Growth_t
where HYG represents high-yield corporate bond ETF prices, TLT represents long-term Treasury ETF prices, and C&I_Loan_Growth represents the rate of change in commercial and industrial loans outstanding.
2.3 Labor Market Dynamics Component
The Labor Market Dynamics component captures employment cost pressures and labor availability metrics through the relationship between job openings and unemployment claims. This factor acknowledges that labor market tightness significantly impacts small business operations, as these enterprises typically have less flexibility in wage negotiations and face greater challenges in attracting and retaining talent during periods of low unemployment.
The theoretical foundation for this component draws from search and matching theory as developed by Mortensen and Pissarides (1994), which explains how labor market frictions affect employment dynamics. Small businesses often face higher search costs and longer hiring processes, making them particularly sensitive to labor market conditions.
The component is calculated as:
Labor_Tightness = Job_Openings_t / (Unemployment_Claims_t × 52)
This ratio provides a measure of labor market tightness, with higher values indicating greater difficulty in finding workers and potential wage pressures.
2.4 Consumer Demand Strength Component
Consumer Demand Strength represents the fourth component, combining consumer sentiment data with retail sales growth rates. Small businesses are disproportionately affected by consumer spending patterns, making this component crucial for assessing their operating environment. The theoretical justification comes from the permanent income hypothesis developed by Friedman (1957), which explains how consumer spending responds to both current conditions and future expectations.
The model weights consumer confidence and actual spending data to provide both forward-looking sentiment and contemporaneous demand indicators. The specification is:
Demand_Strength = β₁ × Consumer_Sentiment_t + β₂ × Retail_Sales_Growth_t
where β₁ and β₂ are determined through principal component analysis to maximize the explanatory power of the combined measure.
2.5 Input Cost Pressures Component
Input Cost Pressures form the fifth component, utilizing producer price index data to capture inflationary pressures on small business operations. This component is inversely weighted, recognizing that rising input costs negatively impact small business profitability and operating conditions. Small businesses typically have limited pricing power and face challenges in passing through cost increases to customers, making them particularly vulnerable to input cost inflation.
The theoretical foundation draws from cost-push inflation theory as described by Gordon (1988), which explains how supply-side price pressures affect business operations. The model employs a 90-day rate of change to capture medium-term cost trends while filtering out short-term volatility:
Cost_Pressure = -1 × (PPI_t / PPI_{t-90} - 1)
The negative weighting reflects the inverse relationship between input costs and business conditions.
2.6 Monetary Policy Impact Component
Monetary Policy Impact represents the sixth component, incorporating federal funds rates and yield curve dynamics. Small businesses are particularly sensitive to interest rate changes due to their higher reliance on variable-rate financing and limited access to capital markets. The theoretical foundation comes from monetary transmission mechanism theory as developed by Bernanke and Blinder (1992), which explains how monetary policy affects different segments of the economy.
The model calculates the absolute deviation of federal funds rates from a neutral 2% level, recognizing that both extremely low and high rates can create operational challenges for small enterprises. The yield curve component captures the shape of the term structure, which affects both borrowing costs and economic expectations:
Monetary_Impact = γ₁ × |Fed_Funds_Rate_t - 2.0| + γ₂ × (10Y_Yield_t - 2Y_Yield_t)
2.7 Currency Valuation Effects Component
Currency Valuation Effects constitute the seventh component, measuring the impact of US Dollar strength on small business competitiveness. A stronger dollar can benefit businesses with significant import components while disadvantaging exporters. The model employs Dollar Index volatility as a proxy for currency-related uncertainty that affects small business planning and operations.
The theoretical foundation draws from international trade theory and the work of Krugman (1987) on exchange rate effects on different business segments. Small businesses often lack hedging capabilities, making them more vulnerable to currency fluctuations:
Currency_Impact = -1 × DXY_Volatility_t
2.8 Regional Banking Health Component
The eighth and final component, Regional Banking Health, assesses the relative performance of regional banks compared to large financial institutions. Regional banks traditionally serve as primary lenders to small businesses, making their health a critical factor in small business credit availability and overall operating conditions.
This component draws from the literature on relationship banking as developed by Boot (2000), which demonstrates the importance of bank-borrower relationships, particularly for small enterprises. The calculation compares regional bank performance to large financial institutions:
Banking_Health = (Regional_Banks_Index_t / Large_Banks_Index_t) - 1
3. Statistical Methodology and Advanced Analytics
The model employs statistical techniques to ensure robustness and reliability. Z-score normalization is applied to each component using rolling 252-day windows, providing standardized measures that remain consistent across different time periods and market conditions. This approach follows the methodology established by Engle and Granger (1987) in their cointegration analysis framework.
3.1 Variance-Weighted Aggregation
The composite index calculation utilizes variance-weighted aggregation, where component weights are determined by the inverse of their historical variance. This approach, derived from modern portfolio theory, ensures that more stable components receive higher weights while reducing the impact of highly volatile factors. The mathematical formulation follows the principle that optimal weights are inversely proportional to variance, maximizing the signal-to-noise ratio of the composite indicator.
The weight for component i is calculated as:
w_i = (1/σᵢ²) / Σⱼ(1/σⱼ²)
where σᵢ² represents the variance of component i over the lookback period.
3.2 Higher-Order Moment Analysis
Higher-order moment analysis extends beyond traditional mean and variance calculations to include skewness and kurtosis measurements. Skewness provides insight into the asymmetry of the sentiment distribution, while kurtosis measures the tail behavior and potential for extreme events. These metrics offer valuable information about the underlying distribution characteristics and potential regime changes.
Skewness is calculated as:
Skewness = E / σ³
Kurtosis is calculated as:
Kurtosis = E / σ⁴ - 3
where μ represents the mean and σ represents the standard deviation of the distribution.
