This is SPTS.
It stands for Statistical Package for the Trading Sciences.
Its a play on SPSS (Statistical Package for the Social Sciences) by IBM (software that, prior to Pinescript, I would use on a daily basis for trading).
Let's preface this indicator first:
This isn't so much an indicator as it is a project. A passion project really.
This has been in the works for months and I still feel like its incomplete. But the plan here is to continue to add functionality to it and actually have the Pinecoding and Tradingview community contribute to it.
As a math based trader, I relied on Excel, SPSS and R constantly to plan my trades. Since learning a functional amount of Pinescript and coding a lot of what I do and what I relied on SPSS, Excel and R for, I use it perhaps maybe a few times a week.
This indicator, or package, has some of the key things I used Excel and SPSS for on a daily and weekly basis. This also adds a lot of, I would say, fairly complex math functionality to Pinescript. Because this is adding functionality not necessarily native to Pinescript, I have placed most, if not all, of the functionality into actual exportable functions. I have also set it up as a kind of library, with explanations and tips on how other coders can take these functions and implement them into other scripts.
The hope here is that other coders will take it, build upon it, improve it and hopefully share additional functionality that can be added into this package. Hence why I call it a project. Okay, let's get into an overview:
Current Functions of SPTS:
SPTS currently has the following functionality (further explanations will be offered below):
- Ability to Perform a One-Tailed, Two-Tailed and Paired Sample T-Test, with corresponding P value.
- Standard Pearson Correlation (with functionality to be able to calculate the Pearson Correlation between 2 arrays).
- Quadratic (or Curvlinear) correlation assessments.
- R squared Assessments.
- Standard Linear Regression.
- Multiple Regression of 2 independent variables.
- Tests of Normality (with Kurtosis and Skewness) and recognition of up to 7 Different Distributions.
- ARIMA Modeller (Sort of, more details below)
Okay, so let's go over each of them!
T-Tests
So traditionally, most correlation assessments on Pinescript are done with a generic Pearson Correlation using the "ta.correlation" argument. However, this is not always the best test to be used for correlations and determine effects. One approach to correlation assessments used frequently in economics is the T-Test assessment.
The t-test is a statistical hypothesis test used to determine if there is a significant difference between the means of two groups. It assesses whether the sample means are likely to have come from populations with the same mean. The test produces a t-statistic, which is then compared to a critical value from the t-distribution to determine statistical significance. Lower p-values indicate stronger evidence against the null hypothesis of equal means.
A significant t-test result, indicating the rejection of the null hypothesis, suggests that there is statistical evidence to support that there is a significant difference between the means of the two groups being compared. In practical terms, it means that the observed difference in sample means is unlikely to have occurred by random chance alone. Researchers typically interpret this as evidence that there is a real, meaningful difference between the groups being studied.
Some uses of the T-Test in finance include:
Risk Assessment: The t-test can be used to compare the risk profiles of different financial assets or portfolios. It helps investors assess whether the differences in returns or volatility are statistically significant.
Pairs Trading: Traders often apply the t-test when engaging in pairs trading, a strategy that involves trading two correlated securities. It helps determine when the price spread between the two assets is statistically significant and may revert to the mean.
Volatility Analysis: Traders and risk managers use t-tests to compare the volatility of different assets or portfolios, assessing whether one is significantly more or less volatile than another.
Market Efficiency Tests: Financial researchers use t-tests to test the Efficient Market Hypothesis by assessing whether stock price movements follow a random walk or if there are statistically significant deviations from it.
Value at Risk (VaR) Calculation: Risk managers use t-tests to calculate VaR, a measure of potential losses in a portfolio. It helps assess whether a portfolio's value is likely to fall below a certain threshold.
There are many other applications, but these are a few of the highlights. SPTS permits 3 different types of T-Test analyses, these being the One Tailed T-Test (if you want to test a single direction), two tailed T-Test (if you are unsure of which direction is significant) and a paired sample t-test.
Which T is the Right T?
Generally, a one-tailed t-test is used to determine if a sample mean is significantly greater than or less than a specified population mean, whereas a two-tailed t-test assesses if the sample mean is significantly different (either greater or less) from the population mean. In contrast, a paired sample t-test compares two sets of paired observations (e.g., before and after treatment) to assess if there's a significant difference in their means, typically used when the data points in each pair are related or dependent.
So which do you use? Well, it depends on what you want to know. As a general rule a one tailed t-test is sufficient and will help you pinpoint directionality of the relationship (that one ticker or economic indicator has a significant affect on another in a linear way).
