This is an experimental study designed to calculate polynomial regression for any order polynomial that TV is able to support.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
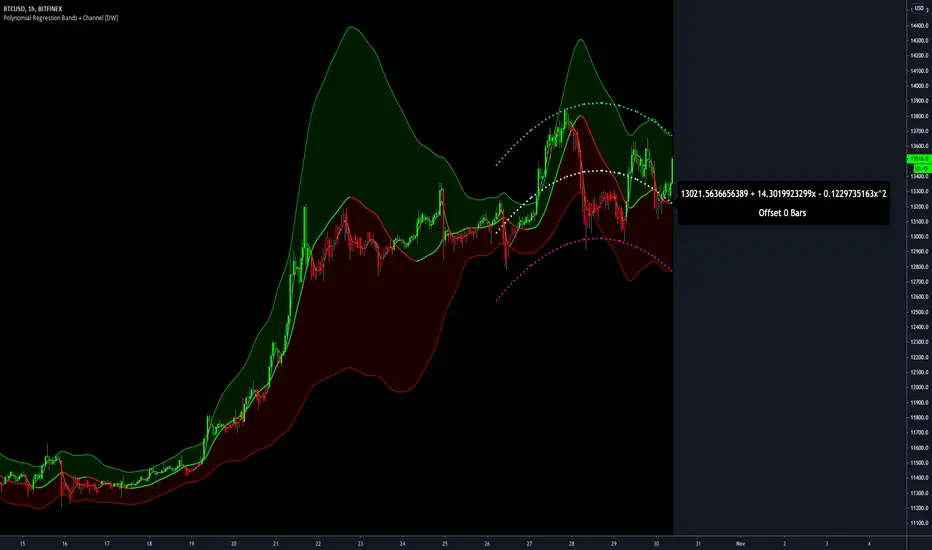
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
This study aims to educate users on polynomial curve fitting, and the derivation process of Least Squares Moving Averages (LSMAs).
I also designed this study with the intent of showcasing some of the capabilities and potential applications of TV's fantastic new array functions.
Polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as a polynomial of nth degree (order).
For clarification, linear regression can also be described as a first order polynomial regression. The process of deriving linear, quadratic, cubic, and higher order polynomial relationships is all the same.
In addition, although deriving a polynomial regression equation results in a nonlinear output, the process of solving for polynomials by least squares is actually a special case of multiple linear regression.
So, just like in multiple linear regression, polynomial regression can be solved in essentially the same way through a system of linear equations.
In this study, you are first given the option to smooth the input data using the 2 pole Super Smoother Filter from John Ehlers.
I chose this specific filter because I find it provides superior smoothing with low lag and fairly clean cutoff. You can, of course, implement your own filter functions to see how they compare if you feel like experimenting.
Filtering noise prior to regression calculation can be useful for providing a more stable estimation since least squares regression can be rather sensitive to noise.
This is especially true on lower sampling lengths and higher degree polynomials since the regression output becomes more "overfit" to the sample data.
Next, data arrays are populated for the x-axis and y-axis values. These are the main datasets utilized in the rest of the calculations.
To keep the calculations more numerically stable for higher periods and orders, the x array is filled with integers 1 through the sampling period rather than using current bar numbers.
This process can be thought of as shifting the origin of the x-axis as new data emerges.
This keeps the axis values significantly lower than the 10k+ bar values, thus maintaining more numerical stability at higher orders and sample lengths.
The data arrays are then used to create a pseudo 2D matrix of x power sums, and a vector of x power*y sums.
These matrices are a representation the system of equations that need to be solved in order to find the regression coefficients.
Below, you'll see some examples of the pattern of equations used to solve for our coefficients represented in augmented matrix form.
For example, the augmented matrix for the system equations required to solve a second order (quadratic) polynomial regression by least squares is formed like this:
(∑x^0 ∑x^1 ∑x^2 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 | ∑(x^2)y)
The augmented matrix for the third order (cubic) system is formed like this:
(∑x^0 ∑x^1 ∑x^2 ∑x^3 | ∑(x^0)y)
(∑x^1 ∑x^2 ∑x^3 ∑x^4 | ∑(x^1)y)
(∑x^2 ∑x^3 ∑x^4 ∑x^5 | ∑(x^2)y)
(∑x^3 ∑x^4 ∑x^5 ∑x^6 | ∑(x^3)y)
This pattern continues for any n ordered polynomial regression, in which the coefficient matrix is a n + 1 wide square matrix with the last term being ∑x^2n, and the last term of the result vector being ∑(x^n)y.
Thanks to this pattern, it's rather convenient to solve the for our regression coefficients of any nth degree polynomial by a number of different methods.
In this script, I utilize a process known as LU Decomposition to solve for the regression coefficients.
Lower-upper (LU) Decomposition is a neat form of matrix manipulation that expresses a 2D matrix as the product of lower and upper triangular matrices.
This decomposition method is incredibly handy for solving systems of equations, calculating determinants, and inverting matrices.
For a linear system Ax=b, where A is our coefficient matrix, x is our vector of unknowns, and b is our vector of results, LU Decomposition turns our system into LUx=b.