3.3 Regime-Switching Detection
The model incorporates regime-switching detection capabilities based on the Hamilton (1989) framework. This allows for identification of different economic regimes characterized by distinct statistical properties. The regime classification employs percentile-based thresholds:
- Regime 3 (Very High): Percentile rank > 80
- Regime 2 (High): Percentile rank 60-80
- Regime 1 (Moderate High): Percentile rank 50-60
- Regime 0 (Neutral): Percentile rank 40-50
- Regime -1 (Moderate Low): Percentile rank 30-40
- Regime -2 (Low): Percentile rank 20-30
- Regime -3 (Very Low): Percentile rank < 20
3.4 Information Theory Applications
The model incorporates information theory concepts, specifically Shannon entropy measurement, to assess the information content of the sentiment distribution. Shannon entropy, as developed by Shannon (1948), provides a measure of the uncertainty or information content in a probability distribution:
H(X) = -Σᵢ p(xᵢ) log₂ p(xᵢ)
Higher entropy values indicate greater unpredictability and information content in the sentiment series.
3.5 Long-Term Memory Analysis
The Hurst exponent calculation provides insight into the long-term memory characteristics of the sentiment series. Originally developed by Hurst (1951) for analyzing Nile River flow patterns, this measure has found extensive application in financial time series analysis. The Hurst exponent H is calculated using the rescaled range statistic:
H = log(R/S) / log(T)
where R/S represents the rescaled range and T represents the time period. Values of H > 0.5 indicate long-term positive autocorrelation (persistence), while H < 0.5 indicates mean-reverting behavior.
3.6 Structural Break Detection
The model employs Chow test approximation for structural break detection, based on the methodology developed by Chow (1960). This technique identifies potential structural changes in the underlying relationships by comparing the stability of regression parameters across different time periods:
Chow_Statistic = (RSS_restricted - RSS_unrestricted) / RSS_unrestricted × (n-2k)/k
where RSS represents residual sum of squares, n represents sample size, and k represents the number of parameters.
4. Implementation Parameters and Configuration
4.1 Language Selection Parameters
The model provides comprehensive multi-language support across five languages: English, German (Deutsch), Spanish (Español), French (Français), and Japanese (日本語). This feature enhances accessibility for international users and ensures cultural appropriateness in terminology usage. The language selection affects all internal displays, statistical classifications, and alert messages while maintaining consistency in underlying calculations.
4.2 Model Configuration Parameters
Calculation Method: Users can select from four aggregation methodologies:
- Equal-Weighted: All components receive identical weights
- Variance-Weighted: Components weighted inversely to their historical variance
- Principal Component: Weights determined through principal component analysis
- Dynamic: Adaptive weighting based on recent performance
Sector Specification: The model allows for sector-specific calibration:
- General: Broad-based small business assessment
- Retail: Emphasis on consumer demand and seasonal factors
- Manufacturing: Enhanced weighting of input costs and currency effects
- Services: Focus on labor market dynamics and consumer demand
- Construction: Emphasis on credit conditions and monetary policy
Lookback Period: Statistical analysis window ranging from 126 to 504 trading days, with 252 days (one business year) as the optimal default based on academic research.
Smoothing Period: Exponential moving average period from 1 to 21 days, with 5 days providing optimal noise reduction while preserving signal integrity.
4.3 Statistical Threshold Parameters
Upper Statistical Boundary: Configurable threshold between 60-80 (default 70) representing the upper significance level for regime classification.
Lower Statistical Boundary: Configurable threshold between 20-40 (default 30) representing the lower significance level for regime classification.
Statistical Significance Level (α): Alpha level for statistical tests, configurable between 0.01-0.10 with 0.05 as the standard academic default.
4.4 Display and Visualization Parameters
Color Theme Selection: Eight professional color schemes optimized for different user preferences and accessibility requirements:
- Gold: Traditional financial industry colors
- EdgeTools: Professional blue-gray scheme
- Behavioral: Psychology-based color mapping
- Quant: Value-based quantitative color scheme
- Ocean: Blue-green maritime theme
- Fire: Warm red-orange theme
- Matrix: Green-black technology theme
- Arctic: Cool blue-white theme
Dark Mode Optimization: Automatic color adjustment for dark chart backgrounds, ensuring optimal readability across different viewing conditions.
Line Width Configuration: Main index line thickness adjustable from 1-5 pixels for optimal visibility.
Background Intensity: Transparency control for statistical regime backgrounds, adjustable from 90-99% for subtle visual enhancement without distraction.
4.5 Alert System Configuration
Alert Frequency Options: Three frequency settings to match different trading styles:
- Once Per Bar: Single alert per bar formation
- Once Per Bar Close: Alert only on confirmed bar close
- All: Continuous alerts for real-time monitoring
Statistical Extreme Alerts: Notifications when the index reaches 99% confidence levels (Z-score > 2.576 or < -2.576).
Regime Transition Alerts: Notifications when statistical boundaries are crossed, indicating potential regime changes.
5. Practical Application and Interpretation Guidelines
5.1 Index Interpretation Framework
The SBO-SAM index operates on a 0-100 scale with statistical normalization ensuring consistent interpretation across different time periods and market conditions. Values above 70 indicate statistically elevated small business conditions, suggesting favorable operating environment with potential for expansion and growth. Values below 30 indicate statistically reduced conditions, suggesting challenging operating environment with potential constraints on business activity.
The median reference line at 50 represents the long-term equilibrium level, with deviations providing insight into cyclical conditions relative to historical norms. The statistical confidence bands at 95% levels (approximately ±2 standard deviations) help identify when conditions reach statistically significant extremes.
5.2 Regime Classification System
The model employs a seven-level regime classification system based on percentile rankings:
Very High Regime (P80+): Exceptional small business conditions, typically associated with strong economic growth, easy credit availability, and favorable regulatory environment. Historical analysis suggests these periods often precede economic peaks and may warrant caution regarding sustainability.
High Regime (P60-80): Above-average conditions supporting business expansion and investment. These periods typically feature moderate growth, stable credit conditions, and positive consumer sentiment.
Moderate High Regime (P50-60): Slightly above-normal conditions with mixed signals. Careful monitoring of individual components helps identify emerging trends.
Neutral Regime (P40-50): Balanced conditions near long-term equilibrium. These periods often represent transition phases between different economic cycles.