A two tailed is more broad and looks for significance in either direction.
A paired sample t-test usually looks at identical groups to see if one group has a statistically different outcome. This is usually used in clinical trials to compare treatment interventions in identical groups. It's use in finance is somewhat limited, but it is invaluable when you want to compare equities that track the same thing (for example SPX vs SPY vs ES1!) or you want to test a hypothesis about an index and a leveraged share (for example, the relationship between FNGU and, say, MSFT or NVDA).
Statistical Significance
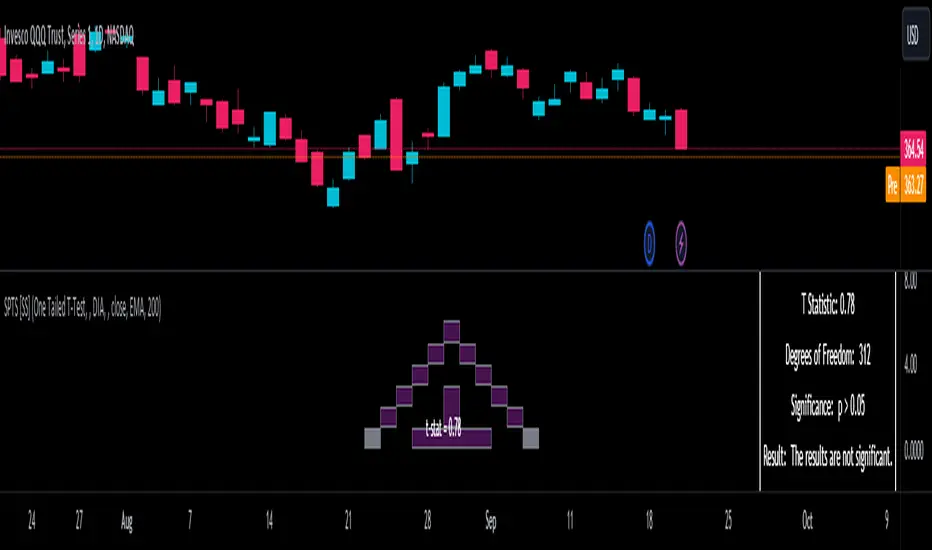
In general, with a t-test you would need to reference a T-Table to determine the statistical significance of the degree of Freedom and the T-Statistic.
However, because I wanted Pinescript to full fledge replace SPSS and Excel, I went ahead and threw the T-Table into an array, so that Pinescript can make the determination itself of the actual P value for a t-test, no cross referencing required :-).
Left tail (Significant):
Both tails (Significant):
Distributed throughout (insignificant):
As you can see in the images above, the t-test will also display a bell-curve analysis of where the significance falls (left tail, both tails or insignificant, distributed throughout).
That said, I have not included this function for the paired sample t-test because that is a bit more nuanced. But for the one and two tailed assessments, the indicator will provide you the P value.
Pearson Correlation Assessment
I don't think I need to go into too much detail on this one.
I have put in functionality to quickly calculate the Pearson Correlation of two array's, which is not currently possible with the "ta.correlation" function.
Quadratic (Curvlinear) Correlation
Not everything in life is linear, sometimes things are curved!
The Pearson Correlation is great for linear assessments, but tends to under-estimate the degree of the relationship in curved relationships. There currently is no native function to t-test for quadratic/curvlinear relationships, so I went ahead and created one.
You can see an example of how Quadratic and Pearson Correlations vary when you look at
Pearson Correlation:
Quadratic Correlation:
One or the other is not always the best, so it is important to check both!
R-Squared Assessments:
The R-squared value, or the square of the Pearson correlation coefficient (r), is used to measure the proportion of variance in one variable that can be explained by the linear relationship with another variable. It represents the goodness-of-fit of a linear regression model with a single predictor variable.
R-Squared is offered in 3 separate forms within this indicator. First, there is the generic R squared which is taking the square root of a Pearson Correlation assessment to assess the variance.
The next is the R-Squared which is calculated from an actual linear regression model done within the indicator.
The first is the R-Squared which is calculated from a multiple regression model done within the indicator.
Regardless of which R-Squared value you are using, the meaning is the same. R-Square assesses the variance between the variables under assessment and can offer an insight into the goodness of fit and the ability of the model to account for the degree of variance.
Here is the R Squared assessment of the SPX against the US Money Supply:
Standard Linear Regression
The indicator contains the ability to do a standard linear regression model. You can convert one ticker or economic indicator into a stock, ticker or other economic indicator. The indicator will provide you with all of the expected information from a linear regression model, including the coefficients, intercept, error assessments, correlation and R2 value.