We can then factor this into two separate matrix equations and solve the system using these two simple steps:
1. Solve Ly=b for y, where y is a new vector of unknowns that satisfies the equation, using forward substitution.
2. Solve Ux=y for x using backward substitution. This gives us the values of our original unknowns - in this case, the coefficients for our regression equation.
After solving for the regression coefficients, the values are then plugged into our regression equation:
Y = a0 + a1*x + a1*x^2 + ... + an*x^n, where a() is the ()th coefficient in ascending order and n is the polynomial degree.
From here, an array of curve values for the period based on the current equation is populated, and standard deviation is added to and subtracted from the equation to calculate the channel high and low levels.
The calculated curve values can also be shifted to the left or right using the "Regression Offset" input
Changing the offset parameter will move the curve left for negative values, and right for positive values.
This offset parameter shifts the curve points within our window while using the same equation, allowing you to use offset datapoints on the regression curve to calculate the LSMA and bands.
The curve and channel's appearance is optionally approximated using Pine's v4 line tools to draw segments.
Since there is a limitation on how many lines can be displayed per script, each curve consists of 10 segments with lengths determined by a user defined step size. In total, there are 30 lines displayed at once when active.
By default, the step size is 10, meaning each segment is 10 bars long. This is because the default sampling period is 100, so this step size will show the approximate curve for the entire period.
When adjusting your sampling period, be sure to adjust your step size accordingly when curve drawing is active if you want to see the full approximate curve for the period.
Note that when you have a larger step size, you will see more seemingly "sharp" turning points on the polynomial curve, especially on higher degree polynomials.
The polynomial functions that are calculated are continuous and differentiable across all points. The perceived sharpness is simply due to our limitation on available lines to draw them.
The approximate channel drawings also come equipped with style inputs, so you can control the type, color, and width of the regression, channel high, and channel low curves.
I also included an input to determine if the curves are updated continuously, or only upon the closing of a bar for reduced runtime demands. More about why this is important in the notes below.
For additional reference, I also included the option to display the current regression equation.
This allows you to easily track the polynomial function you're using, and to confirm that the polynomial is properly supported within Pine.
There are some cases that aren't supported properly due to Pine's limitations. More about this in the notes on the bottom.
In addition, I included a line of text beneath the equation to indicate how many bars left or right the calculated curve data is currently shifted.
The display label comes equipped with style editing inputs, so you can control the size, background color, and text color of the equation display.
The Polynomial LSMA, high band, and low band in this script are generated by tracking the current endpoints of the regression, channel high, and channel low curves respectively.
The output of these bands is similar in nature to Bollinger Bands, but with an obviously different derivation process.
By displaying the LSMA and bands in tandem with the polynomial channel, it's easy to visualize how LSMAs are derived, and how the process that goes into them is drastically different from a typical moving average.
The main difference between LSMA and other MAs is that LSMA is showing the value of the regression curve on the current bar, which is the result of a modelled relationship between x and the expected value of y.
With other MA / filter types, they are typically just averaging or frequency filtering the samples. This is an important distinction in interpretation. However, both can be applied similarly when trading.
An important distinction with the LSMA in this script is that since we can model higher degree polynomial relationships, the LSMA here is not limited to only linear as it is in TV's built in LSMA.
Bar colors are also included in this script. The color scheme is based on disparity between source and the LSMA.
This script is a great study for educating yourself on the process that goes into polynomial regression, as well as one of the many processes computers utilize to solve systems of equations.
Also, the Polynomial LSMA and bands are great components to try implementing into your own analysis setup.
I hope you all enjoy it!
--------------------------------------------------------
NOTES:
- Even though the algorithm used in this script can be implemented to find any order polynomial relationship, TV has a limit on the significant figures for its floating point outputs.
This means that as you increase your sampling period and / or polynomial order, some higher order coefficients will be output as 0 due to floating point round-off.
There is currently no viable workaround for this issue since there isn't a way to calculate more significant figures than the limit.
However, in my humble opinion, fitting a polynomial higher than cubic to most time series data is "overkill" due to bias-variance tradeoff.
Although, this tradeoff is also dependent on the sampling period. Keep that in mind. A good rule of thumb is to aim for a nice "middle ground" between bias and variance.
If TV ever chooses to expand its significant figure limits, then it will be possible to accurately calculate even higher order polynomials and periods if you feel the desire to do so.
To test if your polynomial is properly supported within Pine's constraints, check the equation label.
If you see a coefficient value of 0 in front of any of the x values, reduce your period and / or polynomial order.
- Although this algorithm has less computational complexity than most other linear system solving methods, this script itself can still be rather demanding on runtime resources - especially when drawing the curves.
In the event you find your current configuration is throwing back an error saying that the calculation takes too long, there are a few things you can try:
-> Refresh your chart or hide and unhide the indicator.
The runtime environment on TV is very dynamic and the allocation of available memory varies with collective server usage.
By refreshing, you can often get it to process since you're basically just waiting for your allotment to increase. This method works well in a lot of cases.