Moderate Low Regime (P30-40): Slightly below-normal conditions with emerging headwinds. Early warning signals may appear in credit conditions or consumer demand.
Low Regime (P20-30): Below-average conditions suggesting challenging operating environment. Businesses may face constraints on growth and expansion.
Very Low Regime (P0-20): Severely constrained conditions, typically associated with economic recessions or financial crises. These periods often present opportunities for contrarian positioning.
5.3 Component Analysis and Diagnostics
Individual component analysis provides valuable diagnostic information about the underlying drivers of overall conditions. Divergences between components can signal emerging trends or structural changes in the economy.
Credit-Labor Divergence: When credit conditions improve while labor markets tighten, this may indicate early-stage economic acceleration with potential wage pressures.
Demand-Cost Divergence: Strong consumer demand coupled with rising input costs suggests inflationary pressures that may constrain small business margins.
Market-Fundamental Divergence: Disconnection between small-cap equity performance and fundamental conditions may indicate market inefficiencies or changing investor sentiment.
5.4 Temporal Analysis and Trend Identification
The model provides multiple temporal perspectives through momentum analysis, rate of change calculations, and trend decomposition. The 20-day momentum indicator helps identify short-term directional changes, while the Hodrick-Prescott filter approximation separates cyclical components from long-term trends.
Acceleration analysis through second-order momentum calculations provides early warning signals for potential trend reversals. Positive acceleration during declining conditions may indicate approaching inflection points, while negative acceleration during improving conditions may suggest momentum loss.
5.5 Statistical Confidence and Uncertainty Quantification
The model provides comprehensive uncertainty quantification through confidence intervals, volatility measures, and regime stability analysis. The 95% confidence bands help users understand the statistical significance of current readings and identify when conditions reach historically extreme levels.
Volatility analysis provides insight into the stability of current conditions, with higher volatility indicating greater uncertainty and potential for rapid changes. The regime stability measure, calculated as the inverse of volatility, helps assess the sustainability of current conditions.
6. Risk Management and Limitations
6.1 Model Limitations and Assumptions
The SBO-SAM model operates under several important assumptions that users must understand for proper interpretation. The model assumes that historical relationships between economic variables remain stable over time, though the regime-switching framework helps accommodate some structural changes. The 252-day lookback period provides reasonable statistical power while maintaining sensitivity to changing conditions, but may not capture longer-term structural shifts.
The model's reliance on publicly available economic data introduces inherent lags in some components, particularly those based on government statistics. Users should consider these timing differences when interpreting real-time conditions. Additionally, the model's focus on quantitative factors may not fully capture qualitative factors such as regulatory changes, geopolitical events, or technological disruptions that could significantly impact small business conditions.
The model's timeframe restrictions ensure statistical validity by preventing application to intraday periods where the underlying economic relationships may be distorted by market microstructure effects, trading noise, and temporal misalignment with the fundamental data sources. Users must utilize daily or longer timeframes to ensure the model's statistical foundations remain valid and interpretable.
6.2 Data Quality and Reliability Considerations
The model's accuracy depends heavily on the quality and availability of underlying economic data. Market-based components such as equity indices and bond prices provide real-time information but may be subject to short-term volatility unrelated to fundamental conditions. Economic statistics provide more stable fundamental information but may be subject to revisions and reporting delays.
Users should be aware that extreme market conditions may temporarily distort some components, particularly those based on financial market data. The model's statistical normalization helps mitigate these effects, but users should exercise additional caution during periods of market stress or unusual volatility.
6.3 Interpretation Caveats and Best Practices
The SBO-SAM model provides statistical analysis and should not be interpreted as investment advice or predictive forecasting. The model's output represents an assessment of current conditions based on historical relationships and may not accurately predict future outcomes. Users should combine the model's insights with other analytical tools and fundamental analysis for comprehensive decision-making.
The model's regime classifications are based on historical percentile rankings and may not fully capture the unique characteristics of current economic conditions. Users should consider the broader economic context and potential structural changes when interpreting regime classifications.
7. Academic References and Bibliography
Bernanke, B. S., & Blinder, A. S. (1992). The Federal Funds Rate and the Channels of Monetary Transmission. American Economic Review, 82(4), 901-921.
Bernanke, B. S., & Gertler, M. (1995). Inside the Black Box: The Credit Channel of Monetary Policy Transmission. Journal of Economic Perspectives, 9(4), 27-48.
Boot, A. W. A. (2000). Relationship Banking: What Do We Know? Journal of Financial Intermediation, 9(1), 7-25.
Chow, G. C. (1960). Tests of Equality Between Sets of Coefficients in Two Linear Regressions. Econometrica, 28(3), 591-605.
Dunkelberg, W. C., & Wade, H. (2023). NFIB Small Business Economic Trends. National Federation of Independent Business Research Foundation, Washington, D.C.
Engle, R. F., & Granger, C. W. J. (1987). Co-integration and Error Correction: Representation, Estimation, and Testing. Econometrica, 55(2), 251-276.
Fama, E. F. (1970). Efficient Capital Markets: A Review of Theory and Empirical Work. Journal of Finance, 25(2), 383-417.
Federal Reserve Board. (2024). Senior Loan Officer Opinion Survey on Bank Lending Practices. Board of Governors of the Federal Reserve System, Washington, D.C.
Friedman, M. (1957). A Theory of the Consumption Function. Princeton University Press, Princeton, NJ.
Gordon, R. J. (1988). The Role of Wages in the Inflation Process. American Economic Review, 78(2), 276-283.
Hamilton, J. D. (1989). A New Approach to the Economic Analysis of Nonstationary Time Series and the Business Cycle. Econometrica, 57(2), 357-384.
Hurst, H. E. (1951). Long-term Storage Capacity of Reservoirs. Transactions of the American Society of Civil Engineers, 116(1), 770-799.
Kahneman, D., & Tversky, A. (1979). Prospect Theory: An Analysis of Decision under Risk. Econometrica, 47(2), 263-291.
