Coppie correlate
BNBUSDT - COLOSSO BNB PRONTO COME NEL 2020Ricordo la mitica patenza di bnb a gennaio 2021, possibile fotocopia del scenario 2021 con gennaio 2025, vediamo se bnb resta in lateral rialzista fino a gennaio per poi esplodere up!

Binance Coin breakout del triangolo simmetricoBinance Coin è tornato negli ultimi giorni sopra i 600$, livello attorno a cui ha scambiato per numerose settimane, dopo aver corretto dal massimo annuale di Marzo a 645$. Al momento di questa analisi sta registrando un rialzo del 100% su base annuale, quadruplicando quello fatto nel 2023 che si era

BNB USDTBNB sembra aver imboccato un bel canalone rialzista. Prossimo target area 1000$.
Il programma di staking che remunera i detentori tramite una percentuale di BNB, addizionato all'airdrip di nuove criptovalute lanciate su Launchpool/Launchpad sembri sosstenere questa direzione.
Stiamo a vedere..
DISC

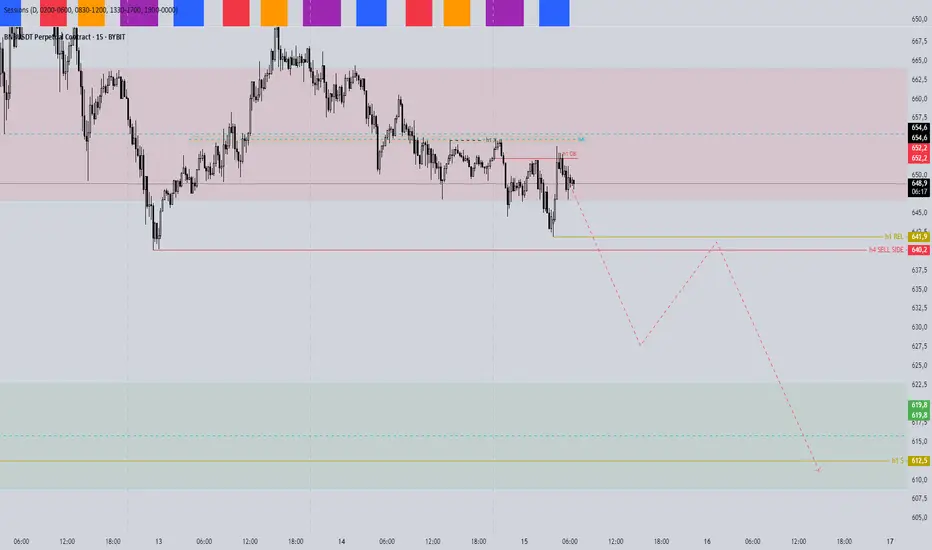
LONG BNB/USDTEntrata LONG a mercato con target 580
Dopo Rottura trend line il ri-test sembra confermare la tenuta del prezzo al di sopra.
Posizione long con obiettivo al di sotto della prossima resistenza e stop al di sotto del primo supporto

Ronzimport pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Load historical OHLCV data
data = pd.read_csv('historical_data.csv')

BNB BINANCE COIN - BITCOINSalve,
condivido con voi un'altra coin che ho nel portafoglio, BNB.
Bnb rimasta sedentaria per molto tempo, ha performato molto bene negli ultimi 3 mesi, regalandoci un buon +60% di gain.
Al momento si trova in area resistiva zona 420$ circa.
Molto ampio il range tra resistenza e supporto per Bnb,

5mins strategy //@version=4
strategy("5-Minute Chart Strategy", overlay=true)
// Input parameters
rsiLength = input(14, title="RSI Length")
overbought = input(70, title="Overbought Level")
oversold = input(30, title="Oversold Level")
emaLength = input(20, title="EMA Length")
// Calculate RSI
rsi = rsi(close, rsi