Here is AAPL and MSFT as an example:
Multiple Regression
Oh man, this was something I really wanted in Pinescript, and now we have it!
I have created a function for multiple regression, which, if you export the function, will permit you to perform multiple regression on any variables available in Pinescript!
Using this functionality in the indicator, you will need to select 2, dependent variables and a single independent variable.
Here is an example of multiple regression for
And an example of SPX using the US Money Supply (M2) and
Tests of Normality:
Many indicators perform a lot of functions on the assumption of normality, yet there are no indicators that actually test that assumption!
So, I have inputted a function to assess for normality. It uses the Kurtosis and Skewness to determine up to 7 different distribution types and it will explain the implication of the distribution. Here is an example of
And
And NVDA since 2015:
ARIMA Modeller
Okay, so let me disclose, this isn't a full fledge ARIMA modeller. I took some shortcuts.
True ARIMA modelling would involve decomposing the seasonality from the trend. I omitted this step for simplicity sake. Instead, you can select between using an EMA or SMA based approach, and it will perform an autogressive type analysis on the EMA or SMA.
I have tested it on lookback with results provided by SPSS and this actually works better than SPSS' ARIMA function. So I am actually kind of impressed.
You will need to input your parameters for the ARIMA model, I usually would do a 14, 21 and 50 day EMA of the close price, and it will forecast out that range over the length of the EMA.
So for example, if you select the EMA 50 on the daily, it will plot out the forecast for the next 50 days based on an autoregressive model created on the EMA 50. Here is how it looks on
You can also elect to plot the upper and lower confidence bands:
Closing Remarks
So that is the indicator/package.
I do hope to continue expanding its functionality, but as of now, it does already have quite a lot of functionality.
I really hope you enjoy it and find it helpful. This. Has. Taken. AGES! No joke. Between referencing my old statistics textbooks, trying to remember how to calculate some of these things, and wanting to throw my computer against the wall because of errors in the code, this was a task, that's for sure. So I really hope you find some usefulness in it all and enjoy the ability to be able to do functions that previously could really only be done in external software.
As always, leave your comments, suggestions and feedback below!
Take care!
Note di rilascio
Quick fix.Note di rilascio
Updated some of the info for using the functions.Also realized I forgot to add a quadratic regression function. I gave the ability to perform a quadratic correlation but not the regression part. So this has been added.
To see an example, VIX and SPY have a very strong quadratic relationship.
Here is VIX via linear regression:
And here it is on Quadratic regression:
Notice the dramatic increase in the R2 and correlation as well as the reduction in the error range.
Note di rilascio
Label fixNote di rilascio
Bug fix. Note di rilascio
An autoregressive forecasting function has been added using the new SPTS library:This will create an autoregressive forecast for a desired number of look forwards (max is 25).
You will see new inputs at the bottom of the menu that pertain to the forecasting model, you can select the train time and the desired forecasting duration and it will plot the AR results for you.
The chart above shows the forecast for QQQ for the next 15 trading days.
Note di rilascio
Added the ability to do a 3 group ANOVA on 3 independent variables (in this case, 3 separate tickers). It gives you the F Statistic and the significance level (1, 0,10, 0,05, or 0,01).
Script open-source
In pieno spirito TradingView, il creatore di questo script lo ha reso open-source, in modo che i trader possano esaminarlo e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricorda che la ripubblicazione del codice è soggetta al nostro Regolamento.
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Declinazione di responsabilità
Le informazioni ed i contenuti pubblicati non costituiscono in alcun modo una sollecitazione ad investire o ad operare nei mercati finanziari. Non sono inoltre fornite o supportate da TradingView. Maggiori dettagli nelle Condizioni d'uso.
Script open-source
In pieno spirito TradingView, il creatore di questo script lo ha reso open-source, in modo che i trader possano esaminarlo e verificarne la funzionalità. Complimenti all'autore! Sebbene sia possibile utilizzarlo gratuitamente, ricorda che la ripubblicazione del codice è soggetta al nostro Regolamento.
Get:
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
- Live Updates,
- Discord access,
- Access to my Proprietary Merlin Software,
- Access to premium indicators,
patreon.com/steversteves
Declinazione di responsabilità
Le informazioni ed i contenuti pubblicati non costituiscono in alcun modo una sollecitazione ad investire o ad operare nei mercati finanziari. Non sono inoltre fornite o supportate da TradingView. Maggiori dettagli nelle Condizioni d'uso.