Krugman, P. (1987). Pricing to Market When the Exchange Rate Changes. In S. W. Arndt & J. D. Richardson (Eds.), Real-Financial Linkages among Open Economies (pp. 49-70). MIT Press, Cambridge, MA.
Markowitz, H. (1952). Portfolio Selection. Journal of Finance, 7(1), 77-91.
Mortensen, D. T., & Pissarides, C. A. (1994). Job Creation and Job Destruction in the Theory of Unemployment. Review of Economic Studies, 61(3), 397-415.
Shannon, C. E. (1948). A Mathematical Theory of Communication. Bell System Technical Journal, 27(3), 379-423.
Sharpe, W. F. (1964). Capital Asset Prices: A Theory of Market Equilibrium under Conditions of Risk. Journal of Finance, 19(3), 425-442.
Tsay, R. S. (2010). Analysis of Financial Time Series (3rd ed.). John Wiley & Sons, Hoboken, NJ.
U.S. Small Business Administration. (2024). Small Business Profile. Office of Advocacy, Washington, D.C.
8. Technical Implementation Notes
The SBO-SAM model is implemented in Pine Script version 6 for the TradingView platform, ensuring compatibility with modern charting and analysis tools. The implementation follows best practices for financial indicator development, including proper error handling, data validation, and performance optimization.
The model includes comprehensive timeframe validation to ensure statistical accuracy and reliability. The indicator operates exclusively on daily (1D) timeframes or higher, including weekly (1W), monthly (1M), and longer periods. This restriction ensures that the statistical analysis maintains appropriate temporal resolution for the underlying economic data sources, which are primarily reported on daily or longer intervals.
When users attempt to apply the model to intraday timeframes (such as 1-minute, 5-minute, 15-minute, 30-minute, 1-hour, 2-hour, 4-hour, 6-hour, 8-hour, or 12-hour charts), the system displays a comprehensive error message in the user's selected language and prevents execution. This safeguard protects users from potentially misleading results that could occur when applying daily-based economic analysis to shorter timeframes where the underlying data relationships may not hold.
The model's statistical calculations are performed using vectorized operations where possible to ensure computational efficiency. The multi-language support system employs Unicode character encoding to ensure proper display of international characters across different platforms and devices.
The alert system utilizes TradingView's native alert functionality, providing users with flexible notification options including email, SMS, and webhook integrations. The alert messages include comprehensive statistical information to support informed decision-making.
The model's visualization system employs professional color schemes designed for optimal readability across different chart backgrounds and display devices. The system includes dynamic color transitions based on momentum and volatility, professional glow effects for enhanced line visibility, and transparency controls that allow users to customize the visual intensity to match their preferences and analytical requirements. The clean confidence band implementation provides clear statistical boundaries without visual distractions, maintaining focus on the analytical content.
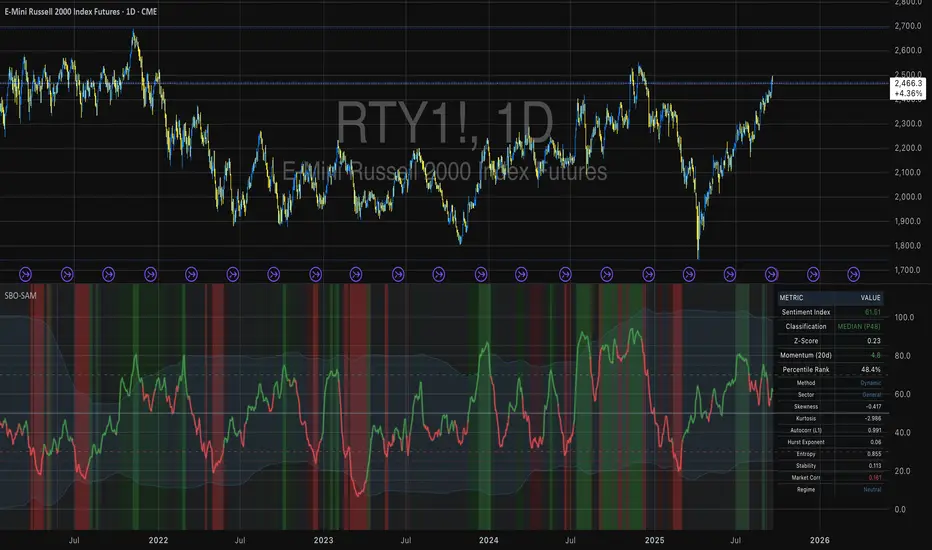
Hazel nut BB Strategy, volume base- lite versionHazel nut BB Strategy, volume base — lite version
Having knowledge and information in financial markets is only useful when a trader operates with a well-defined trading strategy. Trading strategies assist in capital management, profit-taking, and reducing potential losses.
This strategy is built upon the core principle of supply and demand dynamics. Alongside this foundation, one of the widely used technical tools — the Bollinger Bands — is employed to structure a framework for profit management and risk control.
In this strategy, the interaction of these tools is explained in detail. A key point to note is that for calculating buy and sell volumes, a lower timeframe function is used. When applied with a tick-level resolution, this provides the most precise measurement of buyer/seller flows. However, this comes with a limitation of reduced historical depth. Users should be aware of this trade-off: if precise tick-level data is required, shorter timeframes should be considered to extend historical coverage .
The strategy offers multiple configuration options. Nevertheless, it should be treated strictly as a supportive tool rather than a standalone trading system. Decisions must integrate personal analysis and other instruments. For example, in highly volatile assets with narrow ranges, it is recommended to adjust profit-taking and stop-loss percentages to smaller values.
◉ Volume Settings
• Buyer and seller volume (up/down volume) are requested from a lower timeframe, with an option to override the automatic resolution.
• A global lookback period is applied to calculate moving averages and cumulative sums of buy/sell/delta volumes.
• Ratios of buyers/sellers to total volume are derived both on the current bar and across the lookback window.
◉ Bollinger Band
• Bands are computed using configurable moving averages (SMA, EMA, RMA, WMA, VWMA).
• Inputs allow control of length, standard deviation multiplier, and offset.
