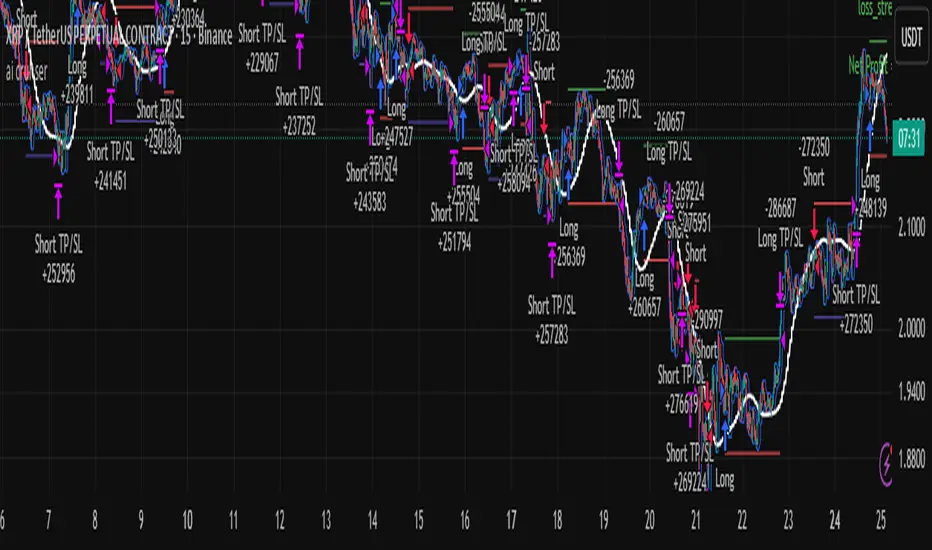
Manus Forex Alpha Pro Indicator (Trend-Momentum Hybrid)ใช้ AI Manus ช่วยผสมผสานให้ ใช้งานง่ายดี
น่าจะไม่ต้องอธิบายนะครับ เพราะเป็นพื้นฐานการใช้งาน
เพียงแต่มี แดชบอร์ด ช่วยให้อ่านง่ายขึ้น
การลงทุนมีความเสี่ยง ไม่มีเครื่องมือใดคาดการณ์ถูกต้อง 100%
เรียนรู้ ฝึกฝน มีวินัย ควบคุมความเสี่ยง ด้วยตนเอง
Using AI Manus helps integrate it, making it easy to use.
I don't think I need to explain this, as it's basic usage.
The dashboard simply makes it easier to read.
Investing involves risk; no tool is 100% accurate.
Learn, practice, be disciplined, and manage your own risk.
Indicatore Pine Script®