-> Change the curve update frequency to "Close Only".
If you've tried refreshing multiple times and still have the error, your configuration may simply be too demanding of resources.
v4 drawing objects, most notably lines, can be highly taxing on the servers. That's why Pine has a limit on how many can be displayed in the first place.
By limiting the curve updates to only bar closes, this will significantly reduce the runtime needs of the lines since they will only be calculated once per bar.
Note that doing this will only limit the visual output of the curve segments. It has no impact on regression calculation, equation display, or LSMA and band displays.
-> Uncheck the display boxes for the drawing objects.
If you still have troubles after trying the above options, then simply stop displaying the curve - unless it's important to you.
As I mentioned, v4 drawing objects can be rather resource intensive. So a simple fix that often works when other things fail is to just stop them from being displayed.
-> Reduce sampling period, polynomial order, or curve drawing step size.
If you're having runtime errors and don't want to sacrifice the curve drawings, then you'll need to reduce the calculation complexity.
If you're using a large sampling period, or high order polynomial, the operational complexity becomes significantly higher than lower periods and orders.
When you have larger step sizes, more historical referencing is used for x-axis locations, which does have an impact as well.
By reducing these parameters, the runtime issue will often be solved.
Another important detail to note with this is that you may have configurations that work just fine in real time, but struggle to load properly in replay mode.
This is because the replay framework also requires its own allotment of runtime, so that must be taken into consideration as well.
- Please note that the line and label objects are reprinted as new data emerges. That's simply the nature of drawing objects vs standard plots.
I do not recommend or endorse basing your trading decisions based on the drawn curve. That component is merely to serve as a visual reference of the current polynomial relationship.
No repainting occurs with the Polynomial LSMA and bands though. Once the bar is closed, that bar's calculated values are set.
So when using the LSMA and bands for trading purposes, you can rest easy knowing that history won't change on you when you come back to view them.
- For those who intend on utilizing or modifying the functions and calculations in this script for their own scripts, I included debug dialogues in the script for all of the arrays to make the process easier.
To use the debugs, see the "Debugs" section at the bottom. All dialogues are commented out by default.
The debugs are displayed using label objects. By default, I have them all located to the right of current price.
If you wish to display multiple debugs at once, it will be up to you to decide on display locations at your leisure.
When using the debugs, I recommend commenting out the other drawing objects (or even all plots) in the script to prevent runtime issues and overlapping displays.
Note di rilascio
Updates:-> Added a toggle switch to automatically decide the drawing step size. This option will automatically calculate the step size required to show a curve for the full period.
This parameter is enabled by default. If you wish to still manually decide step size, simply uncheck the box.
-> Corrected a small offset issue in the curve value array.
-> Added a new forecasting parameter. With this, the script is now able to output extrapolated (forecasted) current bar values using the equation from some user defined bars back.
When forecast bars are greater than 0, the output Polynomial LSMA and bands reflect a trail of forecasted expected values from a previous fit rather than the current fitted values.
The equation label is updated with a line of text displaying how many bars ago the forecast is from when forecasting is active, and the calculated regression equation from those bars ago is displayed for easy reference.
This enables greater avenues of analysis possibilities, as you can now test and fine tune your configuration's ability to forecast future values.
Notes on using forecasting methods:
Please note that no specific claims are being made in regards to this script's predictive capabilities.
Because of the stochastic nature of economic data and general lack of deep market information, forecasting future values reliably is a difficult and highly debated topic.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Using higher forecast sizes will often result in higher variance and inaccuracy in many cases - especially with higher order polynomials and small sample sized due to bias-variance tradeoff.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently, forecast models may prove to be potentially beneficial components to incorporate in your analysis.
Note di rilascio
Updates:-> The fitted curve, channel high, and channel low now have separate display toggles so you can choose which channel levels you want to display.
-> The polynomial LSMA is now colorized based on its value relative to the previous value.
Script open-source
Nello spirito di TradingView, l'autore di questo script lo ha reso open source, in modo che i trader possano esaminarne e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricordiamo che la ripubblicazione del codice è soggetta al nostro Regolamento.
For my full list of premium tools, check the blog:
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
Declinazione di responsabilità
Le informazioni e le pubblicazioni non sono intese come, e non costituiscono, consulenza o raccomandazioni finanziarie, di investimento, di trading o di altro tipo fornite o approvate da TradingView. Per ulteriori informazioni, consultare i Termini di utilizzo.
Script open-source
Nello spirito di TradingView, l'autore di questo script lo ha reso open source, in modo che i trader possano esaminarne e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricordiamo che la ripubblicazione del codice è soggetta al nostro Regolamento.
For my full list of premium tools, check the blog:
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
wallanalytics.com/
Reach out on Telegram:
t.me/DonovanWall
Declinazione di responsabilità
Le informazioni e le pubblicazioni non sono intese come, e non costituiscono, consulenza o raccomandazioni finanziarie, di investimento, di trading o di altro tipo fornite o approvate da TradingView. Per ulteriori informazioni, consultare i Termini di utilizzo.