• The basis, upper, and lower bands are plotted, with a shaded background between them.
◉ Progress & Proximity
• Relative position of the price to the Bollinger basis is expressed as percentages (qPlus/qMinus).
• “Near band” conditions are triggered when price progress toward the upper or lower band exceeds a user-defined threshold (%).
• A signed score (sScore) represents how far the close has moved above or below the basis relative to band width.
◉ Info Table
• Optional compact table summarizing:
• - Upper/lower band margins
• - Buyer/seller volumes with moving averages
• - Delta and cumulative delta
• - Buyer/seller ratios per bar and across the window
• - Money flow values (buy/sell/delta × price) for bar-level and summed periods
• The table is neutral-colored and resizable for different chart layouts.
◉ Zone Event Gate
• Tracks entry into and exit from “near band” zones.
• Arming logic: a side is armed when price enters a band proximity zone.
• Trigger logic: on exit, a trade event is generated if cumulative buyer or seller volume dominates over a configurable window.
◉ Trading Logic
• Orders are placed only on zone-exit events, conditional on volume dominance.
• Position sizing is defined as a fixed percentage of strategy equity.
• Long entries occur when leaving the lower zone with buyer dominance; short entries occur when leaving the upper zone with seller dominance.
◉ Exit Rules
• Open positions are managed by a strict priority sequence:
• 1. Stop-loss (% of entry price)
• 2. Take-profit (% of entry price)
• 3. Opposite-side event (zone exit with dominance in the other direction)
• Stop-loss and take-profit levels are configurable
◉ Notes
• This lite version is intended to demonstrate the interaction of Bollinger Bands and volume-based dominance logic.
• It provides a framework to observe how price reacts at band boundaries under varying buy/sell pressure, and how zone exits can be systematically converted into entry/exit signals.
When configuring this strategy, it is essential to carefully review the settings within the Strategy Tester. Ensure that the chosen parameters and historical data options are correctly aligned with the intended use. Accurate back testing depends on applying proper configurations for historical reference. The figure below illustrates sample result and configuration type.

QZ Trend (Crypto Edition) v1.1a: Donchian, EMA, ATR, Liquidity/FThe "QZ Trend (Crypto Edition)" is a rules-based trend-following breakout strategy for crypto spot or perpetual contracts, focusing on following trends, prioritizing risk control, seeking small losses and big wins, and trading only when advantageous.
Key mechanisms include:
- Market filters: Screen favorable conditions via ADX (trend strength), dollar volume (liquidity), funding fee windows, session/weekend restrictions, and spot-long-only settings.
- Signals & entries: Based on price position relative to EMA and EMA trends, combined with breaking Donchian channel extremes (with ATR ratio confirmation), plus single-position rules and post-exit cooldowns.
- Position sizing: Calculate positions by fixed risk percentage; initial stop-loss is ATR-based, complying with exchange min/max lot requirements.
- Exits & risk management: Include initial stop-loss, trailing stop (tightens only), break-even rule (stop moves to entry when target floating profit is hit), time-based exit, and post-exit cooldowns.
- Pyramiding: Add positions only when profitable with favorable momentum, requiring ATR-based spacing; add size is a fraction of the base position, with layers sharing stop logic but having unique order IDs.
Charts display EMA, Donchian channels, current stop lines, and highlight low ADX, avoidable funding windows, and low-liquidity periods.
Recommend starting with 4H or 1D timeframes, with typical parameters varying by cycle. Liquidity settings differ by token; perpetuals should enable funding window filters, while spot requires "long-only" and matching fees. The strategy performs well in trends with quick stop-losses but faces whipsaws in ranges (filters mitigate but don’t eliminate noise). Share your symbol and timeframe for tailored parameters.

Rolling Range Bands by tvigRolling Range Bands
Plots two dynamic price envelopes that track the highest and lowest prices over a Short and Long lookback. Use them to see near-term vs. broader market structure, evolving support/resistance, and volatility changes at a glance.
What it shows
• Short Bands: recent trading range (fast, more reactive).
• Long Bands: broader range (slow, structural).
• Optional step-line style and shaded zones for clarity.
• Option to use completed bar values to avoid intrabar jitter (no repaint).
How to read
• Price pressing the short high while the long band rises → short-term momentum in a larger uptrend.
• Price riding the short low inside a falling long band → weakness with trend alignment.
• Band squeeze (narrowing) → compression; watch for breakout.
• Band expansion (widening) → rising volatility; expect larger swings.
• Repeated touches/rejections of long bands → potential areas of support/resistance.
Inputs
• Short Window, Long Window (bars)
• Use Close only (vs. High/Low)
• Use completed bar values (stability)
• Step-line style and Band shading
Tips
• Works on any symbol/timeframe; tune windows to your market.
• For consistent scaling, pin the indicator to the same right price scale as the chart.
Not financial advice; combine with trend/volume/RSI or your system for entries/exits.
Technical Summary VWAP | RSI | VolatilityTechnical Summary VWAP | RSI | Volatility
The Quantum Trading Matrix is a multi-dimensional market-analysis dashboard designed as an educational and idea-generation tool to help traders read price structure, participation, momentum and volatility in one compact view. It is not an automated execution system; rather, it aggregates lightweight “quantum” signals — VWAP position, momentum oscillator behaviour, multi-EMA trend scoring, volume flow and institutional activity heuristics, market microstructure pivots and volatility measures — and synthesizes them into a single, transparent score and signal recommendation. The primary goal is to make explicit why a given market looks favourable or unfavourable by showing the individual ingredients and how they combine, enabling traders to learn, test and form rules based on observable market mechanics.