Il rimbalzo di BNB si sta fermando alla resistenza 260$BNB dopo aver fatto base in area 200$ ha fatto il suo allungo rialzista, andando la settimana scorsa a rompere la resistenza a 230$ e lanciandosi verso la successiva in area 260$. Due giorni fa ha fatto un massimo a 257$ per poi iniziare a ritracciare. Un break out di 260$ ci darebbe un buon segnale

BNB: RIMBORSO PossibileBNB: RIMBORSO Possibile
Monitorare :
PRZ
EMA.50 e EMA.200
Livelli Fibonacci e ICHIMOKU

Vedi tutte le idee
Riassumere ciò che gli indicatori suggeriscono.
Oscillatori
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Oscillatori
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Sommario
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Sommario
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Sommario
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Medie mobili
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Medie mobili
Neutro
VendiCompra
Vendi adessoCompra adesso
Vendi adessoVendiNeutroCompraCompra adesso
Visualizza i movimenti di prezzo di un simbolo negli anni precedenti per identificare le tendenze ricorrenti.
Elenco delle watchlist curate in cui è presente BNBUSDT.


Domande frequenti
Il prezzo attuale di Binance Coin / TetherUS (BNB) è 681,75 USDT — è sceso del −0,55% nelle ultime 24 ore. Prova a inserire queste informazioni nel contesto controllando quali monete stanno guadagnando e perdendo al momento e vedendo il grafico dei prezzi di BNB.
Il prezzo di Binance Coin / TetherUS è aumentato del 3,78% nell'ultima settimana, la sua performance mensile mostra un aumento del 5,01%, e nell'ultimo anno, Binance Coin / TetherUS è aumentato del 25,11%. Vedi ulteriori dinamiche sul grafico dei prezzi di BNB.
Tieni traccia delle variazioni delle monete con la nostra Heatmap cripto.
Tieni traccia delle variazioni delle monete con la nostra Heatmap cripto.
Binance Coin / TetherUS (BNB) ha raggiunto il suo massimo storico il 4 dic 2024 — pari a 793,86 USDT. Ulteriori approfondimenti sul grafico del prezzo BNB.
Vedi l'elenco delle criptovalute in guadagno e scegli quello che meglio si adatta alla tua strategia.
Vedi l'elenco delle criptovalute in guadagno e scegli quello che meglio si adatta alla tua strategia.
Binance Coin / TetherUS (BNB) ha raggiunto il prezzo più basso di 0,50 USDT il 6 nov 2017. Visualizza altre dinamiche per Binance Coin / TetherUS sul grafico del prezzo.
Vedi l'elenco delle criptovalute che stanno perdendo per trovare opportunità inaspettate.
Vedi l'elenco delle criptovalute che stanno perdendo per trovare opportunità inaspettate.
La scelta più sicura quando si acquista BNB è quella di rivolgersi a un noto exchange di criptovalute. Alcuni dei nomi più popolari sono Binance, Coinbase, Kraken. Ma prima devi trovare un broker affidabile e creare un conto. È possibile fare trading su BNB direttamente dai grafici di TradingView—- basta scegliere un broker e collegarsi al proprio conto.
I mercati delle criptovalute sono famosi per la loro volatilità, pertanto è necessario studiare tutte le statistiche disponibili prima di aggiungere asset cripto al proprio portafoglio. Molto spesso è l'analisi tecnica a tornarci utile. Abbiamo preparato valutazioni tecniche per Binance Coin / TetherUS (BNB): oggi l'analisi tecnica relativa mostra un segnale di acquisto, e secondo la valutazione a 1 settimana BNB mostra un segnale di acquisto. Inoltre, è meglio scavare più a fondo e studiare anche la valutazione a 1 mese — è compra adesso. Trova ispirazione nelle idee di trading di Binance Coin / TetherUS e tieni traccia di ciò che sta muovendo i mercati cripto con il nostro feed di notizie sulle criptovalute.
Puoi discutere di Binance Coin / TetherUS (BNB) con altri utenti nelle nostre chat pubbliche, nei pensieri o nei commenti alle idee.