Each module of the matrix answers a distinct market question. VWAP and its percentage distance indicate whether the current price is trading above or below the intraday volume-weighted average — a proxy for intraday institutional control and value. The quantum momentum oscillator (fast and slow EMA difference scaled to percent) captures short-to-intermediate momentum shifts, providing a quickly responsive view of directional pressure. Multi-EMA trend scoring (8/21/50) produces a simple, transparent trend score by counting conditions such as price above EMAs and cross-EMAs ordering; this score is used to categorize market trend into descriptive buckets (e.g., STRONG UP, WEAK UP, NEUTRAL, DOWN). Volume analysis compares current volume to a recent moving average and computes a Z-score to detect spikes and unusual participation; additional buy/sell pressure heuristics (buyingPressure, sellingPressure, flowRatio) estimate whether upside or downside participation dominates the bar. Institutional activity is approximated by flagging large orders relative to volume baseline (e.g., volume > 2.5× MA) and estimating a dark pool proxy; this is a heuristic to highlight bars that likely had large players involved.
The dashboard also performs market-structure detection with small pivot windows to identify recent local support/resistance areas and computes price position relative to the daily high/low (dailyMid, pricePosition). Volatility is measured via ATR divided by price and bucketed into LOW/NORMAL/HIGH/EXTREME categories to help you adapt stop sizing and expectational horizons. Finally, all these pieces feed an interpretable scoring function that rewards alignment: VWAP above, strong flow ratio, bullish trend score, bullish momentum, and favorable RSI zone add to the overall score which is presented as a 0–100 metric and a colored emoji indicator for at-a-glance assessment.
The mashup is purposeful: each indicator covers a failure mode of the other. For example, momentum readings can be misleading during volatility spikes; VWAP informs whether institutions are on the bid or offer; volume Z-score detects abnormal participation that can validate a breakout; multi-EMA score mitigates single-EMA whipsaws by requiring a combination of price/EMA conditions. Combining these signals increases information content while keeping each component explainable — a key compliance requirement. The script intentionally emphasizes transparency: when it shows a BUY/SELL/HOLD recommendation, the dashboard shows the underlying sub-components so a trader can see whether VWAP, momentum, volume, trend or structure primarily drove the score.
For practical use, adopt a clear workflow: (1) check the matrix score and read the component tiles (VWAP position, momentum, trend and volume) to understand the drivers; (2) confirm market-structure support/resistance and pricePosition relative to the daily range; (3) require at least two corroborating components (for example, VWAP ABOVE + Momentum BULLISH or Volume spike + Trend STRONG UP) before considering entries; (4) use ATR-based stops or daily pivot distance for stop placement and size positions such that the trade risks a small, pre-defined percent of capital; (5) for intraday scalps shorten holding time and tighten stops, for swing trades increase lookback lengths and require multi-timeframe (higher TF) agreement. Treat the matrix as an idea filter and replay lab: when an alert triggers, replay the bars and observe which components anticipated the move and which lagged.
Parameter tuning matters. Shortening the momentum length makes the oscillator more sensitive (useful for scalping), while lengthening it reduces noise for swing contexts. Volume profile bars and MA length should match the instrument’s liquidity — increase the MA for low-liquidity stocks to reduce false institutional flags. The trend multiplier and signal sensitivity parameters let you calibrate how aggressively the matrix counts micro evidence into the score. Always backtest parameter sets across multiple periods and instruments; run walk-forward tests and keep a simple out-of-sample validation window to reduce overfitting risk.
Limitations and failure modes are explicit: institutional flags and dark-pool estimates are heuristics and cannot substitute for true tape or broker-level order flow; volume split by price range is an approximation and will not perfectly reflect signed volume; pivot detection with small windows may miss larger structural swings; VWAP is typically intraday-centric and less meaningful across multi-day swing contexts; the score is additive and may not capture non-linear relationships between features in extreme market regimes (e.g., flash crashes, circuit breaker events, or overnight gaps). The matrix is also susceptible to false signals during major news releases when price and volume behavior dislocate from typical patterns. Users should explicitly test behavior around earnings, macro data and low-liquidity periods.
To learn with the matrix, perform these experiments: (A) collect all BUY/SELL alerts over a 6-month period and measure median outcome at 5, 20 and 60 bars; (B) require additional gating conditions (e.g., only accept BUY when flowRatio>60 and trendScore≥4) and compare expectancy; (C) vary the institutional threshold (2×, 2.5×, 3× volumeMA) to see how many true positive spikes remain; (D) perform multi-instrument tests to ensure parameters are not tuned to a single ticker. Document every test and prefer robust, slightly lower returns with clearer logic rather than tuned “optimal” results that fail out of sample.
Originality statement: This script’s originality lies in the curated combination of intraday value (VWAP), multi-EMA trend scoring, momentum percent oscillator, volume Z-score plus buy/sell flow heuristics and a compact, interpretable scoring system. The script is not a simple indicator mashup; it is a didactic ensemble specifically designed to make internal rationale visible so traders can learn how each market characteristic contributes to actionable probability. The tool’s novelty is its emphasis on interpretability — showing the exact contributing signals behind a composite score — enabling reproducible testing and educational value.
Finally, for TradingView publication, include a clear description listing the modules, a short non-technical summary of how they interact, the tunable inputs, limitations and a risk disclaimer. Remove any promotional content or external contact links. If you used trademark symbols, either provide registration details or remove them. This transparent documentation satisfies TradingView’s requirement that mashups justify their composition and teach users how to use them.
Quantum Trading Matrix — multi-factor intraday dashboard (educational use only).
Purpose: Combines intraday VWAP position, a fast/slow EMA momentum percent oscillator, multi-EMA trend scoring (8/21/50), volume Z-score and buy/sell flow heuristics, pivot-based microstructure detection, and ATR-based volatility buckets to produce a transparent, componentized market score and trade-idea indicator. The mashup is intentional: VWAP identifies intraday value, momentum detects short bursts, EMAs provide structural trend bias, and volume/flow confirm participation. Signals require alignment of at least two components (for example, VWAP ABOVE + Momentum BULLISH + positive flow) for higher confidence.
Inputs: momentum period, volume MA/profile length, EMA configuration (8/21/50), trend multiplier, signal sensitivity, color and display options. Use shorter momentum lengths for scalps and longer for swing analysis. Increase volume MA for thinly traded instruments.
Limitations: Institutional/dark-pool estimates and flow heuristics are approximations, not actual exchange tape. VWAP is intraday-focused. Expect false signals during major news or low-liquidity sessions. Backtest and paper-trade before applying real capital.
Risk Disclaimer: For education and analysis only. Not financial advice. Use proper risk management. The author is not responsible for trading losses.
________________________________________
Risk & Misuse Disclaimer
This indicator is provided for education, analysis and idea generation only. It is not investment or financial advice and does not guarantee profits. Institutional activity flags, dark-pool estimates and flow heuristics are approximations and should not be treated as exchange tape. Backtest thoroughly and use demo/paper accounts before trading real capital. Always apply appropriate position sizing and stop-loss rules. The author is not responsible for any trading losses resulting from the use or misuse of this tool.
________________________________________
Risk Disclaimer: This tool is provided for education and analysis only. It is not financial advice and does not guarantee returns. Users assume all risk for trades made based on this script. Back test thoroughly and use proper risk management.

TRAPPER TRENDLINES — RSIBuilds dynamic RSI trendlines by connecting the two most recent confirmed RSI swing points (highs→highs for resistance, lows→lows for support). Includes optional channel shading for the 30–70 zone, an RSI moving average, clean break alerts, and simple bullish/bearish divergence alerts versus price.
How it works
RSI pivots: A point on RSI is a swing high/low only if it is the most extreme value compared with a set number of bars on the left and the right (the Pivot Lookback).
RSI trendlines:
Resistance connects the last two confirmed RSI swing highs.
Support connects the last two confirmed RSI swing lows.
Lines can be Full Extend (update into the future) or Pivot Only.
Channel block: Optional fill of the 30–70 range for fast visual context.
Alerts:
Breaks of RSI support/resistance trendlines.
Basic bullish/bearish RSI divergences versus price pivots.
Inputs
RSI
RSI Length: Default 14 (standard).
Pivot Lookback: Bars to the left/right required to confirm an RSI swing.
Overbought / Oversold: 70 / 30 by default.
Line Extension: Full Extend or Pivot Only.
Visuals
Show RSI Moving Average / Signal Length: Optional smoothing line on RSI.
RSI/Signal colors: Customize plot colors.
Show 30–70 Channel Block: Toggle the middle-zone fill.
Tint pane background when RSI in channel: Optional subtle background when RSI is between OB/OS.
Divergences & Alerts
Enable RSI TL Break Alerts: Alert conditions for RSI line breaks.
Enable Divergence Alerts: Bullish/Bearish divergence alerts versus price.
Pairing with price for confluence/divergence
For accurate confluence and clearer divergences, align this RSI tool with your price trendline tool (for example, TRAPPER TRENDLINES — PRICE):
Set RSI Pivot Lookback equal to the Pivot Left/Right size used on price.
Example: Price uses Pivot Left = 50 and Pivot Right = 50 → set RSI Pivot Lookback = 50.
Keep RSI Length = 14 and OB/OS = 70/30 unless you have a specific edge.
Interpretation:
Confluence: Price reacts at its trendline while RSI reacts at its own line in the same direction.
Divergence: Price makes a higher high while RSI makes a lower high (bearish), or price makes a lower low while RSI makes a higher low (bullish), using matched pivot windows.
Suggested settings
Higher timeframes (4H / 1D / 1W): Pivot Lookback = 50; optional RSI MA length 14; channel block ON.
Intraday (15m / 30m / 1H): Pivot Lookback = 30; optional RSI MA length 14.
Always mirror your price pivot size to this RSI Pivot Lookback for consistent swings.
Reading the signals
RSI trendline touch/hold: Momentum reacting at structure; look for confluence with price levels.
RSI Trendline Break Up / Down: Momentum shift; consider price structure and retests.
Bullish/Bearish Divergence: Confirm only when pivots are matched and the new swing is confirmed.
Notes & limitations
Pivots require future bars to confirm by design; trendlines update as new swings confirm.
Divergence logic compares RSI pivots to price pivots with the same lookback; mismatched windows can produce false positives.
No strategy entries/exits or performance claims are provided. This is an analytical tool.
Alerts (titles/messages)
RSI: Trendline Break Up — “RSI broke falling resistance line.”
RSI: Trendline Break Down — “RSI broke rising support line.”
RSI: Bullish Divergence — “Bullish RSI divergence confirmed.”
RSI: Bearish Divergence — “Bearish RSI divergence confirmed.”
Quick start
Add the indicator to a separate pane.
Set Pivot Lookback to match your price tool’s pivot size (e.g., 50).
Optionally toggle the RSI MA and Channel Block for clarity.
Enable alerts if you want notifications on RSI line breaks and divergences.
Use with TRAPPER TRENDLINES — PRICE or any price-based trendline tool for confluence/divergence analysis.
Compliance
This script is for educational purposes only and does not constitute financial advice. Trading involves risk. Past performance does not guarantee future results. No performance claims are made.

FlowFusion Money Flow — FP + VWAP Drift + PVT (−100..+100)Title (ASCII only)
FlowFusion Money Flow — Flow Pressure + Rolling VWAP Drift + PVT (Normalized −100..+100)
Short Description
Original money-flow oscillator combining Flow Pressure, Rolling VWAP Drift, and PVT Momentum into one normalized score (−100..+100) with a signal line, thresholds, optional component plots, and ready-made alerts.
Full Description (meets “originality & usefulness”)
What’s original
FlowFusion Money Flow is not a generic mashup. It builds a single score from three complementary, volume-aware components that target different facets of order flow:
Flow Pressure (FP) — In-bar directional drive scaled by relative volume.
Drive
=
close
−
open
max
(
high
−
low
,
tick
)
∈
=
max(high−low, tick)
close−open
∈ .
Relative Volume
=
volume
average volume over
𝑓
𝑝
𝐿
𝑒
𝑛
=
average volume over fpLen
volume
.
𝐹
𝑃
𝑟
𝑎
𝑤
=
Drive
×
RelVol
FP
raw
=Drive×RelVol then squashed (softsign) to
.
Why it belongs: distinguishes real pushes (big body and big volume) from noise.
Rolling VWAP Drift — Direction of VWAP itself over a rolling window, normalized by ATR.
𝑉
𝑊
𝐴
𝑃
𝑡
=
∑
(
𝑇
𝑃
×
𝑉
𝑜
𝑙
)
∑
𝑉
𝑜
𝑙
VWAP
t
=
∑Vol
∑(TP×Vol)
over vwapLen.
Drift
=
𝑉
𝑊
𝐴
𝑃
𝑡
−
𝑉
𝑊
𝐴
𝑃
𝑡
−
1
𝐴
𝑇
𝑅
=
ATR
VWAP
t
−VWAP
t−1
→ squashed to
.
Why it belongs: persistent VWAP movement signals sustained accumulation/distribution.
PVT Momentum — Price-Volume Trend standardized (z-score) and squashed.
𝑃
𝑉
𝑇
𝑡
=
𝑃
𝑉
𝑇
𝑡
−
1
+
𝑉
𝑜
𝑙
×
Δ
𝐶
𝑙
𝑜
𝑠
𝑒
𝐶
𝑙
𝑜
𝑠
𝑒
𝑡
−
1
PVT
t
=PVT
t−1
+Vol×
Close
t−1
ΔClose
.
𝑧
=
𝑃
𝑉
𝑇
−
SMA
(
𝑃
𝑉
𝑇
)
StDev
(
𝑃
𝑉
𝑇
)
z=
StDev(PVT)
PVT−SMA(PVT)
→ squashed to
.
Why it belongs: captures volume-weighted trend pressure without relying on price alone.
Composite score:
Score
=
𝑤
𝐹
𝑃
⋅
𝐹
𝑃
+
𝑤
𝑉
𝑊
𝐴
𝑃
⋅
𝑉
𝑊
𝐴
𝑃
_
𝐷
𝑟
𝑖
𝑓
𝑡
+
𝑤
𝑃
𝑉
𝑇
⋅
𝑃
𝑉
𝑇
_
𝑀
𝑜
𝑚
𝑤
𝐹
𝑃
+
𝑤
𝑉
𝑊
𝐴
𝑃
+
𝑤
𝑃
𝑉
𝑇
Score=
w
FP
+w
VWAP
+w
PVT
w
FP
⋅FP+w
VWAP
⋅VWAP_Drift+w
PVT
⋅PVT_Mom
with a Signal = SMA(Score, sigLen). Thresholds mark strong accumulation/distribution zones.
How it works (step-by-step)
Compute FP, VWAP Drift, PVT Momentum.
Normalize each to the same
scale.
Weighted average → FlowFusion Score.
Smooth with a Signal line to reduce whipsaw.
Optional background shading when Score exceeds thresholds.
How to use
Direction filter:
Score > 0 favors longs; Score < 0 favors shorts.
Momentum turns:
Score crosses above Signal → setup for long; below → setup for short.
Strength zones:
Above Upper Threshold (default +40) = strong buy pressure; below Lower (−40) = strong sell pressure.
Confluence:
Best near S/R, trendlines, or HTF bias. For scalping on 1–5m, consider sigLen 9–13 and thresholds ±40 to ±50.
Alerts included: zero cross, zone entries, and Score/Signal crossovers.
Inputs (key)
fpLen (20): relative-volume lookback for Flow Pressure.
vwapLen (34): rolling VWAP window.
pvtLen (50): PVT z-score window.
sigLen (9): Signal smoothing.
Weights: wFP, wVWAP, wPVT to bias the blend.
Thresholds: upperBand / lowerBand (defaults +40/−40).
Display: toggle component plots and background shading.
Best practices
Trending markets: increase wVWAP (VWAP Drift) or widen thresholds.
Ranging markets: increase wFP and wPVT; take quicker profits.
News: wait for bar close confirmation or reduce size.
Data quality: use consistent volume feeds (especially in crypto).
Limitations
Oscillators can stay extreme in strong trends; use structure/trend filters.
Volume anomalies (illiquid pairs, API glitches) can distort signals—sanity-check with another venue when possible.
Disclaimer
This indicator is for educational purposes only and is not financial advice. Trading involves risk; past performance does not guarantee future results. Always paper-trade first and use appropriate risk controls.
Cheat CodeWhy Monday & Friday
Monday evening (NY): frequently seeds the weekly expansion. Its DR/IDR often acts as a weekly “starter envelope,” useful for breakout continuation or fade back into the box plays as liquidity builds.
Friday evening (NY): often exposes end-of-week traps (run on stops into the close) and sets expectation boundaries into the following week. Carry these levels forward to catch Monday’s reaction to Friday’s closing structure.
Typical use-cases
Breakout & retest:
Price closes outside the Monday DR/IDR → look for retests of the band edge for continuation.
Liquidity sweep (“trap”) recognition:
Friday session wicks briefly beyond Friday DR/IDR then closes back inside → watch for mean reversion early next week.
Bias filter:
Above both Monday DR midline and Friday DR midline → bias long until proven otherwise; the inverse for shorts.
Session open confluence:
Reactions at the open line frequently mark decision points for momentum vs. fade setups.
(This is a levels framework, not a signals engine. Combine with your execution model: orderflow, S/R, session timing, or higher-TF bias.)
Inputs & styling (quick reference)
Display toggles (per day):
Show DR / IDR / Middle DR / Middle IDR
Show Opening Line
Show DR/IDR Box (choose DR or IDR as box source)
Show Price Labels
Style controls (per day):
Line width (1–4), style (Solid/Dashed/Dotted)
Independent colors for DR, IDR, midlines, open line
Box background opacity
Timezone:
Default America/New_York (changeable).
Optional on-chart warning if your chart TZ differs.
Practical notes
Works on intraday charts; levels are anchored using weekly timestamps for accuracy on any symbol.
Live updating: During the Mon/Fri calc windows, DR/IDR highs/lows and midlines keep updating until the session ends.
Clean drawings: Lines, box, and labels are created once per session and then extended/updated—efficient on resources even with long display windows.
Max elements: Script reserves ample line/box/label capacity for stability across weeks.